Dati strutturati
Introduzione
Questo è il secondo anno in cui il Web Almanac include un capitolo sui dati strutturati. Il contenuto dell’anno scorso ha fornito una solida base sul concetto di dati strutturati, tratteggiando il motivo per cui esiste, i tipi di dati strutturati utilizzati più di frequente e i vantaggi per le organizzazioni. Quest’anno abbiamo confrontato i dati raccolti nel 2022 con i dati precedenti dello scorso anno, così siamo stati in grado di monitorare le tendenze che hanno avuto luogo in tale periodo di tempo.
Nonostante i numerosi progressi nell’apprendimento automatico (machine learning) e in particolare nel campo del processamento del linguaggio naturale natural language processing, i dati devono ancora essere presentati in un formato leggibile dalle macchine. I dati strutturati aiutano nell’individuazione delle informazioni nelle ricerche web, aiutano nel collegamento dei dati fra loro e aiutano nell’archiviazione dei dati. Implementando i dati strutturati nei siti web, gli ingegneri e i creatori di contenuti web facilitano le seguenti operazioni:
- il rendere i dati dei siti web più ampiamente disponibili alla scoperta automatica e al collegamento
- la disponibilità dei dati aperta alla pubblica ricerca
- il garantire che la qualità dei dati dell’organizzazione sia mantenuta quando i dati lasciano la loro origine
Le organizzazioni di ogni dimensione e tipo desiderano che i propri contenuti vengano trovati sul web. I motori di ricerca come Google e Bing danno rilievo alla trovabilità dei dati promuovendo l’uso di dati strutturati. Da un punto di vista SEO, è vantaggioso presentare i dati in modo facile da trovare e analizzare (parse). Alcuni di questi vantaggi saranno discussi nelle sezioni casi d’uso e concetti chiave all’interno di questo capitolo.
L’introduzione dell’anno scorso ha sottolineato che “quando le macchine possono estrarre dati strutturati in modo affidabile, su larga scala questo significa che si abilitano nuovi e più intelligenti tipi di software, di sistemi, di servizi e di business”. Il capitolo di quest’anno include sezioni che esplorano la ricerche pubblicate di recente sui dati strutturati, i framework open source e gli strumenti che aiutano la generazione di dati strutturati di alta qualità.
Quest’anno forniamo il primo confronto anno su anno di metriche come la presenza di diversi tipi di dati strutturati e anche l’aumento di tali tipi di dati strutturati, ed infine esaminiamo i crescenti vantaggi dell’utilizzo di dati strutturati. Avere una base di dati dal 2021 ci consente di ottenere informazioni su come è cambiato l’uso dei dati strutturati nel periodo intercorso e di osservare tendenze interessanti, ad esempio la crescita di TikTok nel periodo.
Avvertenze sui dati
I dati strutturati possono comparire in molte forme e possono essere più visibili in alcuni settori e nei relativi siti web rispetto ad altri settori. Ad esempio, si confronti un sito web di news con un sito web di e-commerce. In generale un sito di news mostra le ultime notizie più importanti nella sua home page, pertanto i dati strutturati relativi agli articoli di news possono essere presenti nella principale landing page del sito allegati come data-snippet ai titoli di ciascun articolo. In confronto, i dati strutturati nell’e-commerce riguardano i singoli prodotti e, come tali, sono per lo più presenti all’interno del solo catalogo prodotti del sito web e, per molti versi, risultano “nascosti” durante una ricerca di alto livello nella navigazione principale e nelle parti promozionali del sito web. Questo è l’avvertimento chiave di cui dobbiamo essere consapevoli in relazione a questo capitolo e al report sui dati strutturati.
Poiché la tecnologia qui utilizzata per raccogliere i dati dai siti web scalfisce appena la superficie dei siti (vale a dire le home page) e non va in profondità con una scansione completa dei siti, non siamo in grado di ottenere un quadro completo dell’estensione di utilizzo dei dati strutturati nei siti in cui tali dati sono necessariamente contenuti in profondità all’interno del sito. Nei prossimi anni ci auguriamo di prendere un campione di siti in diversi ambiti e di andare in profondità per correggere questo problema e fornire ulteriori informazioni sull’uso specifico dei dati strutturati in ciascun ambito.
Valgono anche quest’anno gli avvertimenti generali dello scorso anno per il capitolo, vale a dire:
-
Dati strutturati generati automaticamente: il che avviene quando tecnologie come i sistemi di creazione di contenuti generano automaticamente snippet di dati strutturati basati su modelli. In questo caso qualsiasi errore basato su modello andrà inevitabilmente a scrivere in tutti i dati presentati.
-
Sovrapposizione dei formati di dati: i dati strutturati possono essere presentati in diversi modi, tra cui JSON-LD, RDF ecc. Ciò significa che potremmo avere delle sovrapposizioni, ad esempio, tra un meta tag di Facebook e lo stesso tag presentato in modo diverso nella sezione RDFa. Poiché l’analisi è strettamente basata sulle query create per la valutazione dei dati del 2021, ci aspettiamo che l’impatto della pulizia/normalizzazione e appiattimento dei dati ci porti ad un risultato comparabile.
Concetti chiave
Poiché i dati strutturati sono un’area ricca e complessa, è importante esplorare e spiegare alcuni concetti chiave dell’argomento prima di tuffarsi a capofitto in ulteriori analisi.
Linked data
Aggiungendo dati strutturati alle pagine web e fornendo collegamenti URI alle entità contenute o richiamate dalle pagine, creiamo i cosiddetti linked data. Questi dati strutturati vengono cioè interconnessi, rendendoli più utili se interrogati tramite query semantiche.
L’aggiunta di linked data per descrivere il contenuto della pagina web consente alle macchine di trattare le pagine web come database. Su larga scala, questo contribuisce al web semantico. Il web semantico collega i dati fra loro attraverso il Resource Description Framework (RDF). Si tratta di un framework per rappresentare le informazioni sul web che utilizza gli URI per definire le entità e le relazioni tra di esse.
Una relazione tra entità nel modello di dati RDF è nota come tripla semantica. Con una tripla semantica (o semplicemente tripla), possiamo codificare un’affermazione (statement) sui dati . Queste espressioni seguono la forma di soggetto-predicato-oggetto (ad esempio “Allen conosce John”).
Per essere in grado di recuperare e manipolare i dati RDF, possiamo utilizzare un linguaggio di interrgazione RDF (RDF Query Language) come SPARQL, il linguaggio di query RDF standard.
Come verrà discusso in seguito, il web semantico crea molte opportunità per il business e la tecnologia.
Open data
I linked data possono anche essere open data, nel cui caso vengono denominati Linked Open Data. Gli open data, come suggerisce il nome, sono dati che sono apertamente accessibili a chiunque per qualsiasi scopo. Tali dati sono concessi in licenza con una licenza open.
Gli open data sono la prima delle 5 stelle degli open data, uno schema di implementazione suggerito da Tim Berners-Lee. Secondo il manuale sugli open data Open data handbook, per ottenere il punteggio massimo di cinque stelle, i dati devono (1) essere disponibili sul web con un licenza open, (2) essere sotto forma di dati strutturati, (3) essere in un formato di file non proprietario, (4) utilizzare gli URI come identificatori, (5) includere collegamenti ad altre fonti di dati (vedi Collegamento di dati).
Mentre i dati strutturati (structured data) sono indicati come la seconda stella nel piano degli open data a 5 stelle, i linked data dovrebbero soddisfare i requisiti per tutte le 5 stelle per gli open data.
Motori di ricerca semantici, risultati arricchiti e altro ancora
Un motore di ricerca semantico è un motore che esegue la ricerca semantica. Cosa diversa dalla ricerca lessicale in cui i motori di ricerca cercano corrispondenze esatte o simili a parole o stringhe di testo. La ricerca semantica mira a comprendere l’intento dell’utente e il contesto dei termini di ricerca al fine di migliorare l’accuratezza della ricerca. Un esempio potrebbe essere un’entità di dati strutturati di “attività locale: parrucchiere” rispetto a “TG Locks n Lashes”; quest’ultimo è un nome commerciale, e anche se contiene come parola chiave il nome creativo del parrucchiere, fa poco per aiutare il motore di ricerca a capire cosa fa quell’attività. Utilizzando dati strutturati, il sito web può aiutare il motore di ricerca a comprendere il contesto delle informazioni fornite e quindi consentire al motore di offrire risultati di ricerca migliori nel contesto della query posta dall’utente che fa la ricerca. Google e Bing sono ottimi esempi di motori di ricerca semantici.
Google utilizza tecnologie di ricerca semantica per offrire informazioni pertinenti dal Google Knowledge Graph che è una knowledge base utilizzata per servire i risultati della ricerca in un riquadro informativo. Questo riquadro è noto come knowledge panel e può comparire in molti risultati. Questo riquadro di conoscenza (knowledge box) può essere innescato o migliorato grazie ai dati strutturati.
Un altro risultato di ricerca reso possibile dai dati strutturati combinati con i linked data è il risultato arricchito. Questi tipi di risultati mostrano maggiori particolari nei risultati di ricerca e possono presentarsi sotto forma di eventi, domande frequenti (FAQ), istruzioni how-to, annunci di lavoro e molti altri. Implementare i dati strutturati per rendere le pagine web idonee per i risultati arricchitti potrebbe aumentare la percentuale di clic. L’immagine sottostante illustra come i dati strutturati con i dettagli aziendali per un Hair Studio consentano al motore di ricerca di estrarre e visualizzare facilmente informazioni sull’attività, evidenziandola e ottimizzando la SEO.
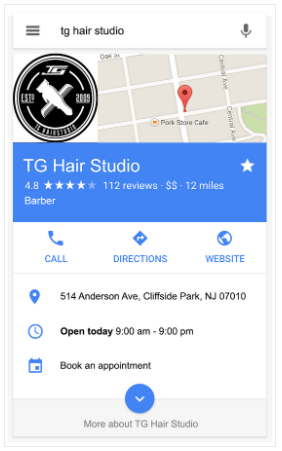
Oltre ai riquadri informativi e ai risultati arricchiti delle pagine web, i dati strutturati possono anche consentire risposte a quesiti fattuali nella ricerca. Una query di ricerca fattuale può ottenere più segnali da diverse fonti di dati strutturati e supportare risultati più precisi. In questo modo, l’implementazione di dati strutturati e le tecnologie che lo permettono, forniscono un accesso più rapido e affidabile alle informazioni al fine di migliorare l’esperienza utente.
La combinazione di importanza SEO, percentuali di clic più elevate, esperienza utente migliorata e dati leggibili dalle macchine resi accessibili per l’analisi rappresentano i vantaggi significativi dell’implementare i dati strutturati. La comprensione di questi concetti chiave aiuterà sia i fornitori di contenuti che il personale tecnico che costruisce i siti a capire come implementare una navigazione migliore e a comprendere la funzione del consumo automatizzato di dati ricavati da pagine web.
Ricerca sui dati strutturati
Per il capitolo di quest’anno eravamo interessati a capire quali ricerche accademiche, ammesso che ne esistano, siano state condotte nell’area dei dati strutturati, o se via sia prova di utilizzo di dati strutturati a complemento dello sviluppo di tecnologie e servizi all’avanguardia.
Per cercare ricerche pubblicate, abbiamo utilizzato strumenti di ricerca accademici come Google Scholar, ConnectedPapers e database di citazioni universitari. Non abbiamo ricercato solo pubblicazioni recenti, ma anche ricerche più datate che continuino ad essere citate.
I risultati della nostra ricerca hanno mostrato che non esistono molti lavori recenti, molto citati, condotti attorno alla generazione, gestione e costruzione di dati strutturati per il web. Tuttavia, della ricerca sull’applicazione di dati strutturati per il web (“The Semantic Web”), ad esempio grafi della conoscenza (knowledge graph), motori di raccomandazione (recommendation engine), recupero di informazioni (information retrieval), chatbot e intelligenza artificiale spiegabile (explainable AI), è stata condotta negli ultimi dodici mesi e continua ad aumentare.
I dati strutturati per il web condividono una relazione sinergica con il campo del machine learning fornendo dati coerenti con un vocabolario URI (Uniform Reference Indicator) appropriato che può essere utilizzato per generare etichette leggibili dalle macchine. Le nostre ricerche e letture di riferimento hanno dimostrato che i dati strutturati hanno notevolmente ridotto il lavoro e il tempo impiegato per generare dati web di alta qualità per l’addestramento di algoritmi di machine learning.
A livello pratico, evidenziamo tre aree che sono migliorate grazie ai dati strutturati:
- I grafi di conoscenza
- Il rispondere alle domande sui grafi di conoscenza
- L’IA spiegabile
Grafi di conoscenza
I dati strutturati per il web forniscono vocabolari fissi tra entità e oggetti come fossero un linguaggio specifico del dominio, tali vocabolari sono generalmente memorizzati in un formato RDF. I grafi della conoscenza che utilizzano RDF si sono dimostrati ottimi strumenti per interrogare le relazioni tra entità. Ad esempio, Wikidated 1.0 è un grafo della conoscenza in evoluzione che utilizza dati web strutturati per archiviare la cronologia delle revisioni di Wikipedia. Il suo documento corrispondente illustra il processo di aggregazione delle revisioni a una pagina come un insieme di aggiunte e cancellazioni della tupla RDF. Gli autori hanno reso open source il loro metodo per convertire i dump di wikipedia in grafi della conoscenza. La ricerca applicata condotta dalla Doordash Engineering dimostra che utilizzare i grafi della conoscenza può migliorare notevolmente le prestazioni di ricerca.
Rispondere alle domande sui grafi di conoscenza
I sistemi di risposta alle domande consentono agli utenti finali di trovare le risposte alle loro domande. Se costruito su un grafo della conoscenza, un sistema di risposta alle domande consente di accedere ai dati ricchi e strutturati memorizzati nei grafi di conoscenza. Linguaggi di interrogazione come SPARQL sono spesso usati per interrogare le informazioni memorizzate come triple RDF nei grafi della conoscenza.
Tuttavia, scrivere query SPARQL può essere noioso e impegnativo per gli utenti finali. Pertanto, le domande in linguaggio naturale (Natural Language Questions = NLQ) sono una soluzione interessante che consente di superare le numerose complessità dell’interrogazione dei grafi della conoscenza. Questo lavoro propone un sistema di risposta alle domande basato su KG (KGQAS) che consiste in due fasi principali: 1) una fase offline e 2) una fase di analisi semantica.
Mentre la fase offline mira a convertire le domande in linguaggio naturale in modelli di query formali in modo semi-automatico, la fase di analisi semantica sfrutta l’apprendimento automatico per costruire un modello di previsione. Il modello viene addestrato sull’output della prima fase. Consente di prevedere il modello di query più appropriato per una determinata domanda. Per la valutazione, SalzburgerLand KG viene utilizzato come caso d’uso pratico. È un grafo della conoscenza del mondo reale creato utilizzando il vocabolario del markup di schema e il suo obiettivo primario è l’automazione dei dati strutturati che descrivono le entità turistiche della regione di Salisburgo, in Austria.
IA spiegabile
L’intelligenza artificiale spiegabile si focalizza sulla spiegazione delle decisioni prese da un modello di intelligenza artificiale. La maggior parte dei modelli di intelligenza artificiale non è apertamente disponibile al pubblico e quindi non fornisce una motivazione per le decisioni che prende. Grazie ai grafi della conoscenza costruiti a partire dal web semantico; relazioni tra entità difficili da trovare possono essere ora individuate. Tali relazioni vengono quindi utilizzate come “verità fondamentali” per ripercorrere a ritroso i risultati del modello. L’approccio più comune consiste nel mappare input di rete o neuroni a classi di un’ontologia o ad entità di dati strutturati web.
Riferimenti:
- Knowledge graph: Wikidated 1.0: An Evolving Knowledge Graph Dataset of Wikidata’s Revision History
- Domanda/risposta su knowledge graph: Question Answering Over Knowledge Graphs: A Case Study in Tourism
- Intelligenza Artificiale spiegabile e uso di dati strutturati: Semantic Web Technologies for Explainable Machine Learning Models: A Literature Review
Uso open source di dati strutturati
Tre progetti degni di nota che fanno molto affidamento sull’uso di dati strutturati sono i seguenti:
- Open Source Metadata Framework (OMF) - L’OMF mira a raccogliere dati su documentazione/metadati Open Source che vengono generalmente archiviati in un formato di dati strutturati che verrà utilizzato per descrivere la documentazione. L’idea è che l’OMF agirà come un sofisticato tipo di sistema di catalogo a schede per i numerosi progetti di documentazione Open Source esistenti.
- DBpedia è un insieme di set di dati, strumenti e servizi relativi ai dati web strutturati. Ad oggi contiene più di 228 milioni di entità liberamente disponibili. Il principale Knowledge Graph di DBpedia comprende dati puliti provenienti da Wikipedia. DBPedia è disponibile in tutte le lingue supportate da Wikipedia e ha una media di oltre 600.000 download di file all’anno. Alcuni strumenti open source costruiti su DBpedia forniscono accesso ai dati, controllo delle versioni, controllo di qualità, visualizzazione delle ontologie e infrastrutture di collegamento.
- Wikidata memorizza dati strutturati da progetti Wikimedia come Wikipedia. È un database orientato ai documenti, che si concentra sulla memorizzazione di dati web strutturati.
Casi d’uso
L’implementazione dei dati strutturati è ampiamente vantaggiosa in numerose aree, alcune delle quali verranno trattate in questa sezione. È importante notare che molte di queste aree si sovrappongono, così è infatti la natura dei dati collegati e strutturati.
Collegamento di dati
Quando si hanno dati strutturati e collegati, mentre si utilizzano identificatori per designare luoghi, eventi, persone, concetti, ecc., i dati possono essere citati da altre fonti di dati e in questo modo dunque possono rendere più accessibili le loro descrizioni dei metadati. Tali dati sono quindi più condivisibili e riutilizzabili.
Con il collegamento dei dati (data linking) raccogliamo informazioni da diverse fonti per creare dati più ricchi e utili. Ciò è possibile grazie ai dati strutturati, i cui identificatori univoci globali consentono alle macchine di leggere e comprendere la relazione tra diversi tipi di dati. Il che comporta l’utilità di creare una rete di relazioni più connessa.
Ottimizzazione per i motori di ricerca e trovabilità
L’ottimizzazione per i motori di ricerca (SEO) è l’area incentrata sul creare il contenuto di una pagina web in modo che abbia risultati migliori nei motori di ricerca. Naturalmente, questo è molto importante per la trovabilità poiché un’implementazione di successo della SEO può consentire a una pagina di apparire più in alto nella pagina dei risultati del motore di ricerca (SERP). La SERP è dove i titoli, gli URL e le meta descrizioni vengono mostrati in seguito ad una query di ricerca.
Aggiungendo dati strutturati alle pagine web, possiamo ottimizzare una pagina web per i motori di ricerca, nonché avere contenuti extra visibili dalla SERP. Questo contenuto extra può presentarsi in molte forme, alcune delle quali sono state discusse in precedenza, vale a dire nel Knowledge Panel, nei Rich Snippet e nelle Domande correlate.
Avere questa ulteriore trovabilità, abilitata dai dati strutturati, è essenziale per aumentare il traffico verso una pagina web dai motori di ricerca. Ne consegue che le pagine di aziende e e-commerce possono trarre grande beneficio da queste tecnologie, che saranno discusse nella sezione seguente.
E-commerce e business
L’implementazione di dati strutturati per le pagine web degli e-commerce è incredibilmente vantaggiosa per i gestori del business. Esistono numerosi tipi di dati strutturati ampiamente utilizzati da queste aziende per la SEO.
LocalBusiness (attività locale) è un tipo di dati strutturati che può restituire una scheda informativa Google (Google knowledge panel) arricchita con i dettagli inseriti in quel tipo di dati strutturati a seguito di una query di ricerca pertinente (ad esempio “ristoranti famosi a Dublino”). Questo particolare tipo di dati strutturati può anche contenere gli orari di apertura, i diversi reparti all’interno di un’azienda, le recensioni per l’azienda, dati che potrebbero tutti essere visualizzati anche a seguito di una query di ricerca in un’app di mappe.
Product (prodotto), questo tipo di dati strutturati, funziona in modo simile a LocalBusiness in quanto consente a una query di ricerca di restituire risultati arricchiti. Questi risultati possono includere il prezzo, la disponibilità, le recensioni, le valutazioni e persino delle immagini visibili nei risultati di ricerca. Questi elementi aggiunti possono aumentare di molto le probabilità che il prodotto riceva attenzione durante la ricerca. Gli attributi del prodotto possono aiutare a collegare i prodotti tra loro e rispondere meglio alle query di ricerca, aumentando la trovabilità.
Questi sono solo un paio di esempi di casi d’uso di dati strutturati negli e-commerce, ma esistono molti altri tipi di dati strutturati che una pagina di e-commerce può implementare per trarne vantaggio.
Un anno in rassegna
I dati strutturati si basano su formati e standard che descrivono uno schema di meta-livello in cui gli editori possono far rientrare e presentare i dati in una modalità predefinita. RDFa, OpenGraph, JSON-LD e altri formati consolidati sono stati indagati nell’analisi per questo capitolo.
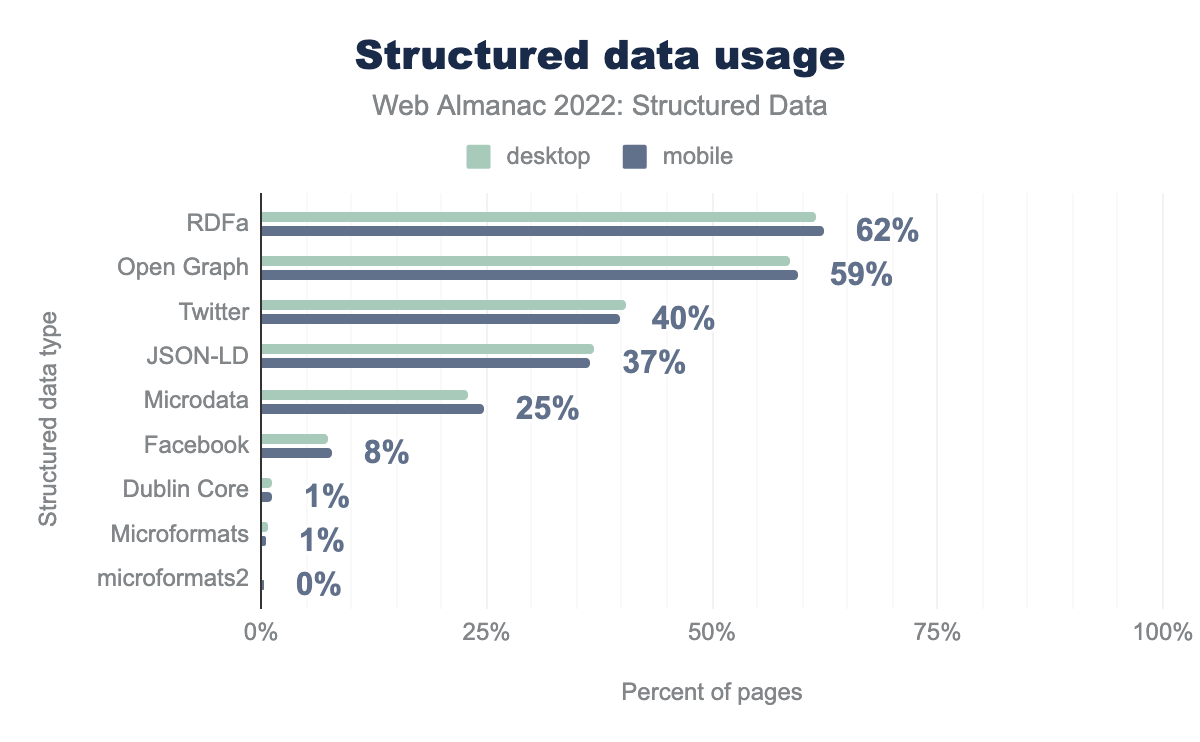
RDFa e Open Graph rimangono nella maggioranza delle pagine per dispositivi mobili rispettivamente al 62% e al 57%. I tipi di dati strutturati sono visti in modo coerente nelle pagine mobili e desktop, con i tipi Microformat e Microformat2 che si differenziano maggiormente dagli altri tipi di dati strutturati che abbiamo esaminato in questo capitolo. I Microformat hanno l’86% di rilievo sulle pagine per dispositivi mobili, mentre i Microformat2 hanno il 171% di rilievo sulle pagine per dispositivi mobili. Questi due tipi di dati strutturati costituiscono una piccola percentuale di quelli trovati nel nostro set.
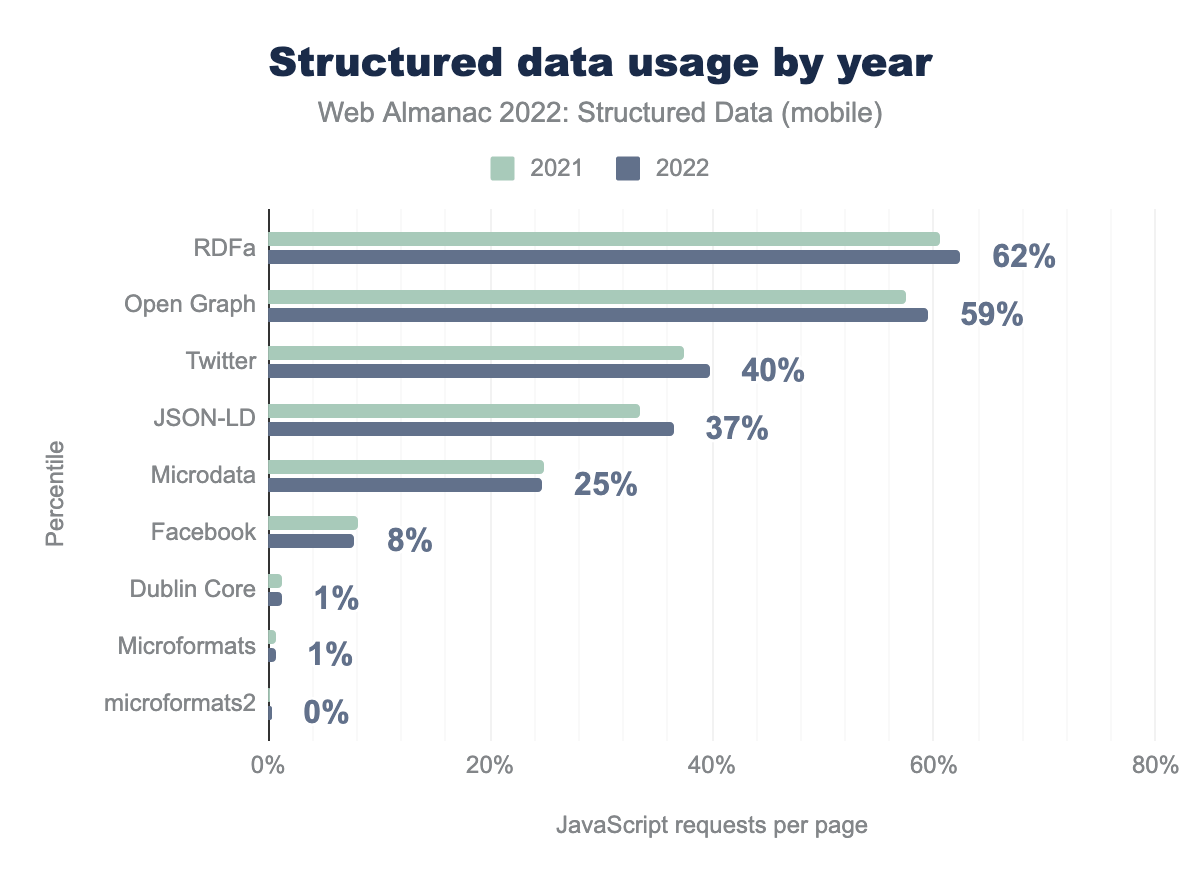
Si apprezza un generale aumento dei tipi di dati strutturati di ampia diffusione, inclusi i meta tag di Twitter (passati dal 37% al 40%) e JSON-LD (con un aumento di copertura dal 34% complessivo nel 2021 al 37% complessivo nel 2022). C’è una leggera flessione nell’utilizzo di alcuni tipi di dati strutturati meno diffusi come i Microdata, i meta tag di Facebook, i Dublin Core e i Microformat. Gli andamenti per le pagine desktop si sono rivelati molto simili.
La tabella seguente elenca le principali modifiche apportate ai formati di dati strutturati nell’ultimo anno. Sono stati elencati solo i tipi che hanno avuto modifiche.
| Tipo di dati | Modifche |
|---|---|
| RDFa |
Sebbene non ci siano cambiamenti nel formato di base degli RDFa, la versione 3 del Data Catalog Vocabulary (DCAT) ha avuto un aggiornamento significativo. DCAT è un “vocabolario RDF progettato per facilitare l’interoperabilità tra cataloghi di dati pubblicati sul web”. Ciò risulta maggiormente significativo per via della maggiore disponibilità di insiemi di dati aperti sul web. Essere in grado di descrivere l’intero contenuto di un set di dati aumenta notevolmente la trovabilità, e quindi l’utilità, di un set di dati pubblico e rende più probabile la ricerca e la distribuzione federate.
Riferimenti:
|
| JSON-LD |
Gli aggiornamenti e le aggiunte nell’ultimo anno sono stati poco rilevanti. Di questi, la maggior parte era correlata alla manutenzione e ad una relativa espansione del contesto, ad esempio “è stato aggiunto OnlineBusiness come sottotipo di Organizzazione e OnlineStore come sottotipo di OnlineBusiness”.
Riferimenti: |
Nel complesso ci sono stati pochi cambiamenti nelle definizioni dei principali tipi di dati come mostra la tabella, tuttavia alcuni formati sono stati migliorati in domini specifici.
Analizziamo un po’ più a fondo ciascun tipo.
RDFa
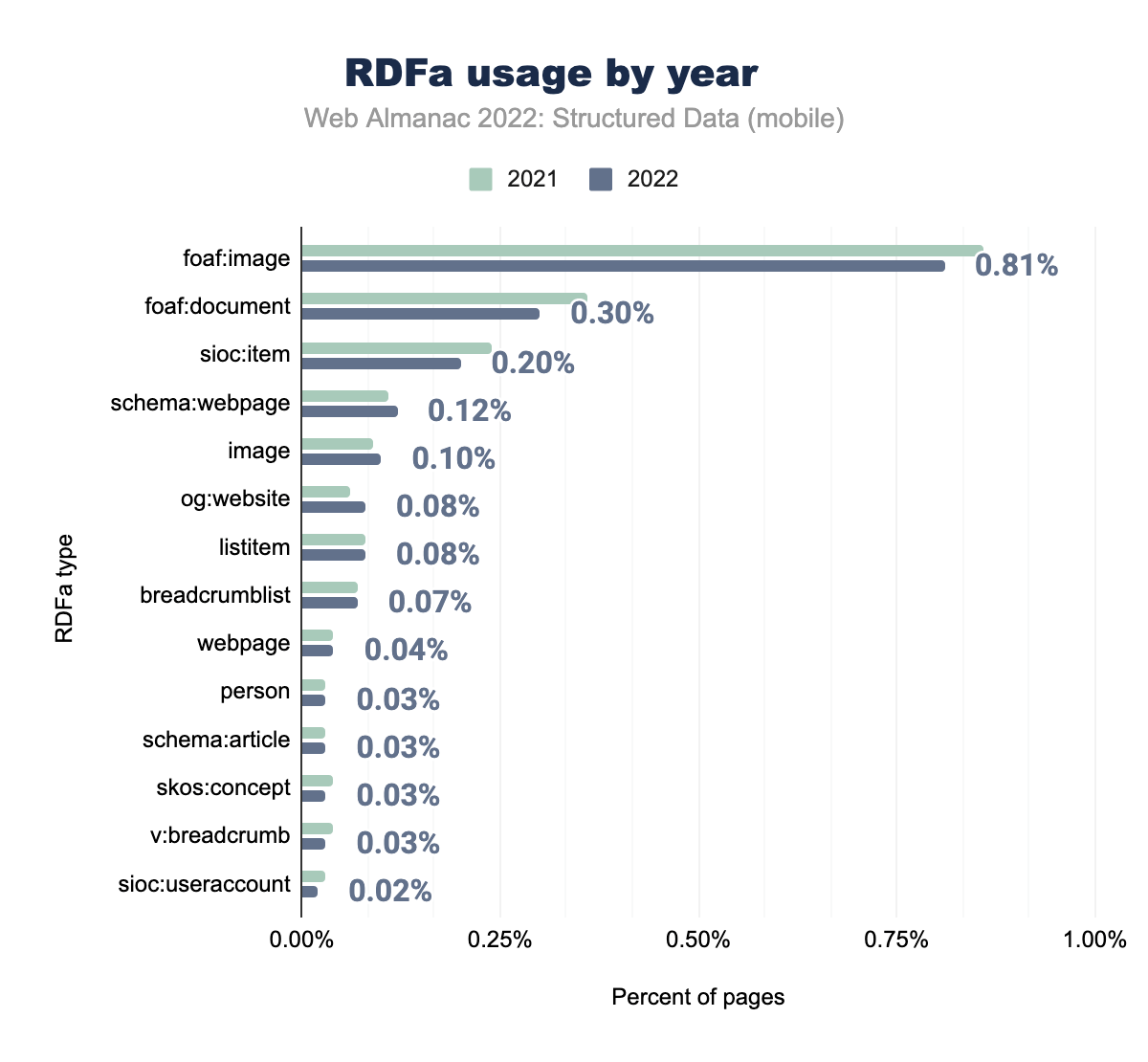
foaf:image è stato utilizzato rispettivamente nello 0,86% delle pagine nel 2021 e nello 0,81% nel 2022, foaf:document nello 0,36% e 0,30%, sioc:item nello 0,24% e 0,20 %, schema:webpage nello 0,11% e 0,12%, image nello 0,09% e 0,10%, og:website nell 0,06% e 0,08%, listitem nello 0,08% e 0,08%, breadcrumblist nello 0,07% e 0,07%, webpage nello 0,04% e 0,04%, person nello 0,03% e 0,03%, schema:article nello 0,03% e 0,03%, skos:concept nello 0,04% e 0,03%, v:breadcrumb nello 0,04% e nello 0,03% e infine sioc:useraccount è stato utilizzato nello 0,03% delle pagine nel 2021 e nello 0,02% nel 2022.Quando si valutano i tipi di RDFa, foaf:image rimane presente su un maggior numero di pagine rispetto a qualsiasi altro tipo, sebbene abbia mostrato una diminuzione della percentuale di pagine nel nostro set dal 2021. Questo vale anche per i due tipi successivi, foaf:document e sioc:item, con piccole diminuzioni nell’utilizzo. Molti degli altri tipi mostrano un leggero aumento nell’utilizzo, come è successo agli RDFa nel complesso.
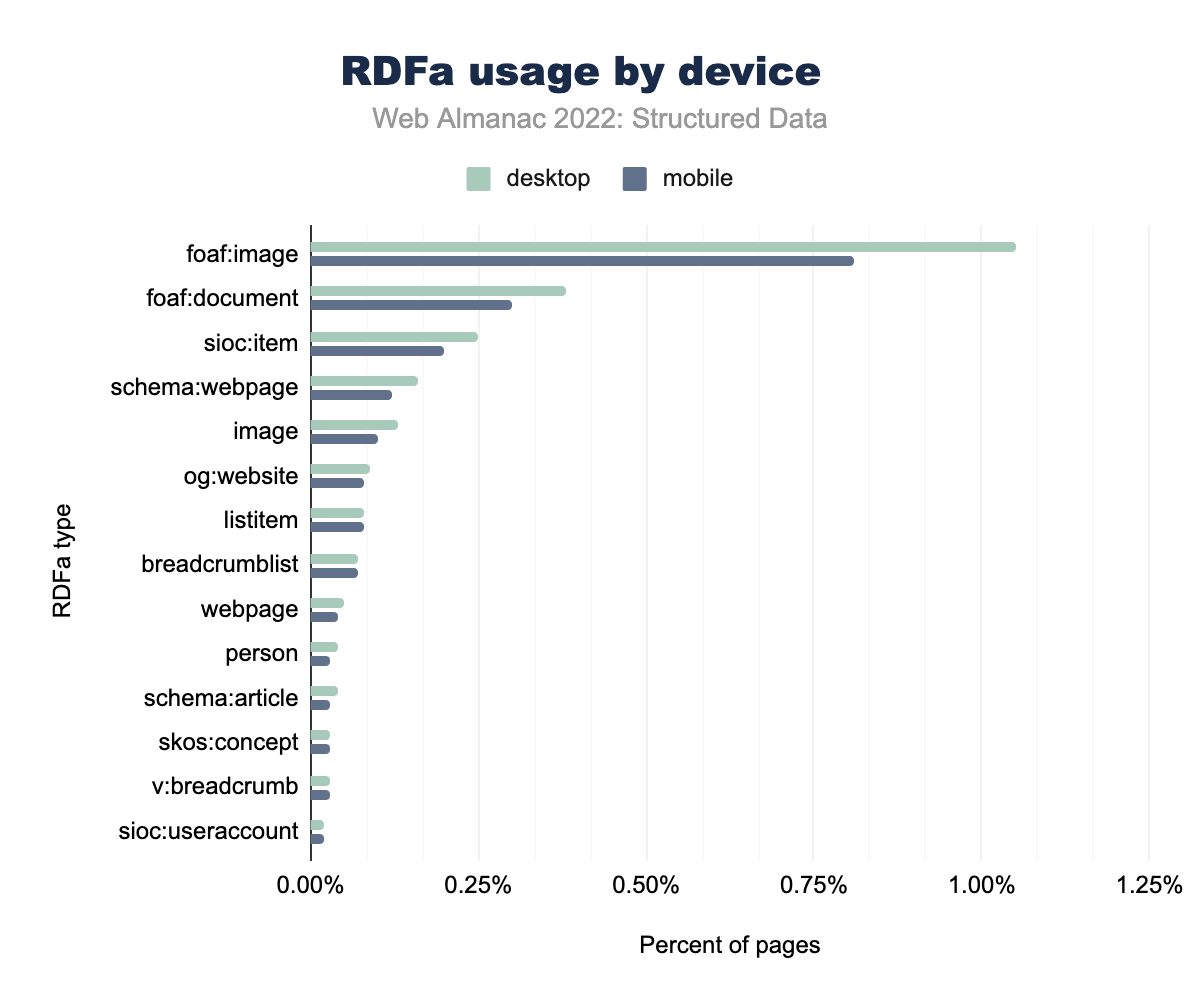
foaf:image è stato utilizzato nell’1,05% delle pagine desktop e nello 0,81% delle pagine mobili, foaf:document rispettivamente nello 0,38% e nello 0,30%, sioc:item nello 0,25% e nello 0,20%, schema:webpage su 0,16% e 0,12%, image nello 0,13% e 0,10%, og:website nello 0,07% e 0,08%, listitem nello 0,09% e 0,08%, breadcrumblist nello 0,08% e 0,07%, webpage nello 0,05% e 0,04%, person nello 0,03% e 0,03%, schema:article nello 0,04% e 0,03%, skos:concept nello 0,04% e 0,03%, v:breadcrumb nello 0,03% e 0,03% e infine sioc:useraccount nello 0,02% delle pagine desktop e mobili.Fra gli RDFa rimane più prominente sul desktop foaf:image che compare nell’1% delle pagine desktop, rispetto allo 0,81% delle pagine mobili. Altri tipi di RDFa hanno registrato un leggero aumento di occorrenze nelle pagine desktop rispetto ai dispositivi mobili, con l’eccezione di og:website che ha raggiunto lo 0,08% nelle pagine mobili e lo 0,07% nelle pagine desktop.
Dublin Core
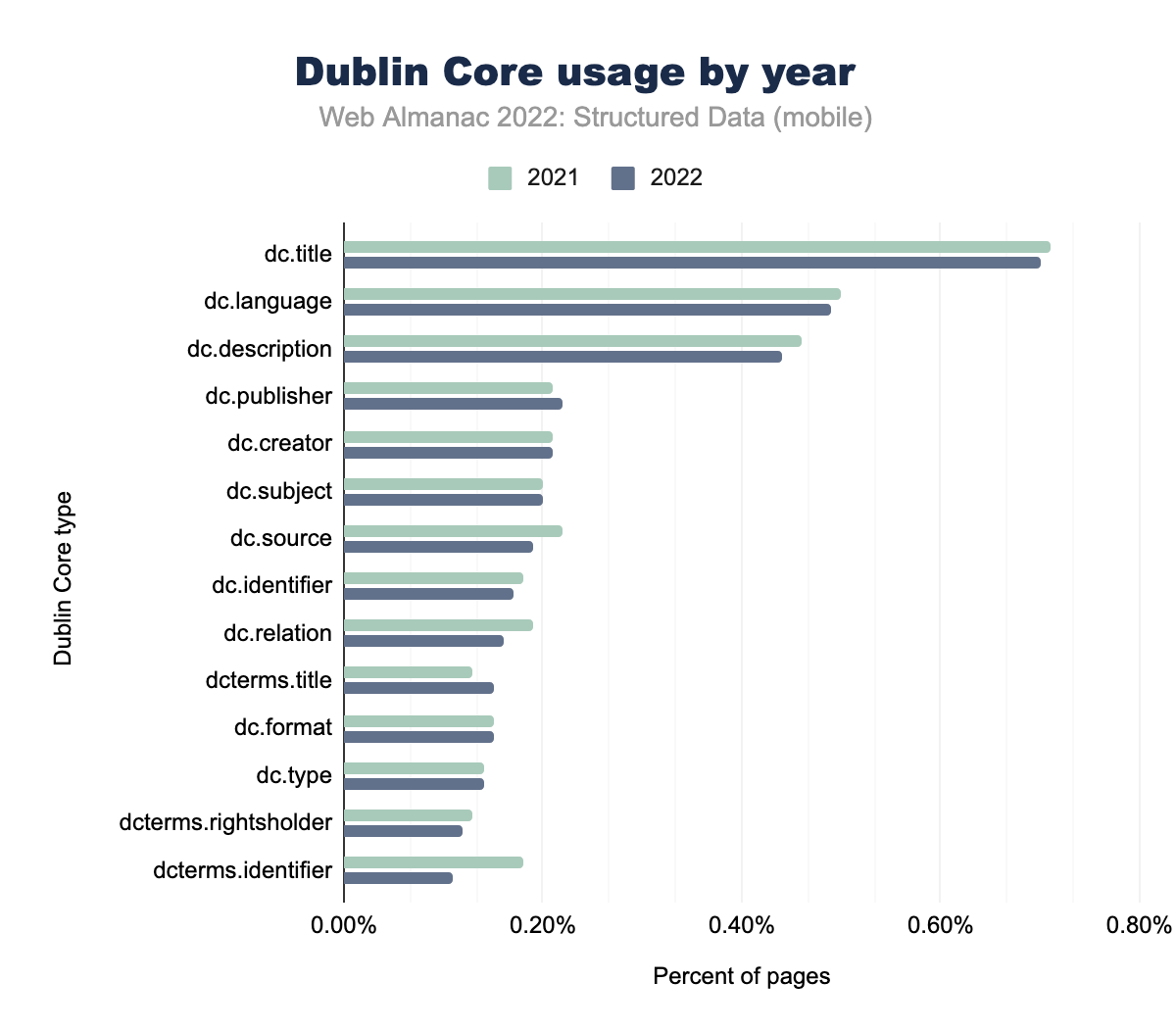
dc.title è stato utilizzato nello 0,71% delle pagine per dispositivi mobili nel 2021 e nello 0,70% nel 2022, dc.language rispettivamente nello 0,50% e nello 0,49%, dc.description nello 0,46% e nello 0,44%, dc.publisher nello 0,21% e 0,22%, dc.creator nello 0,21% e 0,21%, dc.subject nello 0,20% e 0,20%, dc.source nello 0,22% e 0,19%, dc.identifier nello 0,18% e 0,17%, dc.relation nello 0,19% e 0,16%, dcterms.title nello 0,13% e 0,15%, dc.format nello 0,15% e 0,15%, dc.type nello 0,14% e 0,14%, dcterms.rightsholder nello 0,13% e 0,12% e infine dcterms.identifier nello 0,18% delle pagine mobile nel 2021 e nello 0,11% nel 2022.L’utilizzo del tipo di attributo Dublin Core rimane molto simile tra i tipi di attributo più importanti. Un’eccezione degna di nota è dcterms.identifier, che passa dallo 0,11% nel 2021 allo 0,18% nel 2022 per le pagine mobili. Anche se piccolo in percentuale, ammonta a un conteggio di utilizzo di quasi 15.000 occorrenze nel nostro set. Questo aumento è stato riscontrato anche per le pagine desktop, sebbene non così consistente, con un passaggio dallo 0,14% nel 2021 allo 0,18% nel 2022.
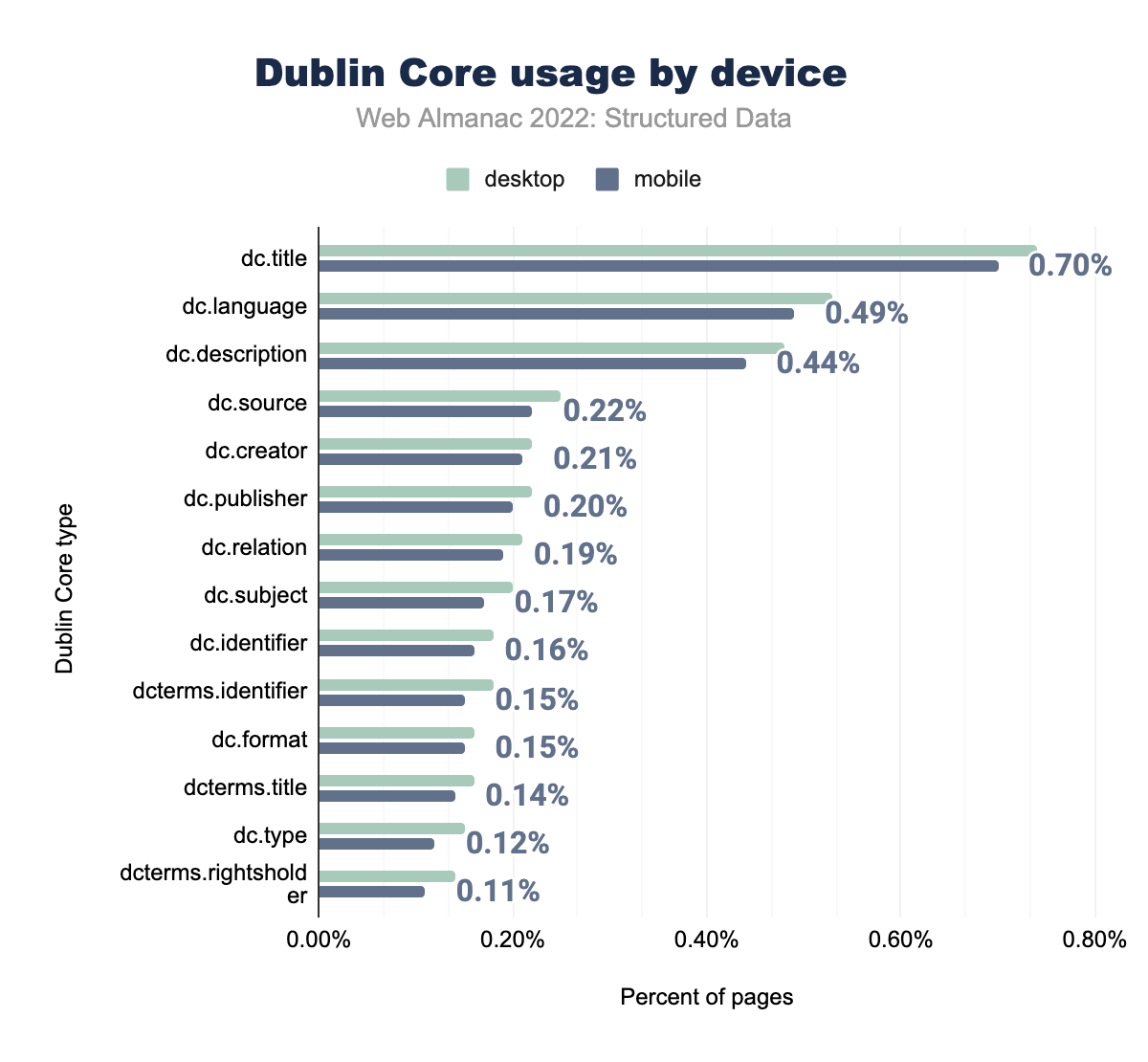
dc.title è stato utilizzato nello 0,74% delle pagine desktop e nello 0,70% delle pagine mobili, dc.language rispettivamente nello 0,53% e 0,49%, dc.description nello 0,48% e 0,44%, dc.publisher nello 0.22% e 0.22%, dc.creator nello 0.22% e 0.21%, dc.subject nello 0.20% e 0.20%, dc.source nello 0.25% e 0.19%, dc.identifier nello 0,18% e 0,17%, dc.relation nello 0,21% e 0,16%, dcterms.title nello 0,16% e 0,15%, dc.format nello 0,16% e 0,15%, dc.type nello 0,15 % e 0,14%, dcterms.rightsholder nello 0,14% e 0,12% e infine dcterms.identifier nello 0,18% delle pagine desktop e nello 0,11% delle pagine mobile.A parte questo, l’utilizzo dei tipi Dublin Core è simile per le pagine mobili e desktop, con lo stesso modesto aumento delle occorrenze rispetto all’anno precedente.
Open Graph
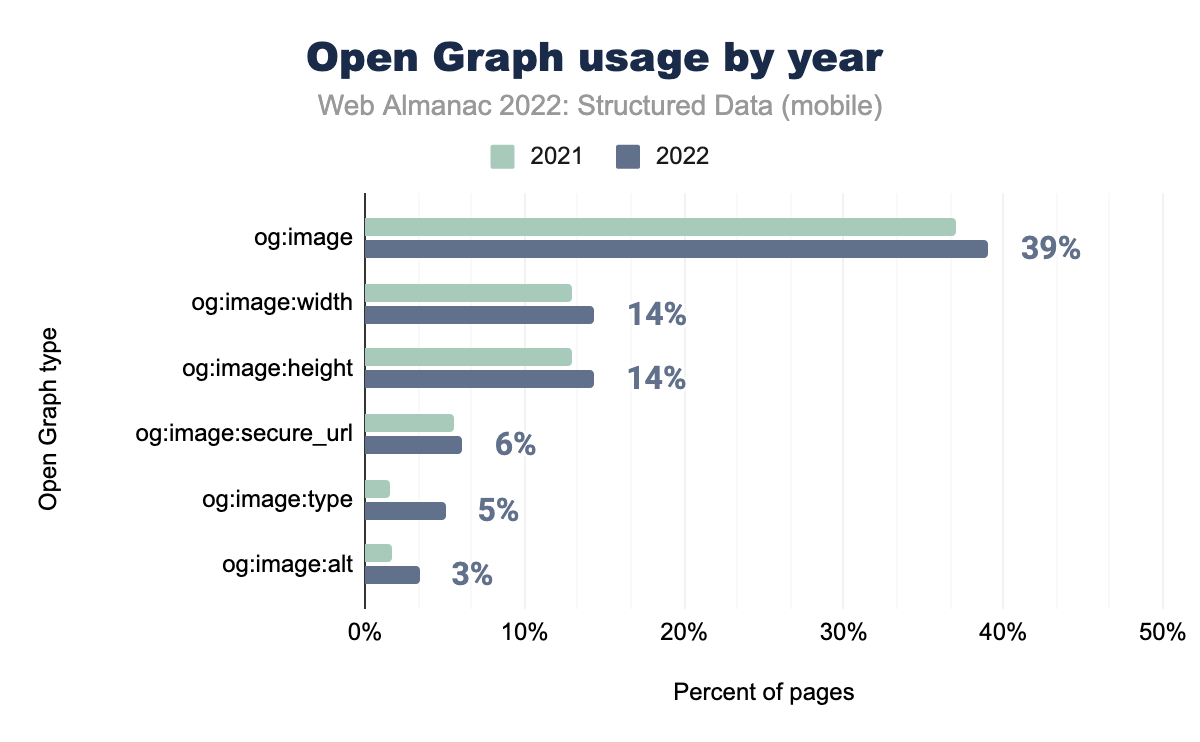
og:image è stato utilizzato nel 37% delle pagine per dispositivi mobili nel 2021 e nel 39% nel 2022, og:image:width rispettivamente nel 13% e nel 14%, og:image:height nel 13% e 14%, og:image:secure_url nel 6% e 6%, og:image:type nel 2% e 5% e infine og:image:alt nel 2% delle pagine mobili nel 2021 e 3% nel 2022.I tag Open Graph hanno visto un incremento nella diffusione di utilizzo, con il più comune di questi tag og:title che appare in oltre la metà di tutte le pagine del nostro set, insieme a og:url e og:type. La maggior parte di questi incrementi sono modesti, ad eccezione di og:image:type, la cui presenza è più che triplicata nelle pagine mobili dal 2021. Cosa che gareggia con le pagine desktop, dove si è passati dall’1,6% al 5,4% nel giro di un anno.
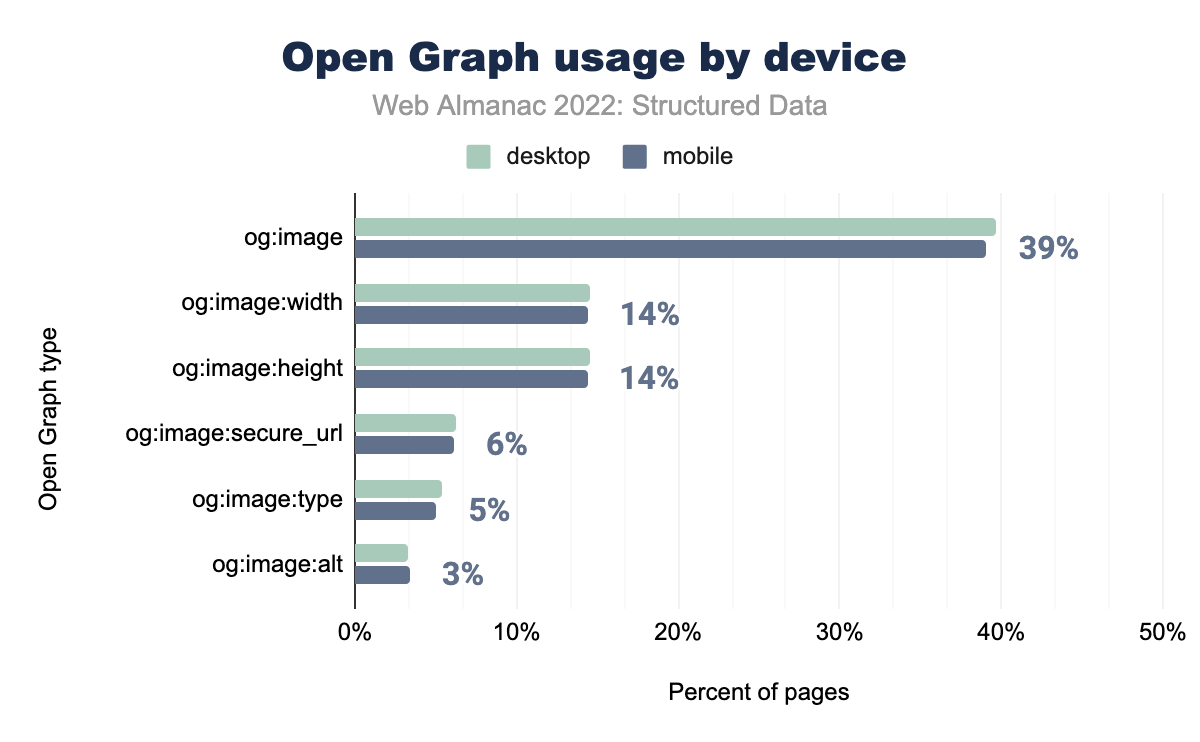
og:image è stato utilizzato nel 40% delle pagine desktop e nel 39% delle pagine mobili, og:image:width rispettivamente nel 15% e nel 14%, og:image:height nel 15% e 14%, og:image:secure_url nel 6% e 6%, og:image:type nel 5% di entrambi, e infine og:image:alt è stato utilizzato nel 3% sia su desktop che su dispositivi mobili.Abbiamo visto un aumento nell’utilizzo di ciascun tipo di Open Graph presente nella top 10 dei tipi, sia su dispositivi mobili che su desktop, il che ha portato ad una crescita complessiva di Open Graph dell’1,5% rispetto al 2021.
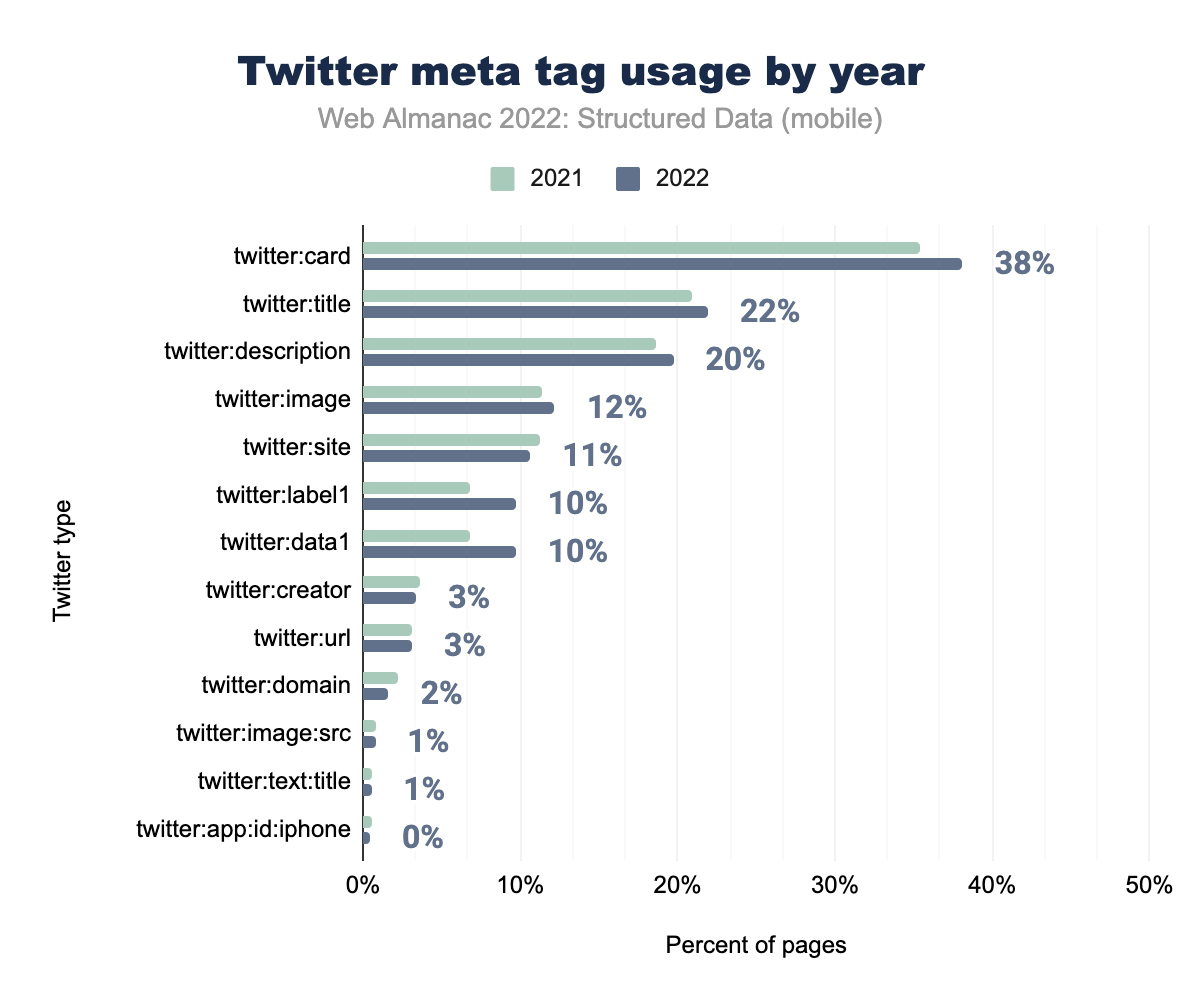
twitter:card è stato utilizzato nel 35% delle pagine mobili nel 2021 e nel 38% nel 2022, twitter:title rispettivamente nel 21% e nel 22%, twitter:description nel 19% e nel 20%, twitter:image nel 11% e 12%, twitter:site nel 11% e 11%, twitter:label1 nel 7% e 10%, twitter:data1 nel 7% e 10%, twitter: creator nel 4% e 3%, twitter:url nel 3% e 3%, twitter:domain nel 2% e 2%, twitter:image:src nell’1% e 1%, twitter: text:title nell’1% e nell’1% e infine twitter:app:id:iphone è stato utilizzato nell’1% delle pagine mobili nel 2021 e nello 0% nel 2022.I meta tag di Twitter seguono ancora una volta l’andamento di un aumento generale dell’utilizzo, più specificamente nei tag comuni di twitter:card, twitter:title, twitter:description e twitter:image. Un notevole aumento si apprezza per twitter:label1 e twitter:data1, entrambi dal 7% nel 2021 al 10% nel 2022 per le pagine mobili.
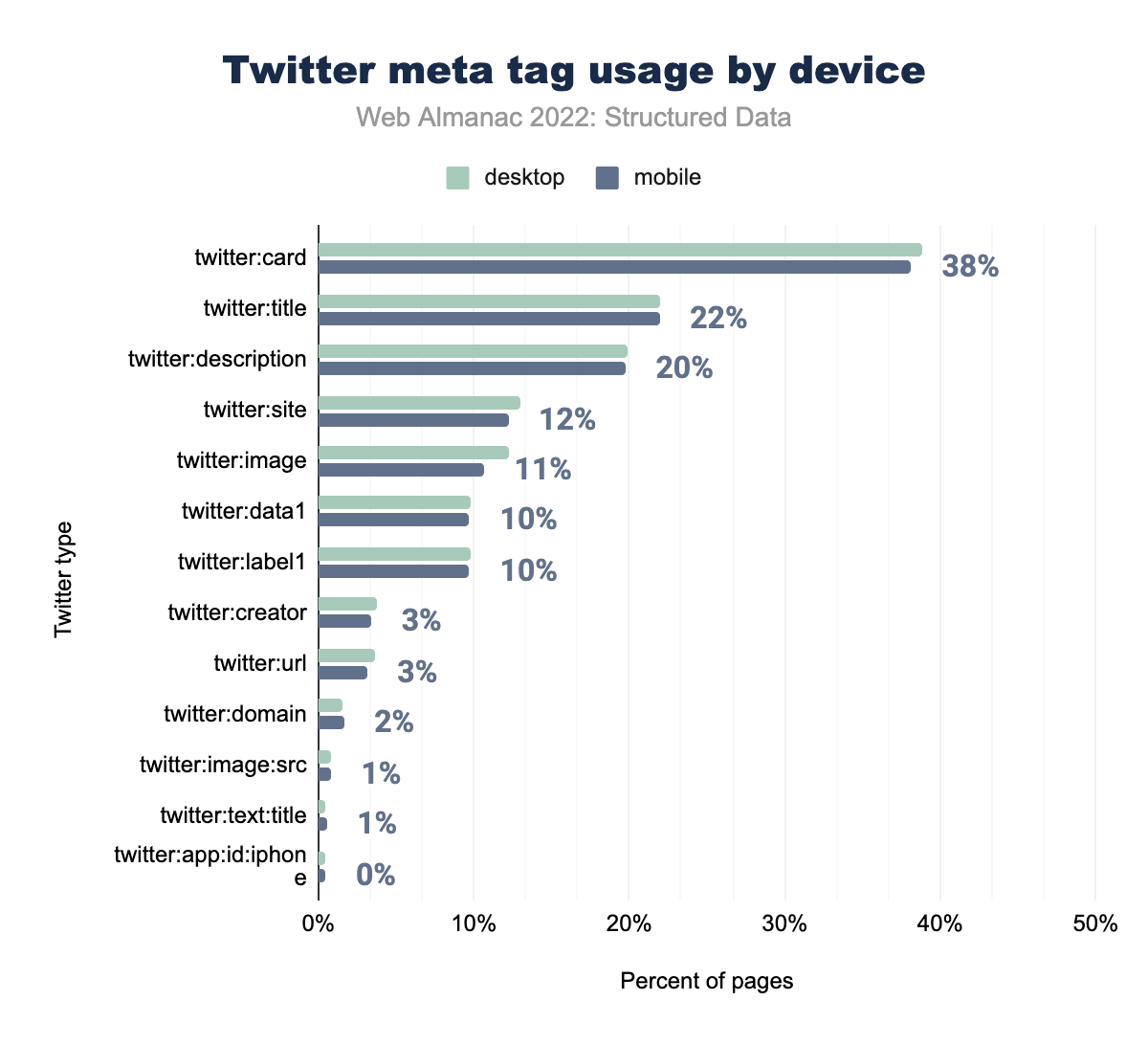
twitter:card è stato utilizzato nel 39% delle pagine desktop e nel 38% delle pagine mobili, twitter:title rispettivamente nel 22% e nel 22%, twitter:description nel 20% e nel 20%, twitter:image nel 12% e 12%, twitter:site nel 13% e 11%, twitter:label1 nel 10% e 10%, twitter:data1 nel 10% e 10%, twitter:creator nel 4% e 3%, twitter:url nel 4% e 3%, twitter:domain nel 2% e 2%, twitter:image:src nell’1% e 1%, twitter:text:title nello 0% e sull’1% e infine twitter:app:id:iphone è stato utilizzato nello 0% delle pagine desktop e mobili.I meta tag di Twitter come twitter:site e twitter:image hanno una presenza maggiore sui siti desktop, sebbene la maggior parte di questi meta tag condivida la stessa prevalenza tra dispositivi mobili e desktop, nonché di anno in anno. Alcuni dei tag meno comuni hanno visto un leggero calo nell’uso quest’anno, sebbene l’utilizzo dei meta tag di Twitter ottiene complessivamente un aumento rispetto allo scorso anno.
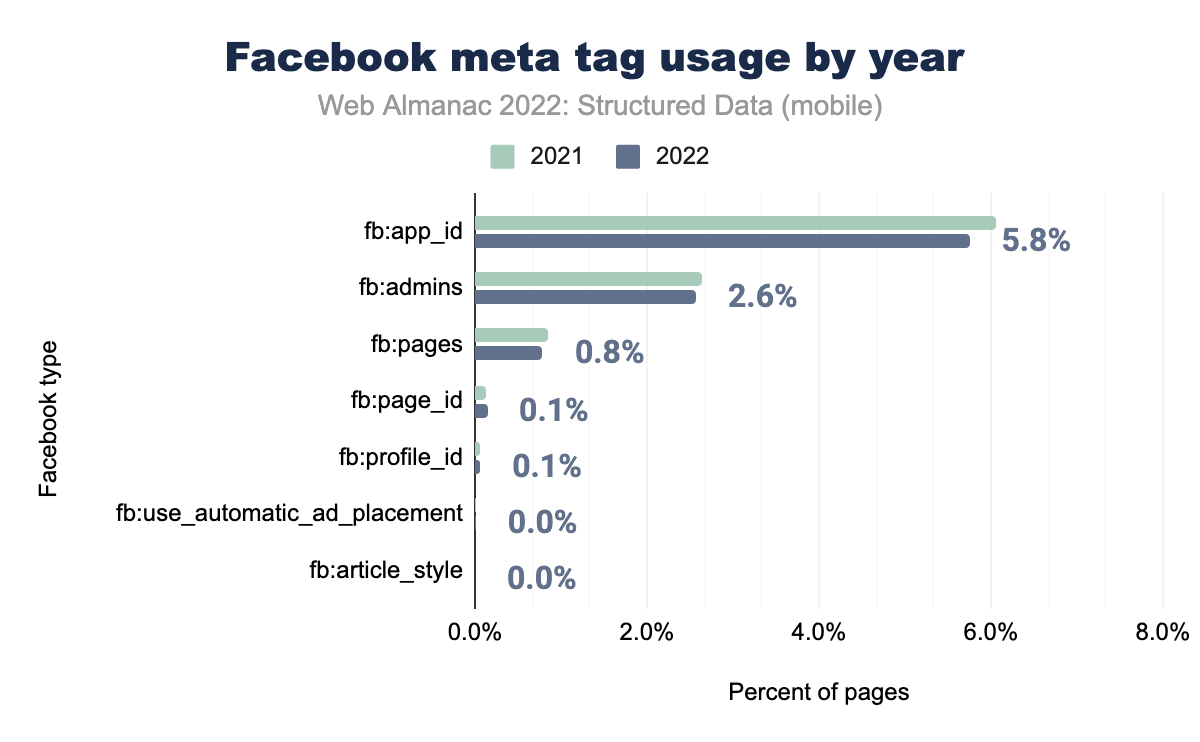
fb:app_id è stato utilizzato nel 6,1% delle pagine mobili nel 2021 e nel 5,8% nel 2022, fb:admins rispettivamente nel 2,6% e nel 2,6%, fb:pages nello 0,9% e nello 0,8%, fb:page_id e fb:profile_id nello 0,1% in entrambi gli anni e fb:use_automatic_ad_placement e fb:article_style nello 0,0% in entrambi gli anni.Di tutti i tag di Facebook qui, ce ne sono solo tre con un numero significativo di apparizioni. Si tratta degli stessi tre che erano primi nel 2021, vale a dire fb:app_id, fb:admins e fb:pages al 5,8%, 2,6% e 0,8% nei dispositivi mobili, tutti in leggera diminuzione rispetto allo scorso anno.
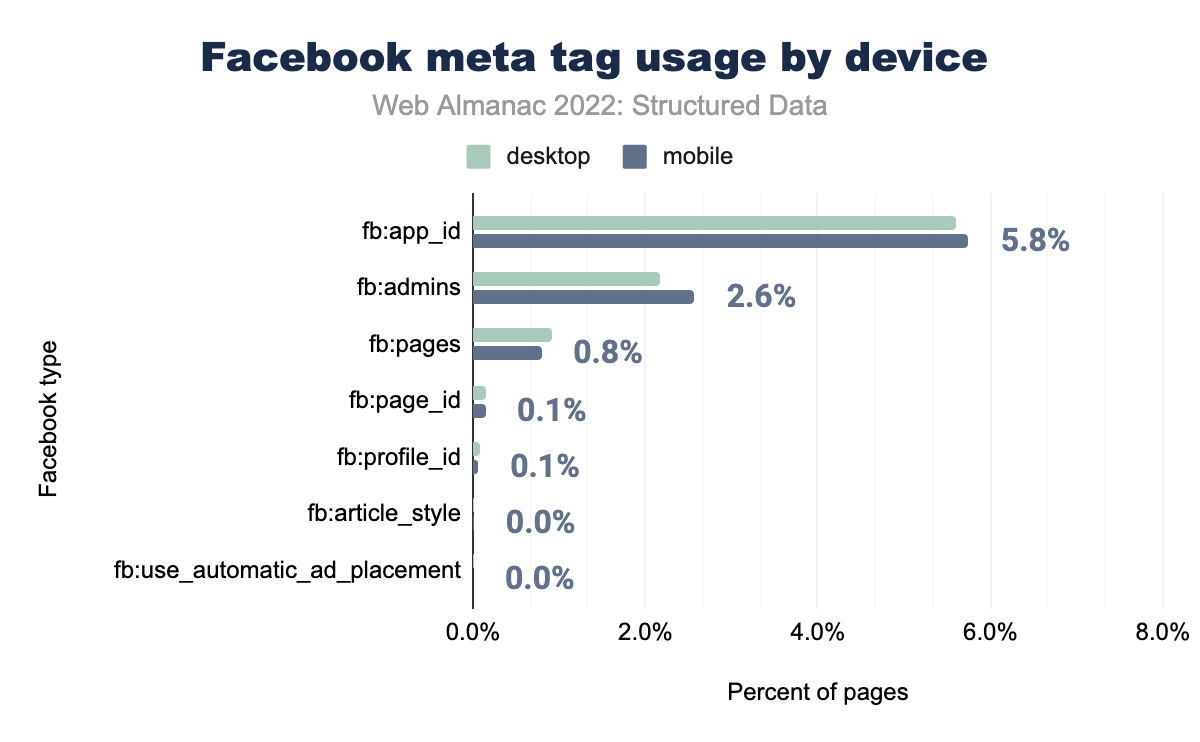
fb:app_id è stato utilizzato nel 5,6% delle pagine desktop e nel 5,8% delle pagine mobili, fb:admins rispettivamente nel 2,2% e nel 2,6%, fb:pages nello 0,9% e nello 0,8%, fb:page_id nello 0,2% e 0,1%, fb:profile_id nello 0,1% su entrambi e fb:use_automatic_ad_placement e fb:article_style nello 0,0% delle pagine desktop e mobili.Questo vale anche per le pagine desktop, con l’eccezione di fb:pages in leggero aumento dallo 0,90% nel 2021 allo 0,92% nel 2022. Il meta tag fb:pages_id vede un leggero aumento sia nelle pagine mobili che in quelle desktop, ma dall’anno scorso l’utilizzo complessivo dei meta tag di Facebook ha registrato un calo sia per le pagine mobili che per quelle desktop.
Microformat e microformat2
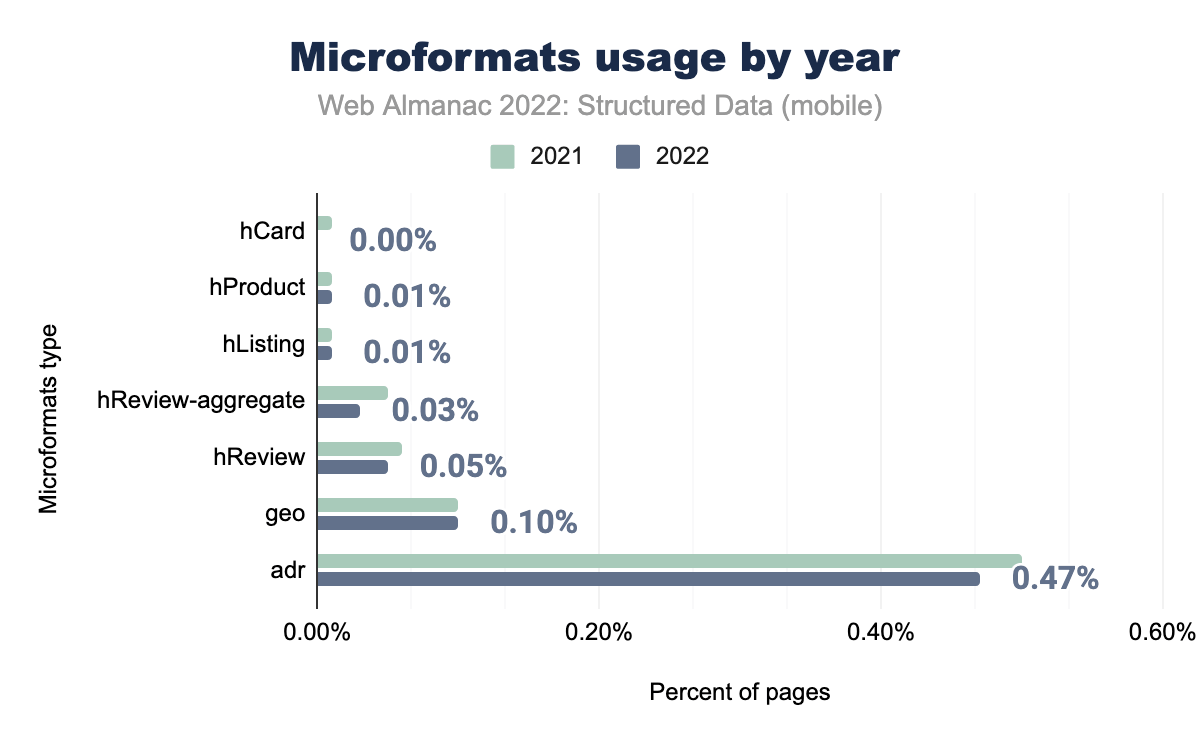
adr è stato utilizzato nello 0,50% delle pagine mobili nel 2021 e nello 0,47% nel 2022, geo rispettivamente nello 0,10% e 0,10%, hReview nello 0,06% e 0,05%, hReview-aggregate nello 0,05 % e 0,03%, hListing e hProduct nello 0,01% in entrambi gli anni, e infine hCard nello 0,01% delle pagine mobile nel 2021 e nello 0,00% nel 2022.I Microformat (microformati) sono rimasti molto simili nei dati di utilizzo dal 2021, con adr (presente nello 0,47% delle pagine del nostro set) che è ancora il più comune nella classifica.
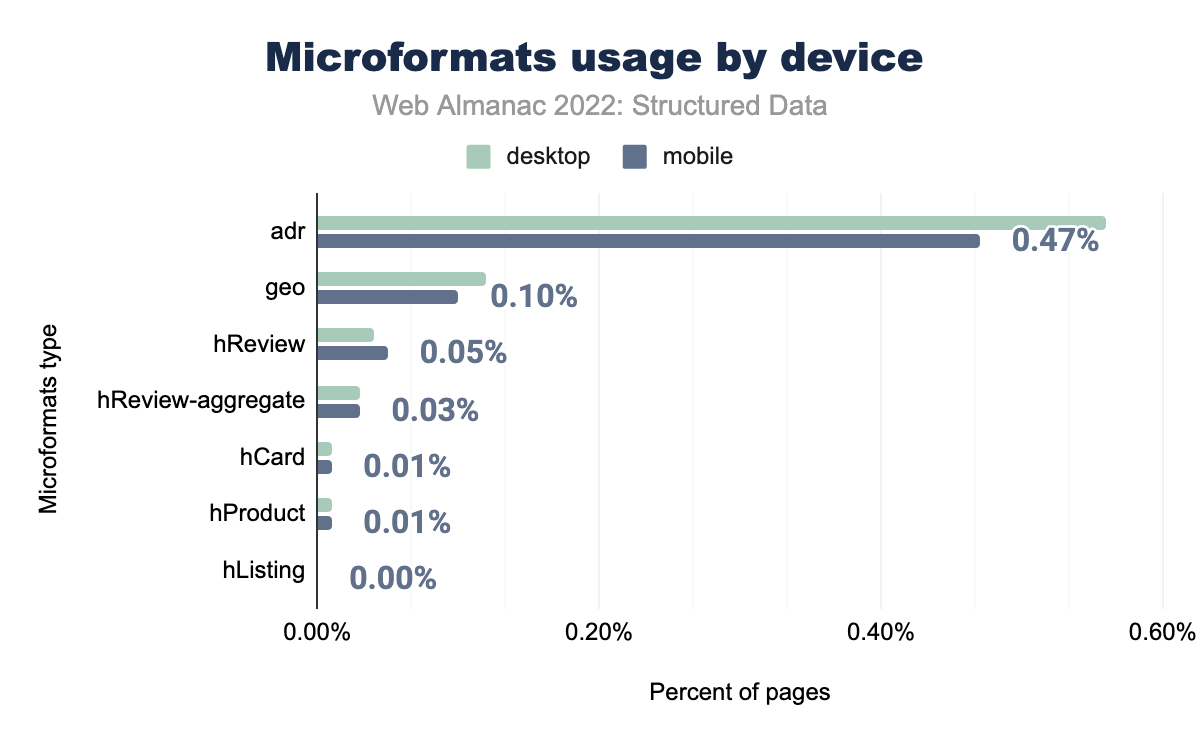
adr è stato utilizzato nello 0,56% delle pagine desktop e nello 0,47% delle pagine mobili, geo rispettivamente nello 0,12% e 0,10%, hReview nello 0,04% e 0,05%, hReview-aggregate nello 0,03% e 0,03%, hListing nello 0,00% e 0,01%, hProduct nello 0,01% e 0,01% e infine hCard è stato utilizzato nello 0,01% delle pagine desktop e nello 0,00% delle pagine mobili.Sia il mobile che il desktop condividono un mix di aumenti e diminuzioni di utilizzo tra i tipi di microformato, sebbene entrambi abbiano una media inferiore ai numeri registrati l’anno scorso. Alcuni tipi che pesano su questa diminuzione sono hReview (passato dallo 0,06% allo 0,05% nelle pagine per dispositivi mobili e dallo 0,06% allo 0,04% nelle pagine desktop) e hReview-aggregate (passando dallo 0,06% allo 0,04% sia su dispositivi mobili che su pagine desktop).
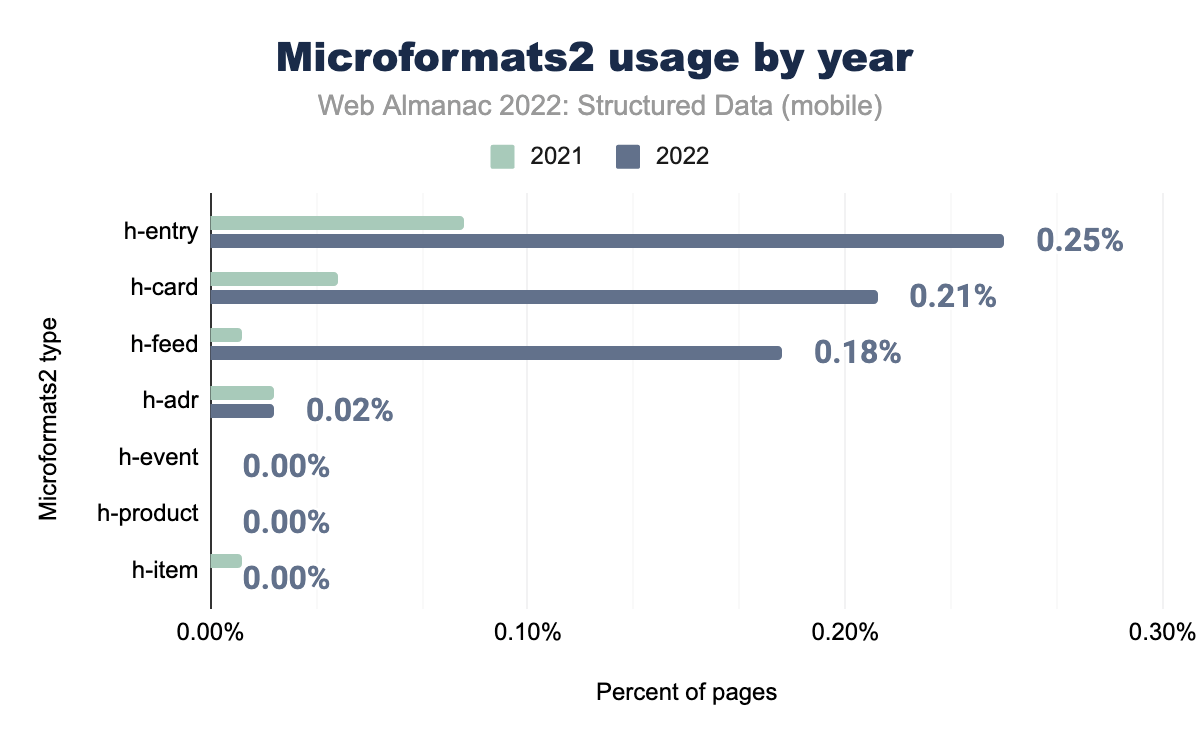
h-entry è stato utilizzato nello 0,08% delle pagine mobili nel 2021 e nello 0,25% nel 2022 h-card rispettivamente nello 0,04% e 0,21%, h-feed nello 0,01% e 0,18% , h-adr nello 0,02% e 0,02%, h-event nello 0,00% e 0,00%, h-product nello 0,00% e 0,00% e infine h-item è stato utilizzato nello 0,01% delle pagine mobili nel 2021 e 0,00% nel 2022.Nel frattempo, gli attributi nel formato Microformat2 sono saliti alle stelle dal 2021. Le proprietà h-entry, h-card e h-feed hanno visto copicui aumenti nel nostro set di pagine, il che spiega il fatto che gli attributi Microformat2 sono complessivamente quasi triplicati nel nostro set dall’anno precedente.
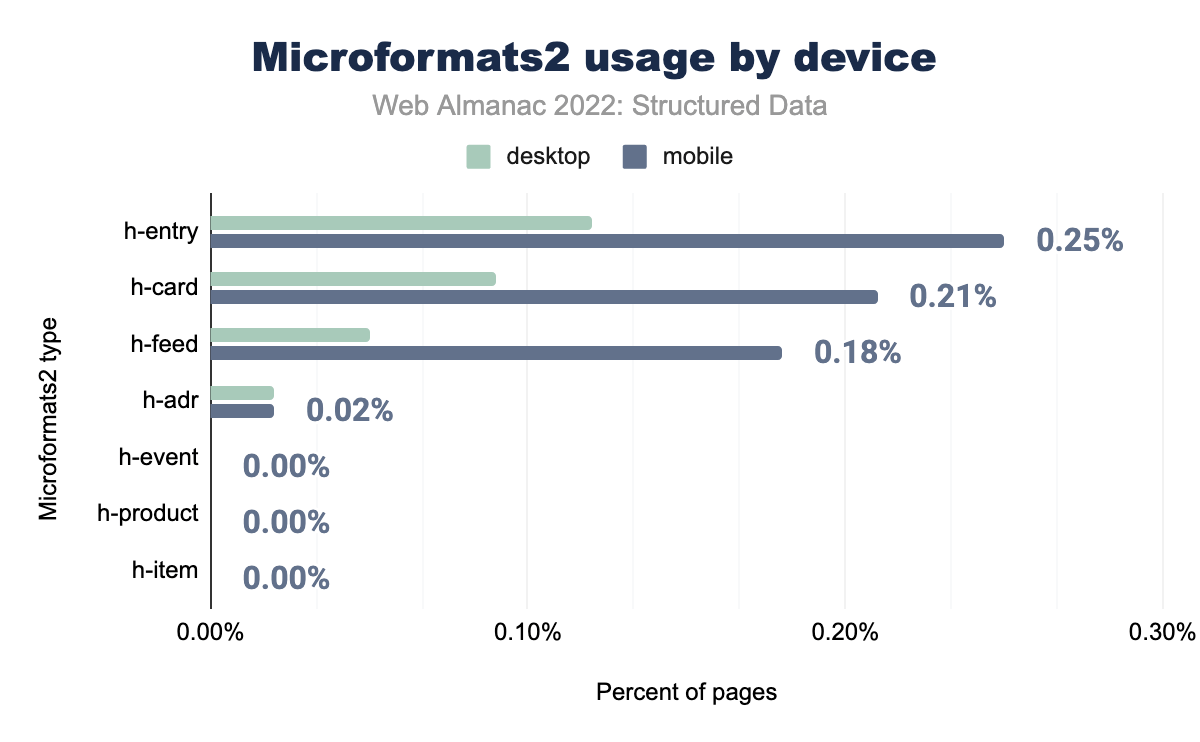
h-entry è stato utilizzato nello 0,12% delle pagine desktop e nello 0,25% delle pagine mobili, h-card rispettivamente nello 0,09% e 0,21%, h-feed nello 0,05% e 0,18%, h-adr nello 0,02% e 0,02% e h-event, h-product e h-item nello 0,00% delle pagine desktop e mobili.Questa crescita è visibile in modo più drastico nelle pagine mobili, sebbene le pagine desktop seguano lo stesso andamento. A parte questo, h-adr rimane esattamente lo stesso in entrambi gli anni e su entrambe le piattaforme allo 0,02% delle pagine.
Microdata
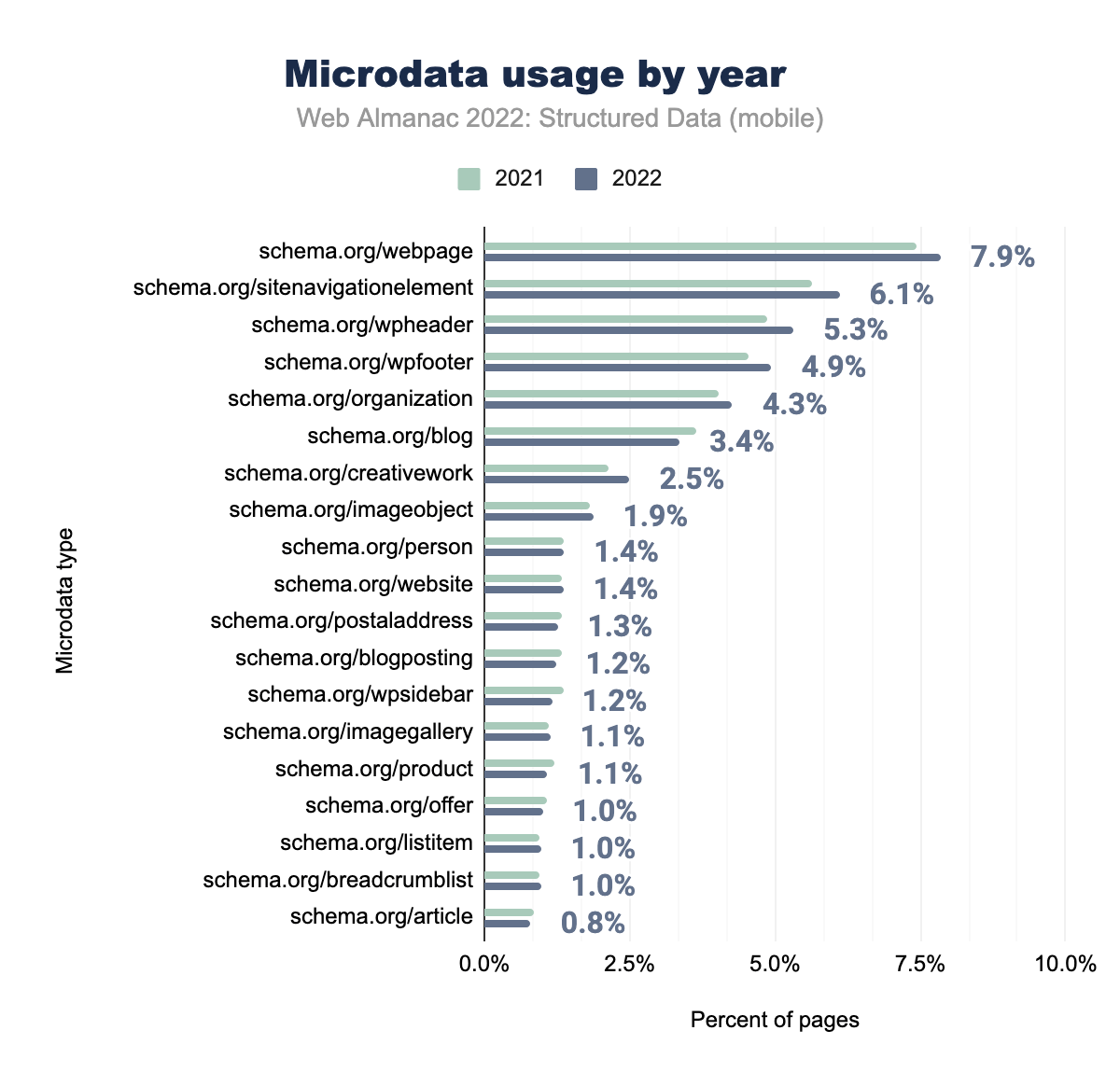
schema.org/webpage è stato utilizzato nel 7,4% delle pagine per dispositivi mobili nel 2021 e nel 7,9% nel 2022, schema.org/sitenavigationelement rispettivamente nel 5,6% e nel 6,1%, schema.org/wpheader nel 4,9 % e 5,3%, schema.org/wpfooter nel 4,6% e 4,9%, schema.org/organization nel 4,0% e 4,3%, schema.org/blog nel 3,7% e 3,4%, schema.org/creativework nel 2,1% e nel 2,5%, schema.org/imageobject nel’1,8% e nel’1,9%, schema.org/person nel’1,4% e nell’1,4%, schema.org/website nel’1,3% e 1,4%, schema.org/postaladdress nel 1,3% e 1,3%, schema.org/blogposting nel 1,3% e 1,2%, schema.org/wpsidebar nel 1,4% e 1,2%, schema.org/imagegallery nel 1,1% e 1,1%, schema.org/product nel 1,2% e 1,1%, schema.org/offer nel 1,1% e 1,0%, schema.org/listitem nel 1,0% e 1,0% , schema.org/breadcrumblist nell’1,0% e nell’1,0% e infine schema.org/article nello 0,9% delle pagine per dispositivi mobili nel 2021 e nello 0,8% delle pagine per dispositivi mobili nel 2022.La maggior parte delle proprietà per i Microdata non ha subito grandi cambiamenti, con un leggero aumento di alcune delle proprietà più comuni come webpage, sitenavigationelement e wpheader che appaiono rispettivamente nel 7,9%, 6,1% e 5,3% delle pagine per dispositivi mobili .
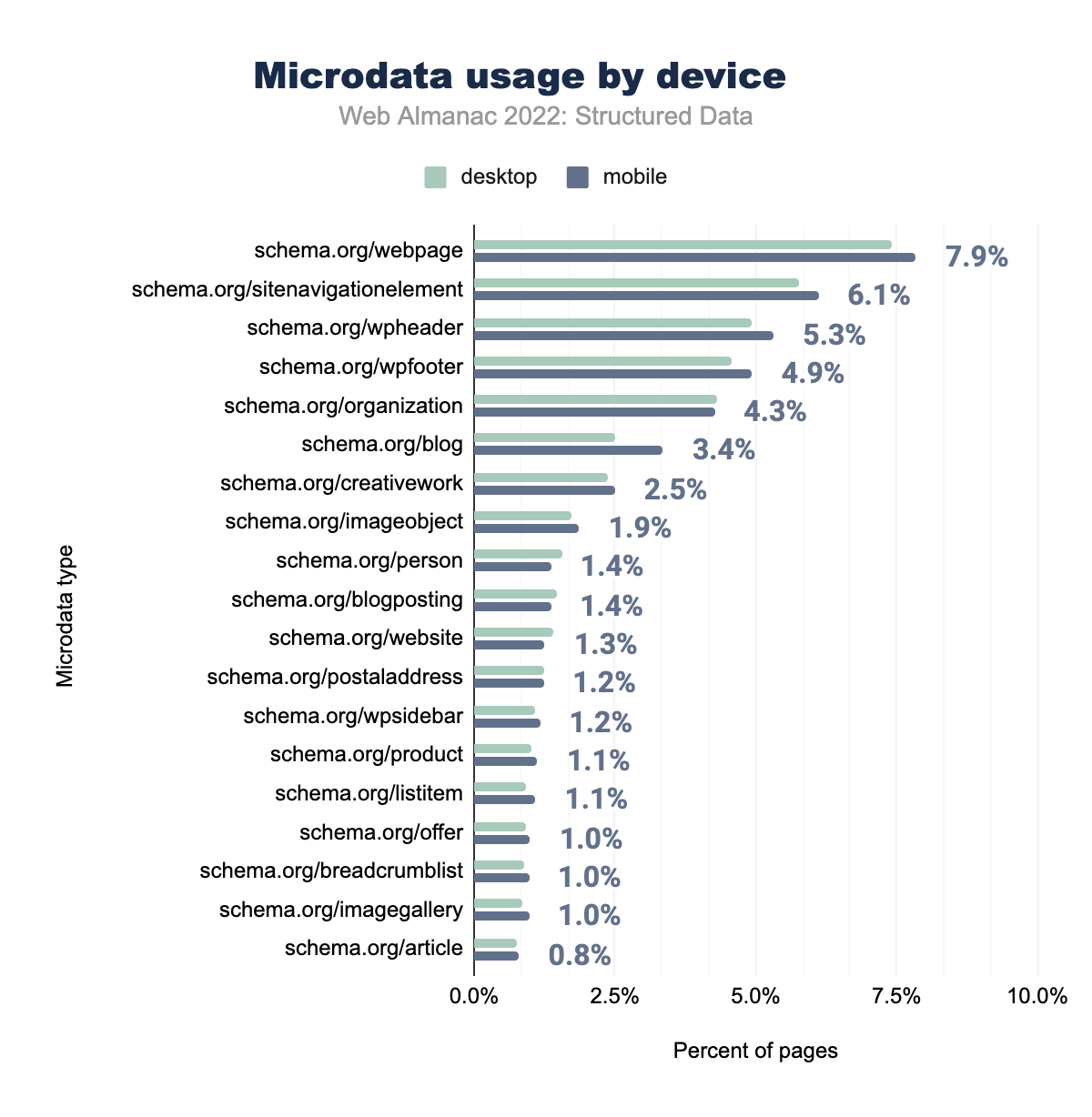
schema.org/webpage è stato utilizzato rispettivamente nel 7,4% delle pagine desktop e nel 7,9% delle pagine mobili, schema.org/sitenavigationelement rispettivamente nel 5,8% e 6,1%, schema.org/wpheader nel 4,9% e 5,3%, schema.org/wpfooter nel 4,6% e 4,9%, schema.org/organization nel 4,3% e 4,3%, schema.org/blog nel 2,5% e 3,4%, schema.org/creativework nel 2,4% e 2,5%, schema.org/imageobject nel 1,7% e 1,9%, schema.org/person nel 1,6% e 1,4%, schema.org/website nel 1,4% e 1,4% , schema.org/postaladdress nel 1,3% e 1,3%, schema.org/blogposting nel 1,5% e 1,2%, schema.org/wpsidebar nel 1,1% e 1,2%, schema.org/imagegallery nello 0,9% e 1,1%, schema.org/product nell’1,0% e 1,1%, schema.org/offer nello 0,9% e 1,0%, schema.org/listitem nello 0,9% e 1,0%, schema.org/breadcrumblist nello 0,9% e nell’1,0% e infine schema.org/article è stato utilizzato nello 0,8% delle pagine desktop e mobili.Questi incrementi sono comuni anche per i desktop, con leggere diminuzioni altrove come wpsidebar (che passa dall’1,4% all’1,2% nelle pagine per dispositivi mobili e dall’1,3% all’1,1% nelle pagine desktop), con una variazione minima nell’ultimo anno sia per le pagine mobili che per quelle desktop nel loro complesso.
JSON-LD
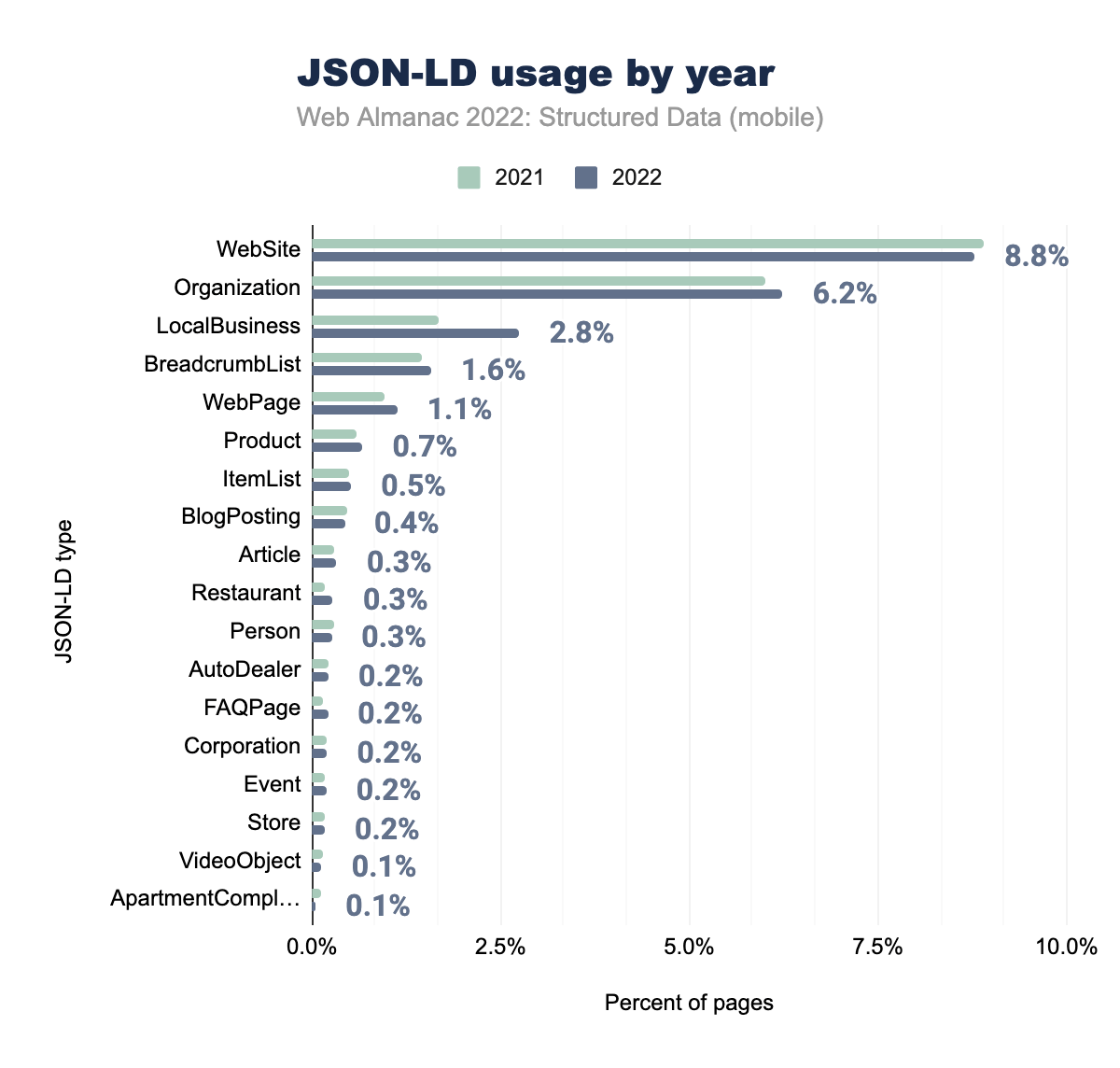
WebSite è stato utilizzato nell’8,9% delle pagine mobili nel 2021 e nell’8,8% nel 2022, Organization rispettivamente nel 6,0% e nel 6,2%, LocalBusiness nell’1,7% e nel 2,8%, BreadcrumbList nell’1,5% e 1,6%, WebPage nel 1,0% e 1,1%, Product nel 0,6% e 0,7%, ItemList nel 0,5% e 0,5%, BlogPosting nel 0,5% e 0,4%, Article nel 0,3% e 0,3%, Restaurant nello 0,2% e 0,3%, Person nello 0,3% e 0,3%, AutoDealer nello 0,2% e 0,2%, FAQPage nello 0,1% e 0,2%, Corporation nello 0,2% e 0,2%, Event nello 0,2% e 0,2%, Store nello 0,2% e 0,2%, VideoObject nello 0,2% e 0,1% e infine ApartmentComplex nello 0,1% nelle pagine mobili sia nel 2021 che nel 2022.I tipi JSON-LD continuano ad essere per lo più simili all’anno precedente con però alcuni notevoli incrementi. Vale a dire, questi sono LocalBusiness(che è aumentato raggiungendo il 2,8% delle pagine nel nostro set) e Restaurant (che è aumentato a quota 0,3% delle pagine nel nostro set).
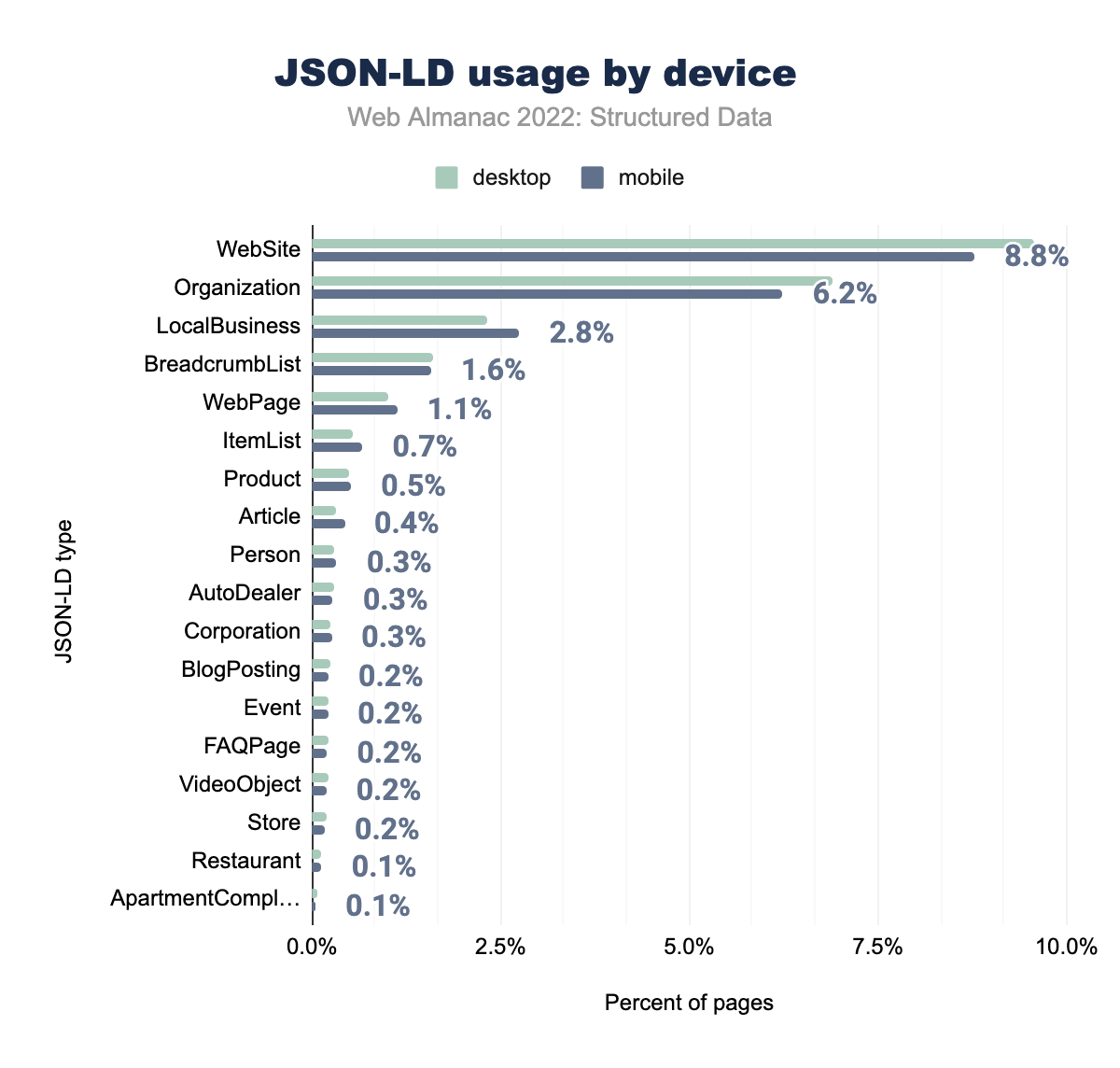
WebSite è stato utilizzato nel 9,6% delle pagine desktop e nell’8,8% delle pagine mobili, Organization rispettivamente nel 6,9% e 6,2%, LocalBusiness nel 2,3% e 2,8%, BreadcrumbList nell’1,6% e nell’1,6% , WebPage nel 1,0% e 1,1%, Product nel 0,5% e 0,7%, ItemList nel 0,6% e 0,5%, BlogPosting nel 0,2% e 0,4%, Article nel 0,3% e 0,3% , Restaurant nello 0,1% e 0,3%, Person nello 0,3% e 0,3%, AutoDealer nello 0,3% e 0,2%, FAQPage nello 0,2% e 0,2%, Corporation nello 0,2% e 0,2% , Event nello 0,2% e 0,2%, Store nello 0,2% e 0,2%, VideoObject nello 0,2% e 0,1% e infine ApartmentComplex è stato utilizzato nello 0,1% delle pagine desktop e mobili.Questi incrementi sono sufficienti per consacrare i tipi JSON-LD come il secondo più grande cambiamento positivo dal 2021, con un passaggio dal 33,5% al 36,5% delle pagine mobili nel nostro set e dal 34,1% al 36,9% delle pagine desktop.
Relazioni JSON-LD
Quando valutiamo JSON-LD, possiamo concentrarci sui modelli più ricorrenti di relazioni tra le diverse classi. Più di altre sintassi, la forma con JSON-LD esprime il valore dei grafi nei dati strutturati. Un Article (articolo), ad esempio, è spesso caratterizzato da un’Image(immagine) collegata e dal tipo di entità Person (persona) per rappresentare il suo Author (autore). Allo stesso modo, vedremmo che BlogPosting è anche connesso con Image(immagine), ma più spesso con l’Organization (organizzazione) che funge da Publisher (editore).
Alcuni tipi di dati sono puramente sintattici come BreadcrumbList (elenco-a-briciole-di-pane) che viene utilizzato esclusivamente per collegare diversi elementi (itemListElement) del sistema di navigazione di un sito o una Question (domanda) che è tipicamente collegata alla sua acceptedAnswer (risposta). Altri elementi riguardano i significati: un LocalBusiness (attività-locale) è tipicamente legato ad un address (indirizzo) e agli openingHoursSpecification (orari-di-apertura).
Con questa analisi vogliamo condividere una panoramica a volo d’uccello dei tipi più comuni di relazioni tra entità e delle sottili differenze tra, diciamo, Article e BlogPosting.
Qui di seguito possiamo vedere i collegamenti comuni tra i diversi tipi, in base alla frequenza con cui si verificano all’interno di tutti i valori di struttura/relazione. Alcune di queste strutture fanno tipicamente parte di catene di relazioni più ampie.

WebPage è l'elemento “Da” più grande che si dirama a più tipi di “Relazione” e risultati “A” (ad esempio WebPage -> PotentialAction -> SearchAction). Questo è seguito da WebSite, quindi Organization, Product, BreadCrumblist, BlogPosting e quindi un elenco di altri elementi utilizzato in modo decrescente. Della colonna centrale “Relazioni” viene utilizzata maggiormente PotentialAction, seguita da ItemListElement, IsPartOf, Publisher, image e quindi una lunga coda simile di utilizzi in progressiva diminuzione. La colonna “A” ha ImageObject come il più utilizzato in alto, seguito da Organization, SearchAction, ListItem, WebSite, WebPage e poi, di nuovo, una coda anche più lunga di ogni utilizzi sempre meno frequenti. Il senso generale suggerito dal grafico è una gran quantità di relazioni diverse con un elevato uso incrociato tra le tre colonne.L’analisi fornisce anche una panoramica degli ambiti verticali alla base di questi costrutti: dalle notizie e dai media all’e-commerce, dalle attività locali agli eventi e così via.
Qui sotto possiamo vedere gli stessi dati in modo interattivo con l’attributo sorgente a sinistra e la classe target a destra.

itemListElement a ListItem, da isPartOf a Website, da potentialAction a SearchAction e ReadAction e da image, logo e primaryImageOfPage a ImageObject, seguito da un lungo elenco di relazioni meno utilizzate.Il limite principale di questa analisi è rappresentato dal fatto che possiamo valutare le catene di relazioni a livello di home page.
SameAs
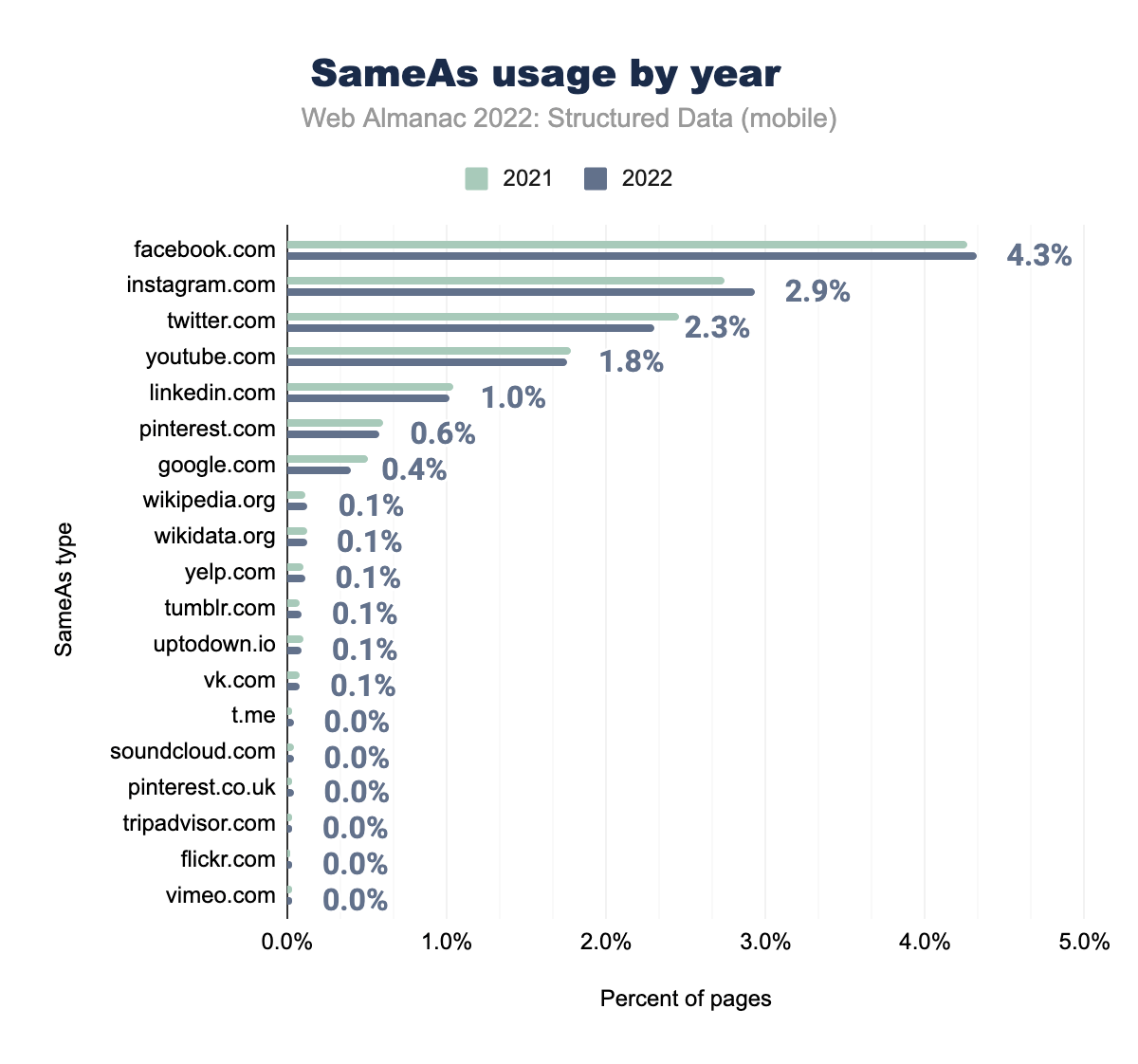
WebSite è stato utilizzato nel 4,3% delle pagine mobili sia nel 2021 che nel 2022, instagram.com rispettivamente nel 2,7% e nel 2,9%, twitter.com nel 2,5% e nel 2,3%, youtube.com nel 1,8% e 1,8%, linkedin.com nel 1,0% e 1,0%, pinterest.com nello 0,6% e 0,6%, google.com nello 0,5% e 0,4%, wikipedia.org nello 0,1 % e 0,1%, wikidata.org nello 0,1% e 0,1%, yelp.com nello 0,1% e 0,1%, tumblr.com nello 0,1% e 0,1%, uptodown.io nello 0,1% e 0,1%, vk.com nello 0,1% e 0,1% e t.me, soundcloud.com, pinterest.co.uk, tripadvisor.com, flickr.com e vimeo.com sono stati tutti utilizzati nello 0,0% delle pagine mobili sia nel 2021 che nel 2022.SameAs (dispositivi mobili)
Come nel 2021, i valori più comuni della proprietà sameAs sono le piattaforme di social media. Queste includono facebook.com (al 4,32% su mobile e 4,94% su desktop), instagram.com (al 2,93% su mobile e 3,34% su desktop) e twitter.com (al 2,30% su mobile e 2,86% su desktop). I primi due fra questi hanno visto un leggero aumento sui dispositivi mobili dal 2021, e tutti e 3 in aumento sul desktop.
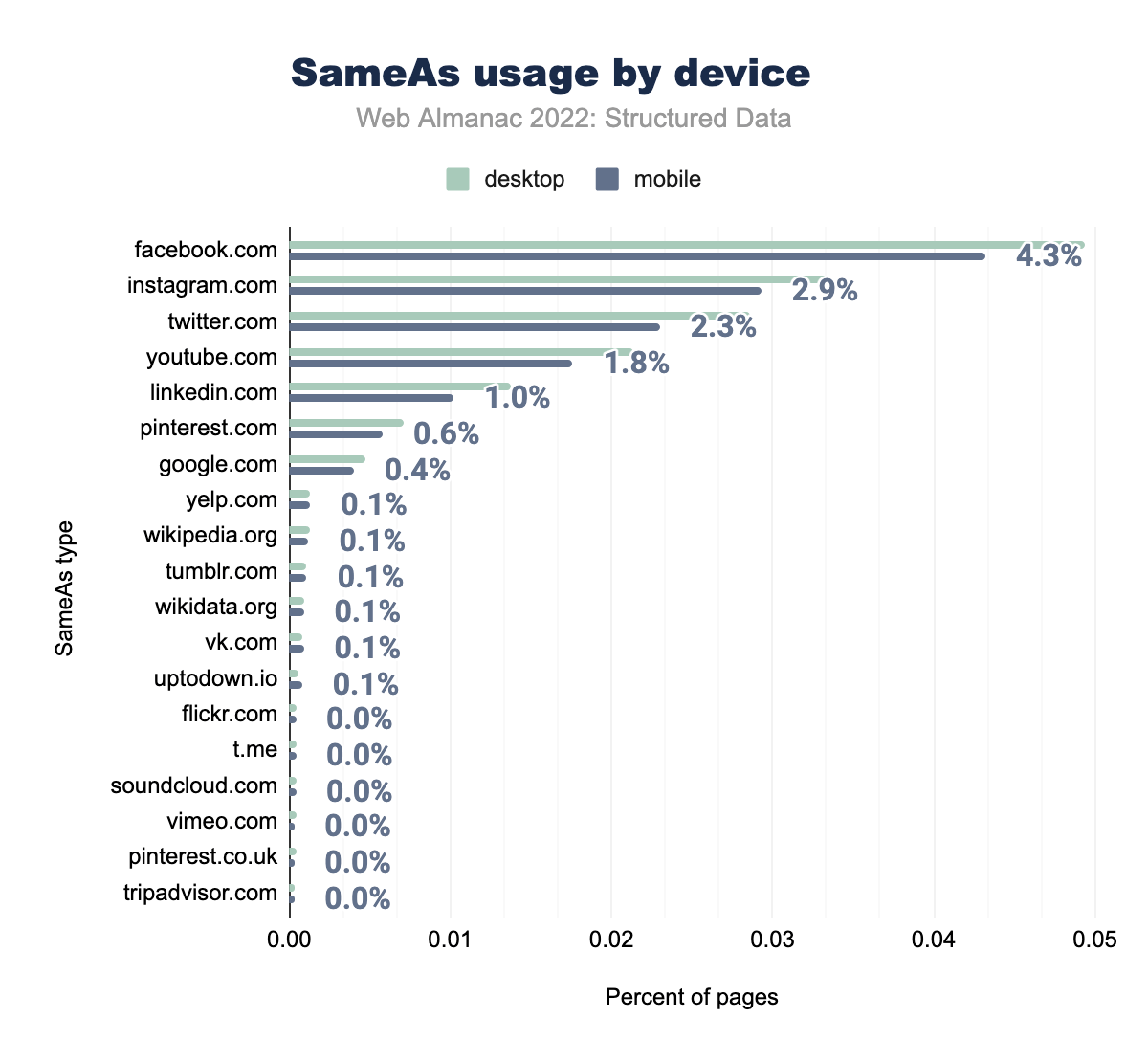
facebook.com è stato utilizzato nel 4,9% delle pagine desktop e nel 4,3% delle pagine mobili, instagram.com rispettivamente nel 3,3% e nel 2,9%, twitter.com nel 2,9% e nel 2,3%, youtube.com nel 2,1% e 1,8%, linkedin.com nel 1,4% e 1,0%, pinterest.com nello 0,7% e 0,6%, google.com nello 0,5% e 0,4%, wikipedia.org nello 0,1% e 0,1%, wikidata.org nello 0,1% e 0,1%, yelp.com nello 0,1% e 0,1%, tumblr.com nello 0,1% e 0,1%, uptodown.io nello 0,1% % e 0,1%, vk.com nello 0,1% e 0,1% e t.me, soundcloud.com, pinterest.co.uk, tripadvisor.com, flickr.com e vimeo.com sono stati tutti utilizzati nello 0,0% delle pagine desktop e mobili.SameAs per dispositivo
Il resto dell’elenco include fonti di informazione come wikipedia.org (allo 0,13% sia su dispositivi mobili che desktop) e yelp.com (allo 0,11% su dispositivi mobili e 0,13% su desktop), entrambi in aumento rispetto all’anno precedente.
Ulteriori approfondimenti JSON-LD - modifiche relative
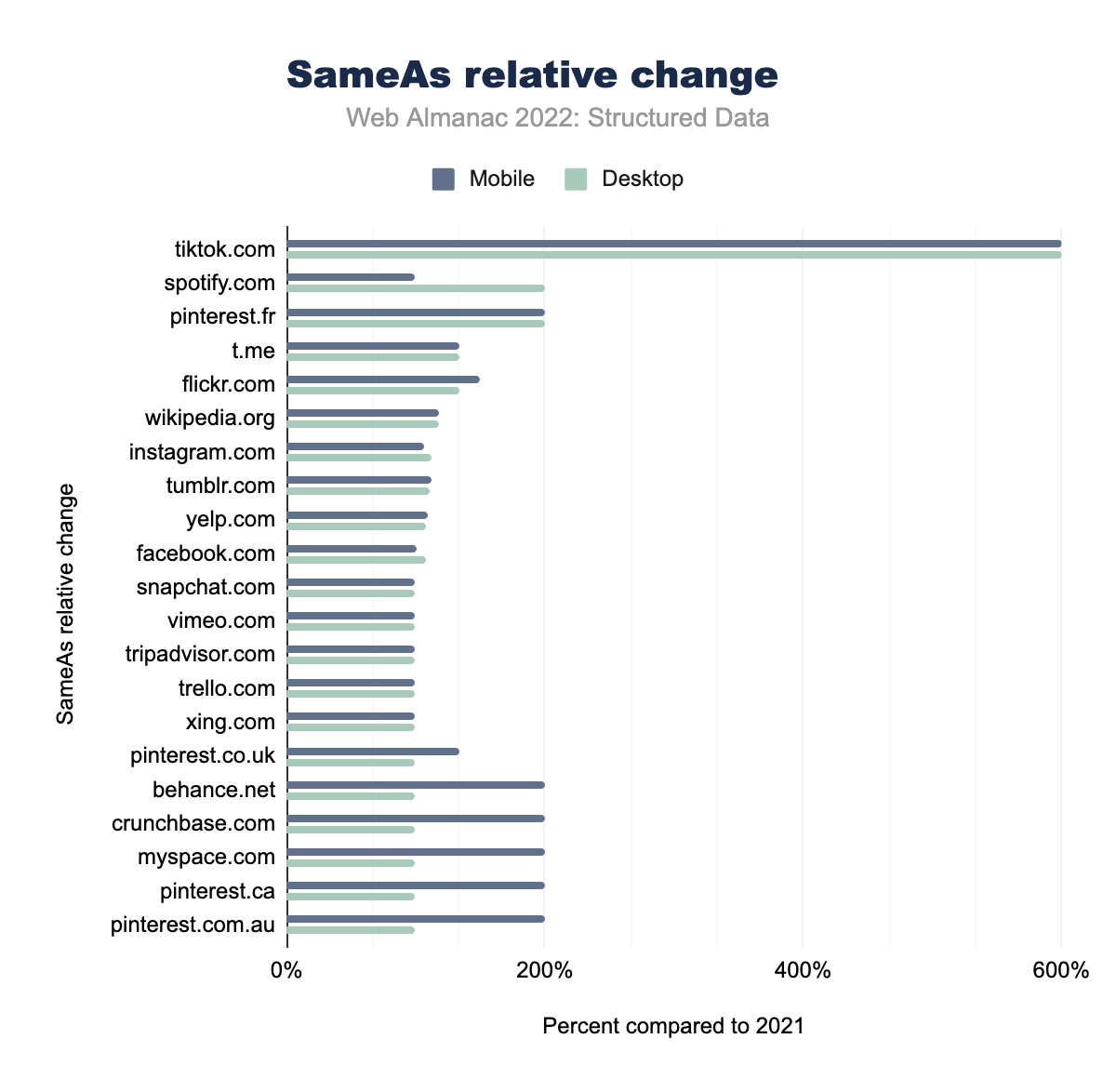
tiktok.com è cambiato del 600% nelle pagine sia desktop che mobili, spotify.com del 100,00% su desktop e del 200,00% su dispositivo mobile, pinterest.fr rispettivamente del 200,00% e del 200,00%, t.me del 133,33% e 133,33%, flickr.com del 150,00% e 133,33%, wikipedia.org del 118,18% e 118,18%, instagram.com del 106,93% e 112,46%, tumblr.com del 112,50% e del 111,11%, yelp.com del 110,00% e del 108,33%, facebook.com del 101,41% e del 107,39%, snapchat.com del 100,00% e del 100,00%, vimeo.com del 100.00% e 100.00%, tripadvisor.com del 100.00% e 100.xing.com del 100.00% e 100.00%, pinterest.co.uk del 133,33% e 100,00%, behance.net, crunchbase.com, myspace.com, pinterest.ca e pinterest.com.au sono tutti cambiati del 200,00% su desktop e del 100,00% su dispositivi mobili .SameAs
È interessante osservare le voci SameAs e come esse cambiano nel tempo. TikTok ha registrato un enorme aumento con il 2022 che ha visto la sua apparizione in un numero di pagine sei volte superiore rispetto al nostro set del 2021. Questa modifica è uguale sia per le pagine desktop che per quelle mobili. Pinterest e i vari nomi di dominio che ha, compensano 3 delle prime 5 maggiori crescite per le pagine mobili nel 2022. Il mobile nel complesso ha visto un aumento maggiore per le voci SameAs rispetto al desktop, con Spotify che fa eccezione con le occorrenze nelle pagine desktop raddoppiate rispetto al 2021.
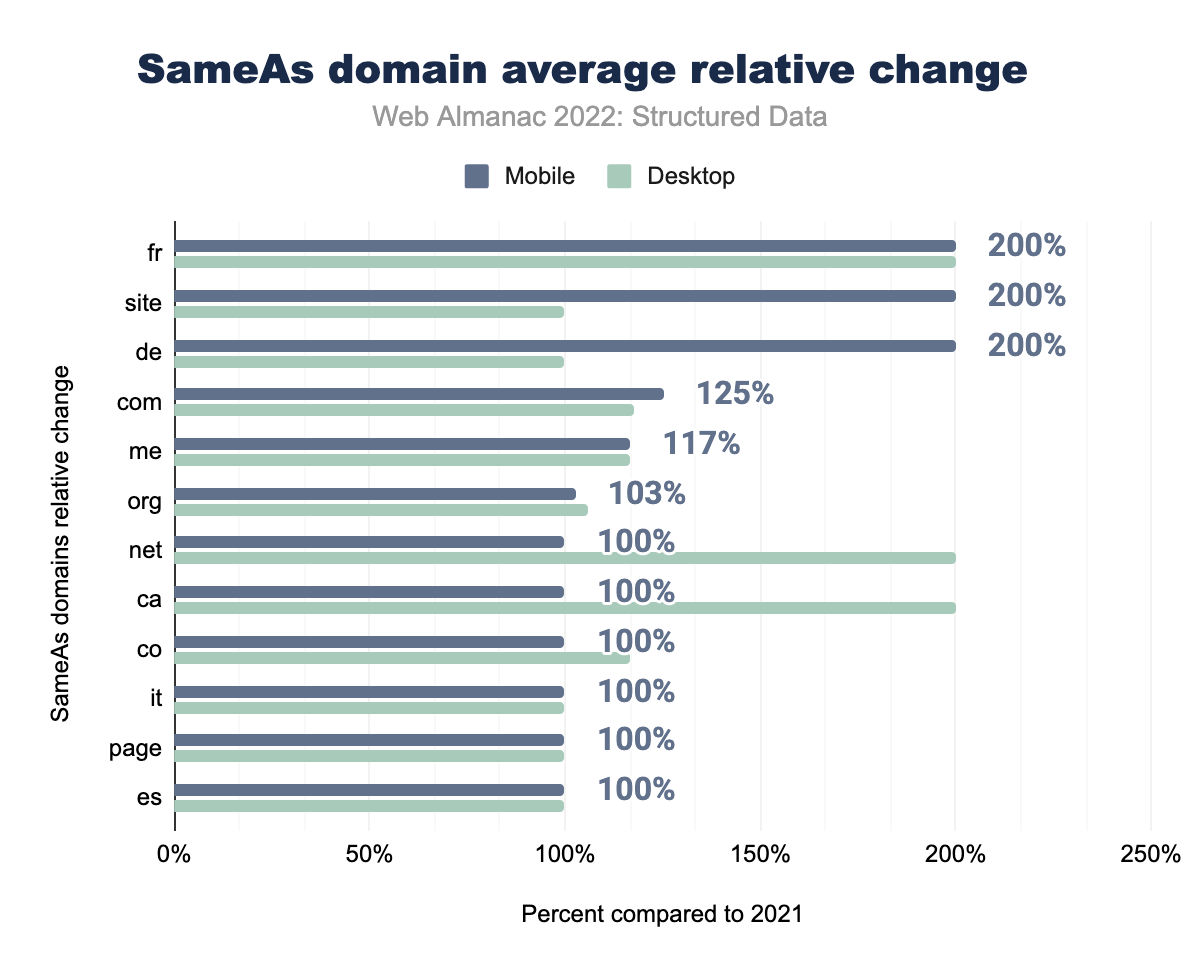
fr modificato del 200% sia nelle pagine desktop che da quelle per dispositivi mobili, site del 200,00% su desktop e del 100,00% su dispositivi mobili, de rispettivamente del 200% e del 100%, com del 125% e 118 %, me del 117% e 117%, org del 103% e 106%, net del 100% e 200%, ca del 100% e 200%, co del 100% e 117 %, e infine it, page e es del 100% sia su desktop che su dispositivi mobili.SameAs
Anche esaminare i nomi di dominio delle voci SameAs e il modo in cui cambiano nel tempo può fornire informazioni preziose. Nel gruppo con maggiore crescita in pagine desktop vediamo .ca, .net e .fr, con quest’ultimo che si trova anche nella parte con incrementi maggiori nelle pagine mobili. Poiché si tratta di una media, la quantità di voci non viene contabilizzata. In entrambi gli anni .com è molto più numeroso di tutte le altre voci, ma la variazione media è del 125% per le pagine mobili e del 117% per le pagine desktop. Le medie dei domini canadesi e francesi sono fortemente spinte da Pinterest, che, come accennato in precedenza, ha registrato aumenti ovunque rispetto allo scorso anno. In effetti, 7 dei primi 10 domini SameAs in crescita hanno Pinterest nelle loro voci, che a volte è la loro unica voce.
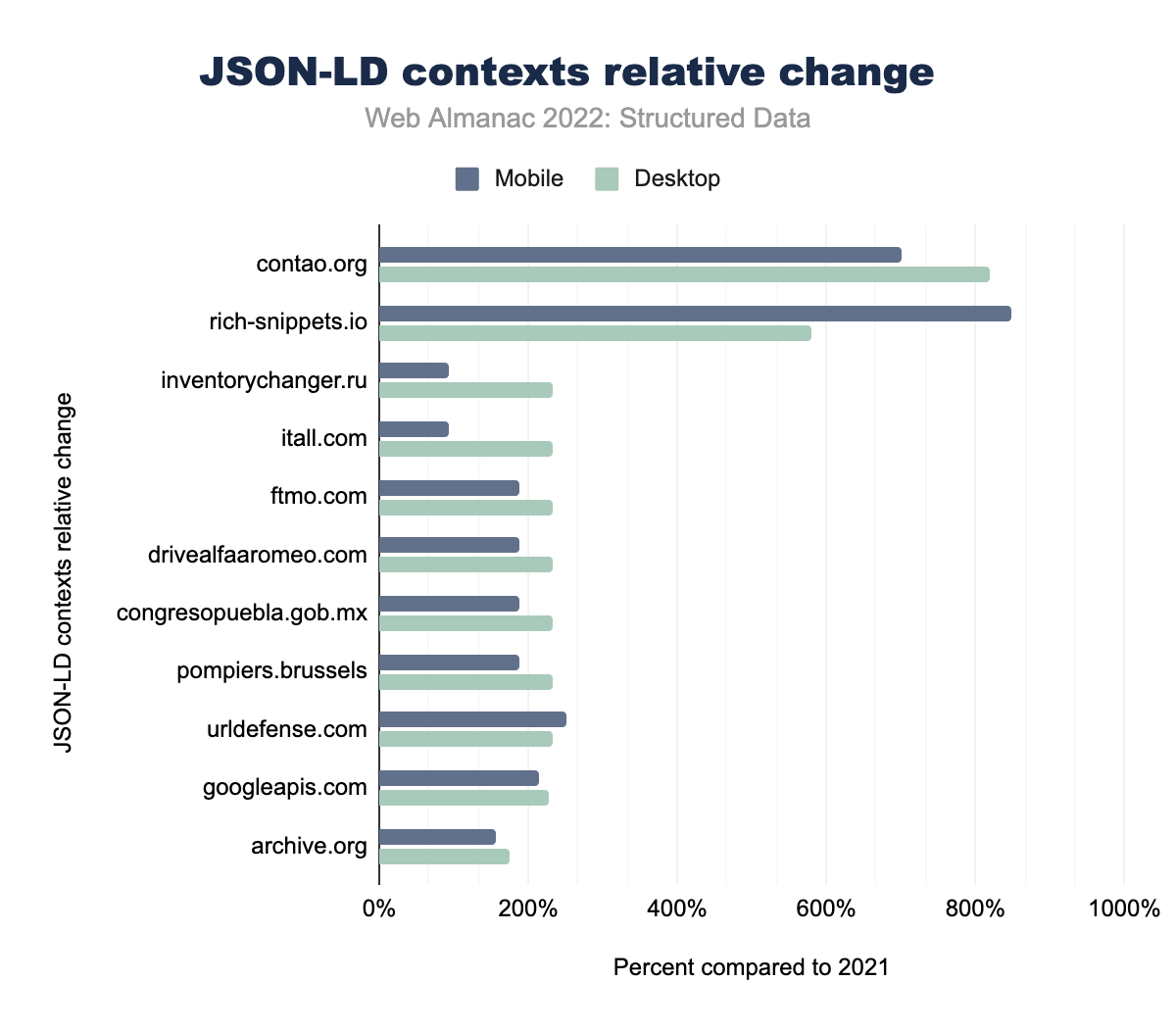
contao.org ha avuto un aumento dell’819% su desktop e del 701% su mobile, per contao.org è stato rispettivamente dell’819% e del 701%, per rich-snippets.io del 579% e 849%, per inventorychanger.ru 232% e 94%, per itall.com 232% e 94%, per ftmo.com 232% e 189%, per drivealfaaromeo.com 232% e 189% , per congresopuebla.gob.mx 232% e 189%, per pompiers.brussels 232% e 189%, per urldefense.com 232% e 252%, per googleapis.com 227% e 214%, e infine per archive.org c’è stato un aumento del 174% su desktop e del 157% su mobile.Per i contesti JSON-LD, schema.org è di gran lunga il maggior contributore, con oltre 6.000 volte il numero di occorrenze in pagine desktop e oltre 3.500 volte il numero di occorenze in pagine mobili rispetto al secondo contributore, googleapis.com. Detto questo, le occorrenze di googleapis.com sono più che raddoppiate sia per le pagine desktop che per quelle mobili, a differenza del modesto aumento di schema.org al 108% dei valori dello scorso anno. In termini di maggior crescita, contao.org e rich-snippets.io occupano i primi posti con l’aumento dell’819% nelle pagine desktop di contao.org e l’aumento dell’849% nelle pagine mobili di rich-snippets.io. Contao.org è al 4° posto nel totale delle voci, mentre rich-snippets.io è all’8° posto.
Conclusione
Molto è stato mostrato su come i dati strutturati influenzano il web e, per estensione, la nostra esperienza. Quest’anno, in più, ci siamo concentrati sul confronto di come è cambiata l’adozione dei dati strutturati nel corso di un anno. Abbiamo potuto vedere, ad esempio, l’aumento generale di alcune classi come LocalBusiness (in particolare per i ristoranti) o FAQ e la leggera diminuzione dell’utilizzo di alcuni dei tipi di dati strutturati meno rilevanti che provengono da foaf o dalla sintassi dei microdati.
Sebbene lungi dall’essere un elenco completo, notiamo che i dati strutturati (collegati) apportano diversi vantaggi a:
- Pagine di e-commerce
- Pagine aziendali
- Ricercatori
- Siti di social media
- Utenti
Spingono l’adozione i fini SEO, una maggiore trovabilità, il collegamento fra dati e i risultati arricchiti. L’implementazione del markup semantico all’interno delle pagine web si traduce in un web più connesso e accessibile.
Con informazioni e approfondimenti più disponibili che mai, è essenziale comprendere le capacità e i limiti di tecniche o di scelte specifiche quando si cerca di aumentare il traffico di una pagina web. L’aggiunta di recensioni false o dati fuorvianti nella speranza di migliorare la SEO verrà facilmente scoperta, con conseguenti minori benefici dei soggetti sopra menzionati e minore trovabilità e prestazioni da parte dei motori di ricerca.
Come già visto nell’anno precedente, sebbene la SEO rimane un driver cruciale per l’adozione di dati strutturati, sta emergendo un panorama crescente di casi d’uso al di là dei motori di ricerca. I proprietari di siti web stanno aggiungendo dati in diversi scenari per rendere i loro sistemi interoperabili, addestrare i loro sistemi di suggerimento dei contenuti e ottenere nuove informazioni dalle pagine web.
Anche se questo è solo il secondo anno in cui compare questo capitolo nel Web Almanac, siamo felici di vedere come queste tendenze si confermano e cambiano in seguito allo stato dei dati strutturati sul web. Con tutti i vantaggi che i dati strutturati offrono, prevediamo un’implementazione crescente di queste tecnologie.

