Structured data
Introduction
We find ourselves at a critical moment in the evolution of the semantic web. AI is becoming widely accessible and integrated into many of our day-to-day applications. Now, in its third year, this chapter provides a unique opportunity to analyze the past year’s trends and examine the rapid developments occurring over time. Looking at the previous editions, we can offer a comprehensive view of where structured data stands today and where it’s headed.
The expanding landscape of structured data
Over the past 18 months, there have been significant changes in the structured data landscape. In 2023, Google deprecated rich results for FAQs and HowTos from its search engine results pages (SERP) (source). In November 2024, Google will also remove the sitelinks search box from search results (source). However, in parallel, there has been a new wave of innovation and expansion in using structured data from both Google and Bing.
Key developments in 2023-2024:
-
New structured data types: Google introduced several new types, including Vehicle listings, Course info, Vacation Rentals, and 3D Models for products. Also, in the ecommerce space, Google has integrated loyalty programs into its structured data offerings, particularly through the Merchant Center and Schema.org.
-
Enhanced existing types: Improvements to organization data, product variants, and the introduction of discount-rich results.
-
Structured data carousels: The beta launch of structured data carousels, combining
ItemListwith other types, opens new content presentation possibilities on Google’s SERP (source). -
GS1 integrations: There has been increased support for GS1 standards such as the GS1 Digital Link, which aims to bridge the gap between physical and digital product information. This technology enables manufacturers and retailers to connect physical products to their digital identities through QR codes. When scanned, these codes provide access to comprehensive product information, enhancing transparency and customer engagement. Also, the
gs1:CertificationDetailsproperty has been officially adopted by Google asschema:Certification, demonstrating how industry-specific extensions can successfully influence and integrate with Schema.org standards. -
Semantic data beyond search applications: Structured data is now being leveraged beyond traditional search engines, playing a pivotal role in social web applications. For instance:
- Identity verification: Platforms like Mastodon use
rel=melinks for two-way identity verification (source). - Federated social networks: The use of
rel=meallows Mastodon users to verify their accounts with third-party websites (e.g., Ghost), strengthening cross-platform identity (discussion on rel=me with Ghost). - New journalism features: Mastodon recently introduced the
fediverse:creatorattribute to support content verification for journalists and publishers (source).
- Identity verification: Platforms like Mastodon use
Beyond traditional implementation
As the structured data ecosystem matures, we’re witnessing a diversification in implementation strategies. While search engines remain a primary consumer of structured data, its applications are expanding significantly:
-
Schema.org as markup: The traditional method of embedding structured data directly into webpages continues to be a cornerstone of modern SEO practices.
-
Schema.org as a data standard: Beyond its use in HTML, Schema.org is increasingly employed to standardize data shared via APIs or feeds. For example, Google’s Data Commons initiative uses an extended Schema.org vocabulary to integrate datasets from hundreds of organizations globally. This standardization supports tasks like dataset discovery and relationship mapping, crucial for understanding provenance, subsets, and derivations of datasets in AI-driven environments (source).
-
Semantic data in social web applications:
- Platforms like Mastodon leverage structured data for identity verification. The
rel=meattribute allows users to verify accounts across federated networks (source). - Features like
fediverse:creatorare being used to validate content and authorship, enhancing trust in the decentralized social web (source).
- Platforms like Mastodon leverage structured data for identity verification. The
-
Digital Product Passports (DPPs):
Structured data plays a key role in emerging regulatory requirements like the EU’s Digital Product Passports, designed to enhance transparency and sustainability in ecommerce. These passports leverage GS1 Digital Links to provide comprehensive product information through QR codes.
- Structured data for AI-powered Discovery:
As AI-powered search engines, chatbots, and conversational assistants continue to expand their reach, structured data plays a pivotal role in enhancing content discoverability and contextual understanding across these platforms. Key examples include:
- AI Search Engines: Platforms like Bing Chat and Google AI Overview utilize structured data not only to train their language models but also to deliver contextually rich and accurate responses. By leveraging structured data, these systems can interpret complex relationships between datasets, improve search relevance, and enable users to seamlessly navigate interconnected datasets (source).
These capabilities demonstrate structured data’s evolving role in not only improving discoverability but also in enhancing AI systems’ ability to interpret and act on relationships between data, thereby creating richer and more useful user experiences.
This diversification highlights structured data’s growing role in facilitating data interoperability, social trust, regulatory compliance, and AI-driven content discovery. By enabling systems to understand and act on complex relationships between data, structured data lays the foundation for richer, more intelligent digital experiences.
Structured data in the age of AI and machine learning
The rise of generative AI and advanced machine learning has further underscored the importance of structured data:
-
Fact validation: Structured data provides a parsable source for AI systems, enabling them to efficiently extract, interpret, and validate information. This helps:
- Combat misinformation: AI can cross-reference structured data with other trusted sources to validate facts.
- Improve content understanding: By offering clear entity definitions and relationships, structured data supports nuanced interpretation of complex topics.
- Enhance user experiences: Structured data allows AI systems, such as chatbots and voice assistants, to deliver accurate and context-rich responses to user queries.
- Enhanced search understanding: It enables a more nuanced interpretation of content by search engines and AI-powered systems.
- Training data: Well-structured data is high-quality training material for machine learning models.
What this chapter provides
This chapter offers a data-driven analysis of structured data trends in 2023-2024, highlighting key developments and best practices:
-
Evolution of the landscape:
- Key shifts in structured data, especially with the rise of AI-powered search like Google AI Overview and Bing Chat.
- Changes in Google and Bing structured data policies, and their impact on SEO.
-
Prevalence and growth:
- Trends in popular formats like JSON-LD, Microdata, and RDFa.
- Adoption rates by schema types such as
Product,Organization, andArticle.
-
Implementation and best practices:
- Best practices for structured data, including JSON-LD usage.
- Common mistakes and how to avoid them.
-
Rich results & SERP features:
- Effects of deprecated features like
FAQandHowTo. - Introduction of carousels and product knowledge panels.
- Effects of deprecated features like
-
AI-Powered search:
- The role of structured data in AI-driven search and voice assistants.
- Trends in AI-powered content discovery.
-
Ecommerce innovations:
- Growth of Digital Product Passports and GS1 Digital Links.
- Structured data’s role in ecommerce and new rich result types.
-
Knowledge graphs & Graph RAG:
- The rising importance of knowledge graphs and Graph RAG for enhancing AI outputs.
-
Quality & data integrity:
- Best practices for maintaining high-quality structured data.
-
Emerging schemas & use cases:
- Innovations in schema types and their application in SEO and ecommerce.
-
Future outlook:
- The evolving role of structured data in AI, semantic SEO, and content discovery.
This chapter provides a comprehensive view of structured data’s impact on SEO, AI, and ecommerce, with actionable insights for developers and marketers.
Key concepts
As structured data evolves in complexity, exploring and explaining key concepts is crucial before diving into a deeper analysis. This section outlines fundamental ideas and recent developments in the field.
Linked data and the semantic web
Linked data remains a cornerstone of structured data. By adding structured data to web pages and providing URI links to referenced entities, we create an interconnected web of information. This contributes to the semantic web, where data is linked through the Resource Description Framework (RDF), enabling machines to treat web pages as databases.
The concept of semantic triples (subject-predicate-object) continues to be fundamental in expressing relationships between entities. While SPARQL is a query language specifically designed for querying graph data and RDF triples, GraphQL serves as a flexible API query language for retrieving structured data from diverse backends, including databases and microservices. These tools complement each other: SPARQL excels in querying RDF datasets for semantic web applications, while GraphQL simplifies access to structured data for web and mobile applications.
Open data and the 5 stars model
Tim Berners-Lee’s 5 stars of the open data model remain relevant. It emphasizes the importance of web-available, structured, non-proprietary, URI-identified, and interlinked data. Structured data plays a crucial role in achieving higher levels of this model, contributing to a more open and interconnected web ecosystem.
AI-Powered search, voice assistants, and digital assistants
The landscape of search and digital assistance has dramatically evolved with the integration of AI, LLMs, and advanced natural language processing. This convergence has blurred the lines between traditional search engines, voice-activated systems, and AI-powered digital assistants.
Semantic search engines and AI-powered search
Semantic search has progressed beyond traditional keyword matching to include sophisticated AI-powered experiences. These systems leverage structured data to provide more accurate, contextual, and often conversational search results. Key developments include:
- Google AI Overview: A feature that provides comprehensive (sometimes misleading) AI-generated summaries on complex topics.
- Microsoft Bing Chat: Integrates chat-based AI interactions directly into Bing search results.
- Meta AI: Meta’s AI assistant is integrated across platforms like Facebook, Messenger, Instagram, and WhatsApp.
- SearchGPT (and ChatGPT): OpenAI’s AI search engine that integrates search results into conversational responses.
- Perplexity.ai: An AI-powered search engine that provides detailed, sourced answers to queries.
- You.com: Offers AI-summarized search results and a chat interface for more interactive searching.
These platforms demonstrate an enhanced ability to understand user intent and context, significantly improving search accuracy and user experience. They often combine traditional web indexing with real-time information retrieval and natural language generation.
The role of structured data
Structured data plays a crucial role in these AI-powered systems by:
- Enhancing entity recognition: Helping systems accurately identify and disambiguate entities mentioned in queries.
- Providing context: Offering additional information about entities and their relationships, improving response accuracy.
- Facilitating knowledge graph integration: Allowing these systems to tap into vast, interconnected information databases.
- Enabling rich responses: Supporting the generation of detailed, multi-faceted answers that often include visual elements or interactive features.
- Improving voice query interpretation: Assisting in understanding the intent behind spoken queries, which can be more ambiguous than text-based searches.
While it is still challenging to assess the impact of structured data on Generative AI and AI search engines, in some cases, such as geo-referencing queries, we can observe the early emergence of entities in the user experience of Perplexity.ai and You.com.
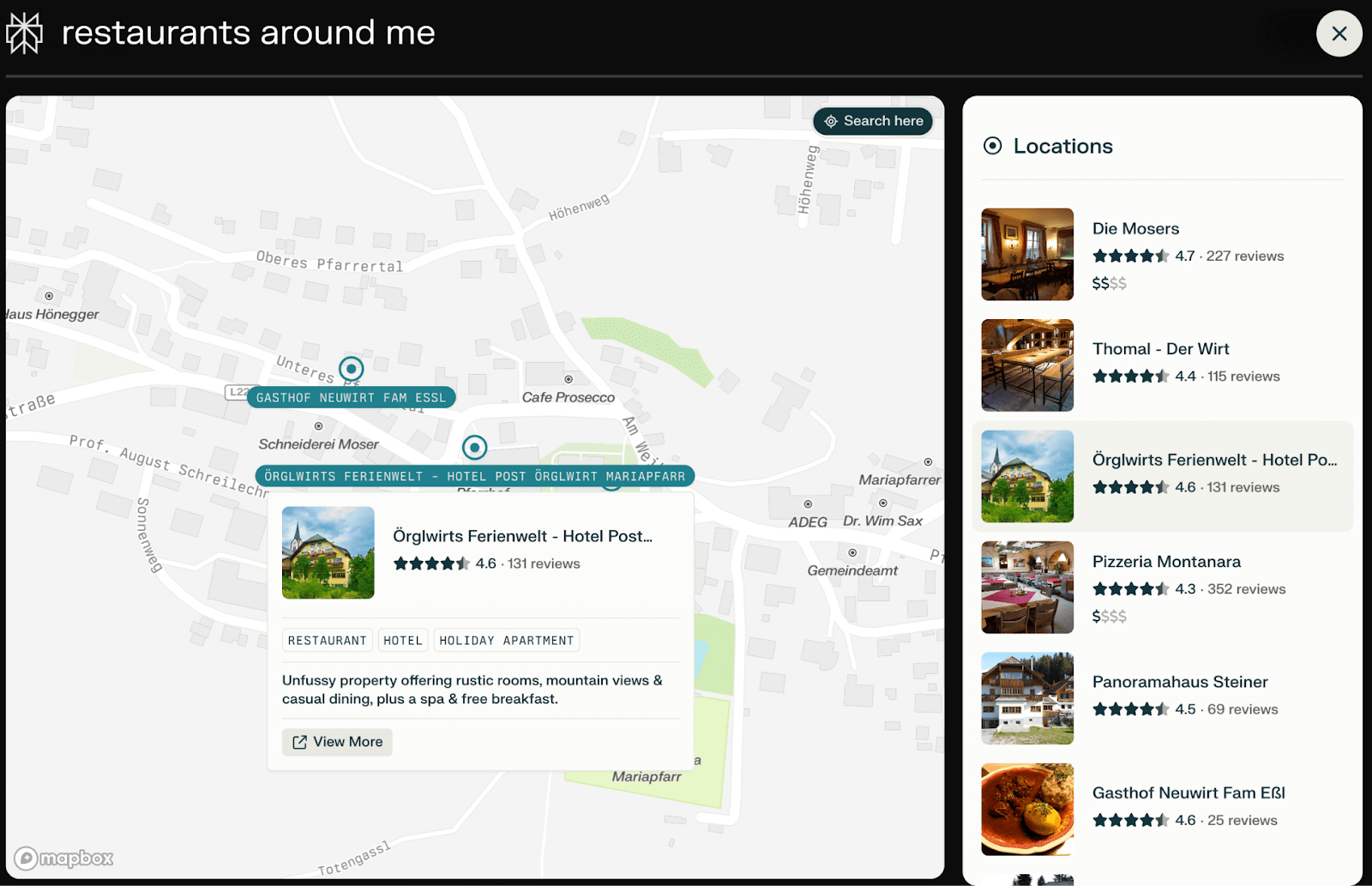
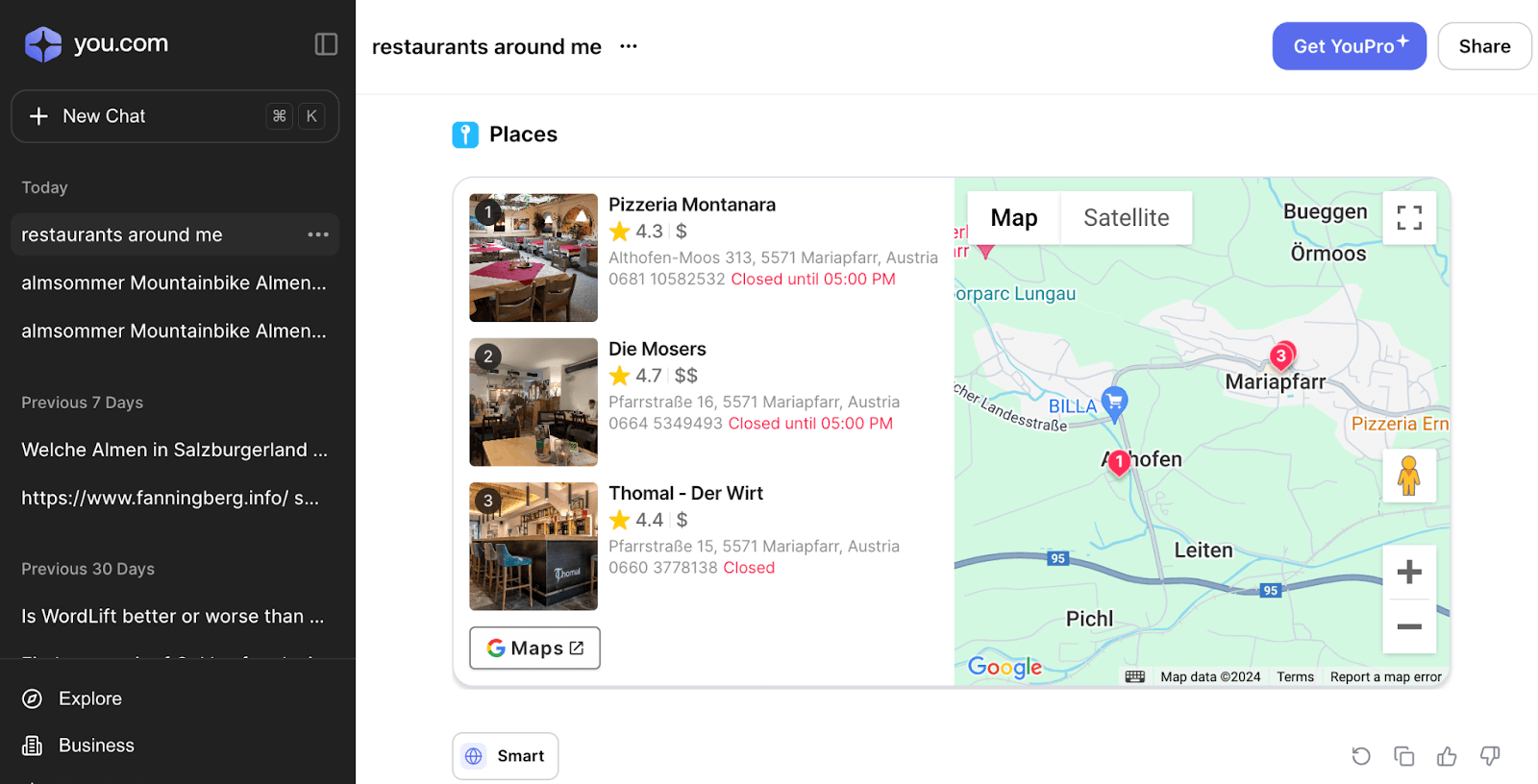
This is way more consistent when interacting with Bing Copilot or Gemini by Google.
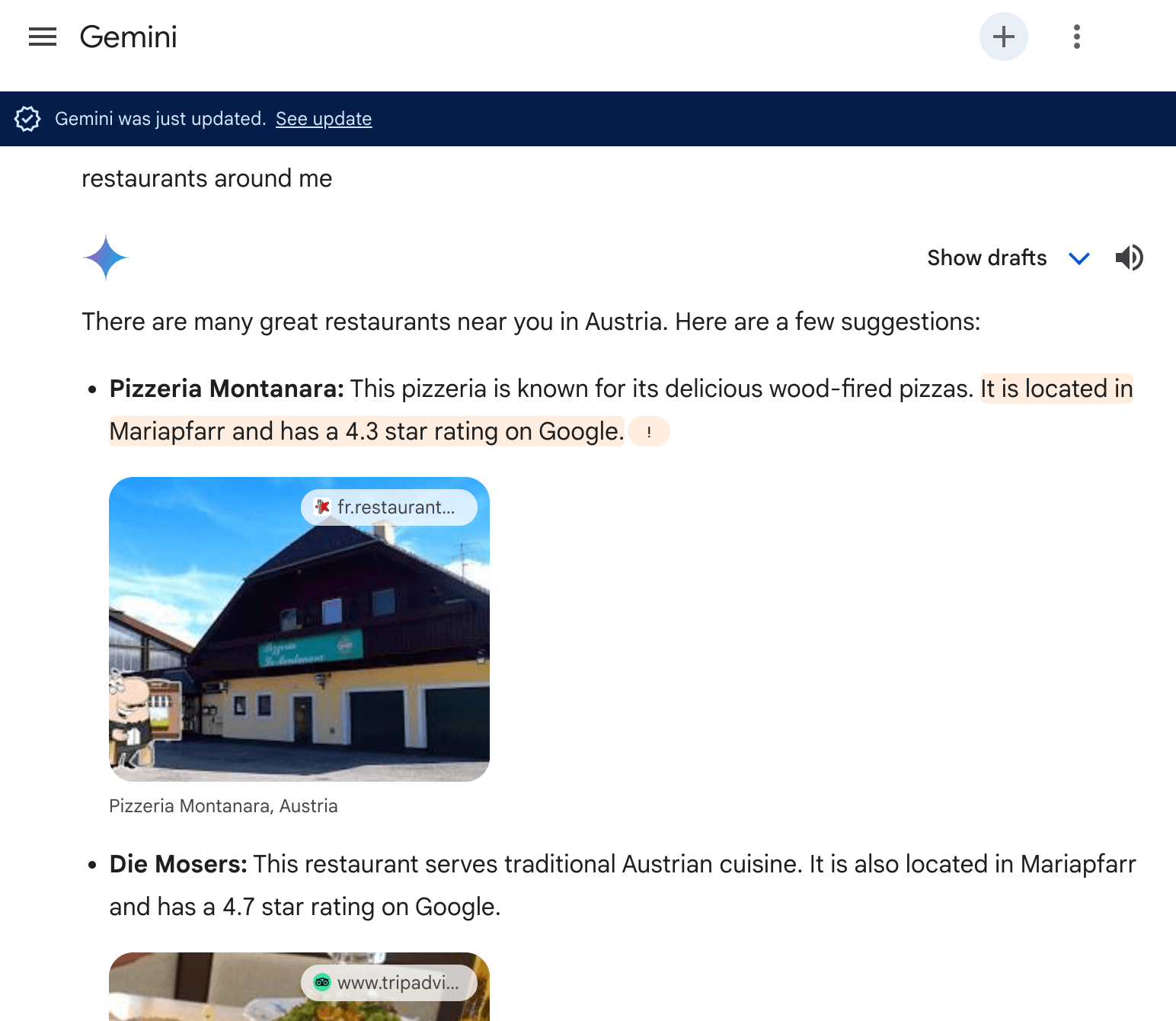
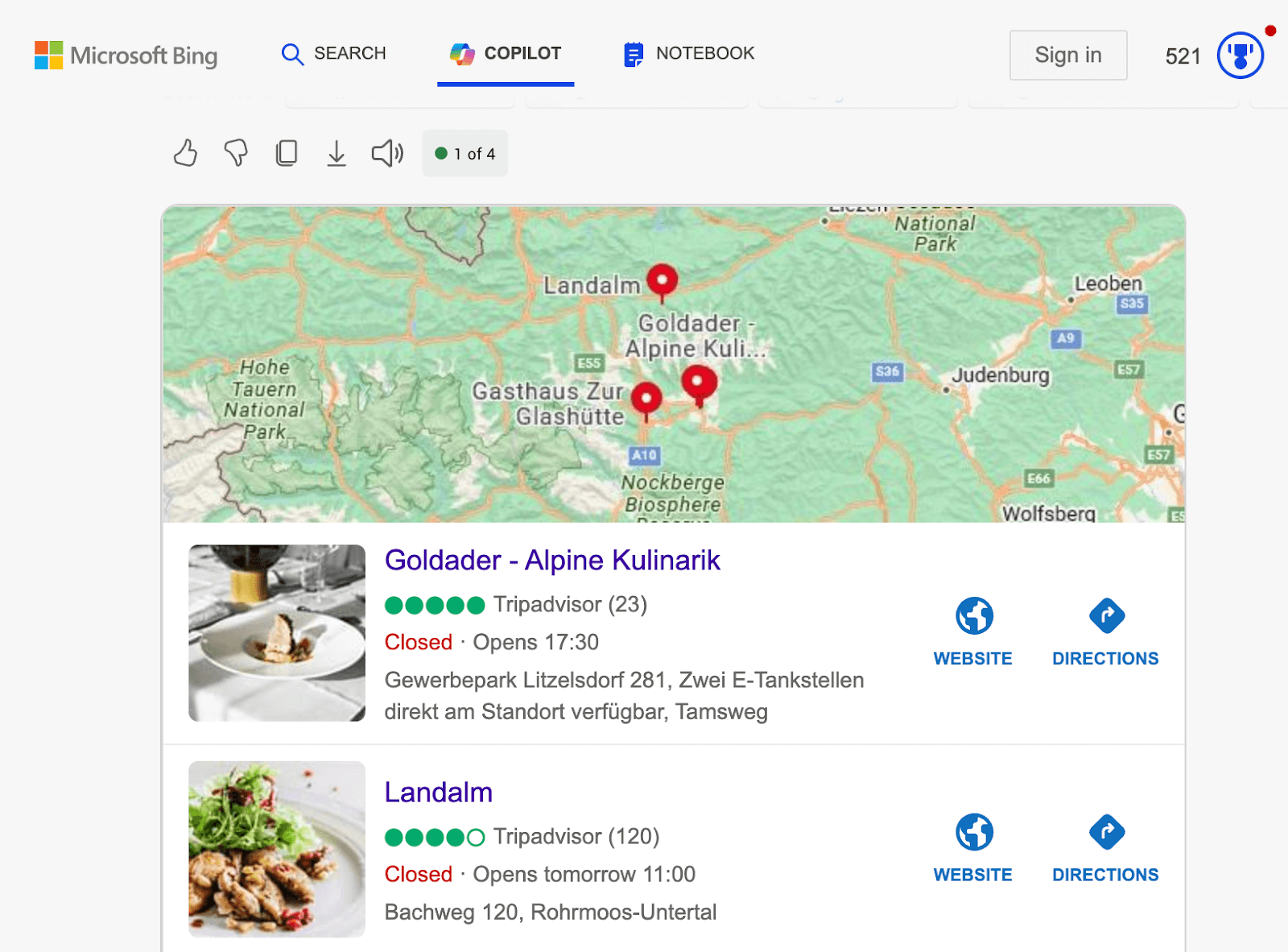
Empirically, AI-powered search systems, as seen above, are sourcing data from a variety of established knowledge bases and authoritative platforms:
- Map services: Google Maps and Bing Maps serve as crucial data sources for location-based information.
- Authoritative websites: Platforms rich in structured data markup, such as TripAdvisor, contribute significantly to the knowledge base of AI search systems.
- Vertical-specific databases: Industry-specific databases and platforms provide specialized information for AI-powered search in various sectors.
The shift to AI-powered search and its implications
This transition from traditional search to AI-powered search demands a broader, more nuanced approach to optimization:
-
Multi-platform visibility: SEO strategies must now account for visibility across a diverse array of AI surfaces and platforms, including:
- Traditional search engines (Google, Bing)
- AI chatbots (ChatGPT, Google’s Gemini, Perplexity, Anthropic’s Claude)
- Integrated assistants (Microsoft Copilot, potential Apple-ChatGPT integration)
- Ecosystem-specific tools (Google Workspace, Microsoft 365)
- Browser and device-level integrations
-
Beyond conventional optimization: Success in this landscape goes beyond optimizing for specific features like Google’s AI Overview. It requires a holistic approach to making content discoverable and comprehensible across all emerging search interfaces.
-
Leveraging structured data strategically: The key to improved visibility lies not just in publishing structured data using schema markup but in facilitating access to structured information about entities that matter to your business or content. This involves:
- Ensuring clear, structured information is available and easily interpretable by various AI systems.
- Ensuring that the metadata used to describe the webpage for bots is consistent with the content presented to human readers.
- Directly feeding accurate information to relevant platforms and marketplaces (e.g., Google Merchant, Amazon) for products and services.
Rich results and knowledge panels
Rich results and knowledge panels, powered by structured data, are essential features of search engine results pages (SERPs). These enhanced displays offer users immediate and relevant information, significantly boosting click-through rates and user engagement. As rich results become more diverse and sophisticated, they present new opportunities for content visibility. A recent example from Google is the introduction of a structured data carousel for listicle pages related to local businesses (including subtypes like restaurants, hotels, vacation rentals), products, and events.
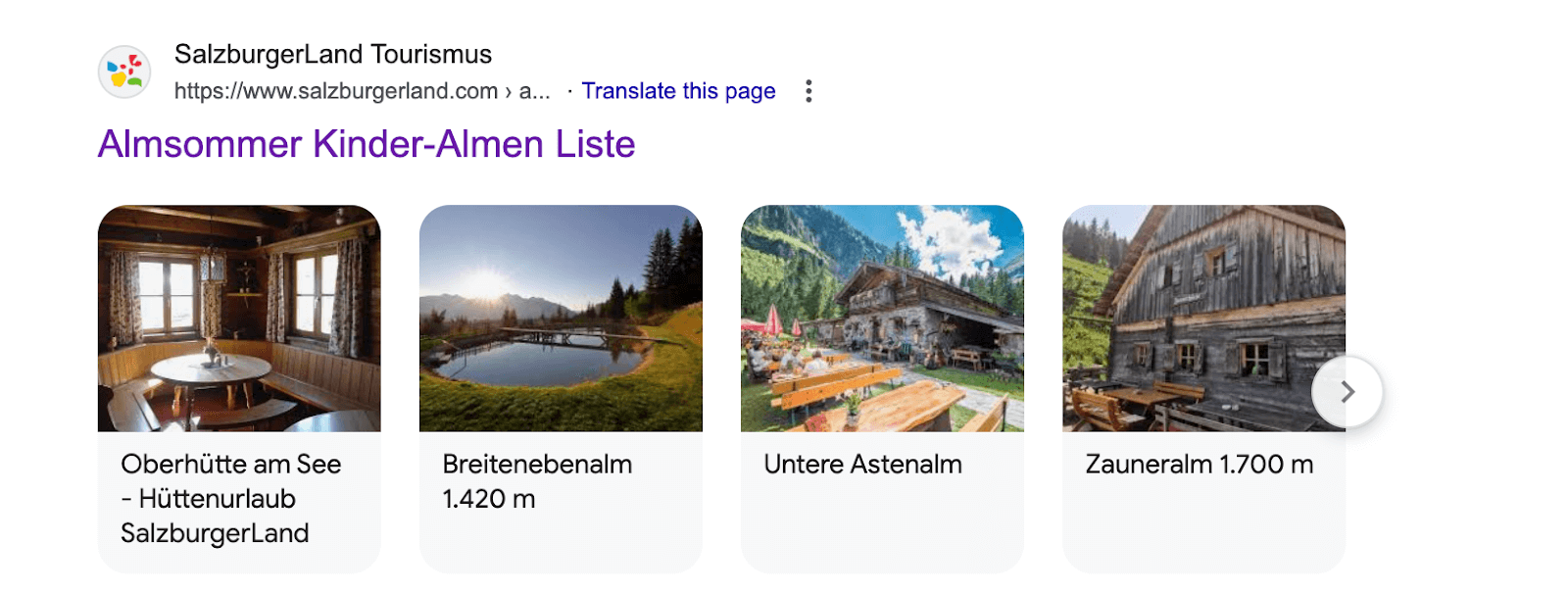
This carousel format enhances the display of structured data for listicle pages, offering users quick access to multiple options, such as local businesses or products, directly on the SERP.
Another notable example, while not directly influenced by structured data, is the new Google Merchant knowledge panel, which extends the functionality of the product knowledge graph panel. Structured data acts as a signal that contributes to entity disambiguation, helping search engines accurately identify businesses and their attributes, which can lead to the appearance of these panels. This feature helps businesses, both small and large, build trust with users by displaying key information about the merchant directly on Google’s search results page.
Knowledge graphs and Graph RAG
Knowledge graphs have become increasingly central to structured data applications, encapsulating factual information through precise, explicit triple representations (source). They provide a powerful way to represent and query complex relationships between entities while offering transparent symbolic reasoning capabilities . The emergence of Graph RAG (Retrieval-Augmented Generation) represents a significant advancement, combining knowledge graphs with large language models to enhance AI-generated responses with verifiable, structured information while addressing the challenges of factual inconsistencies and opacity inherent in LLMs.
Difference between Labeled Property Graphs and RDF graphs
Labeled Property Graphs (LPGs) and Resource Description Framework (RDF) graphs are two distinct approaches to organizing and representing data. LPGs, commonly used in databases like Neo4j, structure data with nodes and relationships, each carrying labels and properties. This allows for a flexible and intuitive way to model complex data relationships. On the other hand, RDF graphs, which are foundational to the semantic web, use a triple-based structure (subject-predicate-object) to represent data. RDF emphasizes interoperability and standardization, making it ideal for linking data across different systems and domains. While LPGs offer ease of use and performance for certain applications, RDF provides a robust framework for semantic data integration and reasoning.
The importance of structured data in creating knowledge graphs cannot be overstated. Structured data enables the precise definition of entities and their relationships, which is crucial for the development of accurate and reliable knowledge graphs. By leveraging structured data, organizations can build comprehensive knowledge graphs that enhance data discoverability, interoperability, and the overall quality of AI-generated insights.
Data Commons
Data Commons is an open-source and open-data initiative by Google that organizes public datasets from various global sources, such as the United Nations and national census bureaus, to make them universally accessible. The platform provides over 250 billion data points and 2.5 trillion triples, encompassing a wide range of statistical variables. Schema.org is utilized to encode structured data in Data Commons, creating a unified knowledge graph that standardizes and normalizes diverse datasets, enabling easier access and exploration through a common framework. This structured approach helps to integrate vast amounts of data into a coherent, searchable system.
Digital Product Passports and GS1 Digital Link
In the ecommerce and supply chain sectors, Digital Product Passports (DPPs) and the GS1 Digital Link standard are revolutionizing how product information is shared and accessed. These technologies leverage structured data to create comprehensive, easily accessible digital representations of physical products, enhancing traceability, sustainability efforts, and consumer information access.
AI, machine learning, and structured data
The synergy between structured data and AI/ML has deepened. Structured data is crucial in training machine learning models, providing consistent, machine-readable labels. It’s particularly important in areas such as:
- Large Language Models (LLMs): Fine-tuning with structured data for improved performance in specific domains.
- Explainable AI: Using knowledge graphs to trace and explain AI decision-making processes.
- Multimodal AI: Linking different data types (text, images, video) in AI systems.
Semantic SEO and data quality
SEO has evolved beyond simple keyword matching into what we now call Semantic SEO. This modern approach leverages structured data and contextual understanding to help search engines provide more accurate results. By implementing structured metadata and focusing on topical relationships, websites can build deeper meaning into their content. This allows search engines like Google and Bing to better understand user intent, rather than just counting keyword frequency.
By implementing semantic SEO, businesses can create content clusters based on topics, not just individual keywords, making their content more discoverable and contextually relevant across various search platforms, including voice search assistants. This approach significantly boosts search engine rankings and user engagement, as structured data allows search engines to understand the content at a more granular level, making it easier to match user intent.
Data quality plays a key role here as well. High-quality structured data ensures consistency and accuracy, which is crucial not only for search engines but also in combating misinformation. It helps maintain trustworthiness across the web, especially as structured data is increasingly used in AI-powered systems like knowledge graphs for fact validation and enhancing large language model (LLM) training.
For example, organizations such as EssilorLuxottica, L’Oréal, Wallmart, Shiseido and others are using semantic technologies like knowledge graphs to link content and provide users with more detailed, contextually relevant results. This practice also aids in AI-powered content discovery and makes content easier to retrieve through Generative Search like Perplexity or You.com.
Investing in semantic SEO and maintaining high-quality structured data not only enhances search visibility but also lays a foundation for future-proofing content for AI-driven discovery.
A year in review
The landscape of structured data implementation continues to evolve. To better understand this landscape, it’s essential to distinguish between syntax/encoding and vocabularies:
-
Syntax/encodings: These define how structured data is embedded into webpages:
- RDFa: Maintains a strong presence, used on 66% of pages.
- JSON-LD: Growing in popularity, implemented on 41% of pages.
- Microdata: Steady usage, appearing on 26% of pages.
- HEAD data: Includes non-RDFa meta tags like Twitter Cards.
-
Vocabularies: These define the meaning and semantics of the data:
- Open Graph Protocol (OGP): Widely used vocabulary, often encoded as RDFa (64% of pages).
- Twitter meta tags: Expanding rapidly, appearing on 45% of pages.
- Schema.org: Flexible vocabulary used across multiple syntaxes.
- Dublin Core: Niche use cases, typically encoded as RDFa.
- Microformats: Primarily implemented using class-based metadata.
Structured data usage trends (2022-2024)
The data reveals notable trends in both syntax and vocabulary usage:
- RDFa and Open Graph: Dominant, with adoption on 66% and 64% of pages, respectively.
- JSON-LD: Continues its upward trajectory, increasing from 34% in 2022 to 41% in 2024.
- Twitter meta tags (HEAD data): Significant growth, now at 45%.
- Microdata: Steady at 26%, primarily used in legacy contexts.
- Facebook meta tags: Declined to 7%, reflecting a shift to Open Graph.
- Dublin Core and Microformats: Minimal usage, each below 1%.
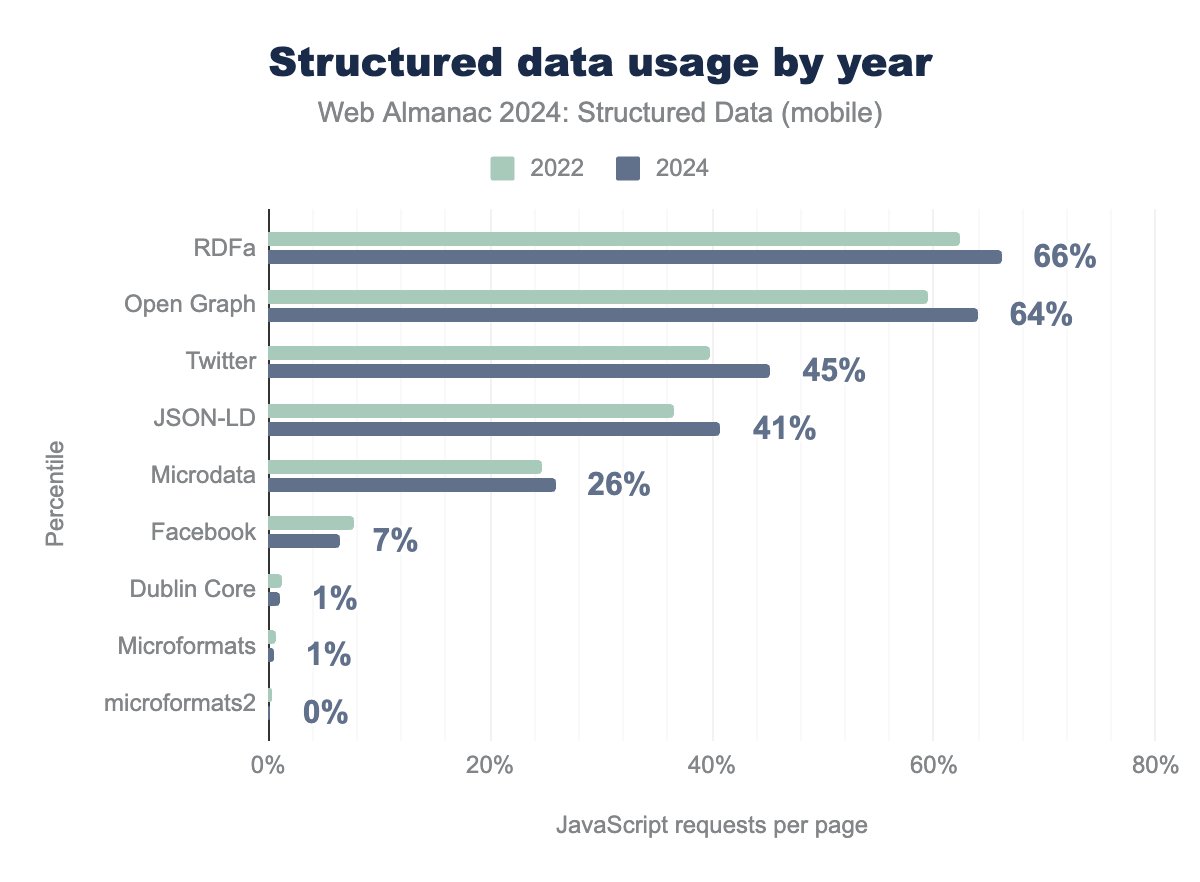
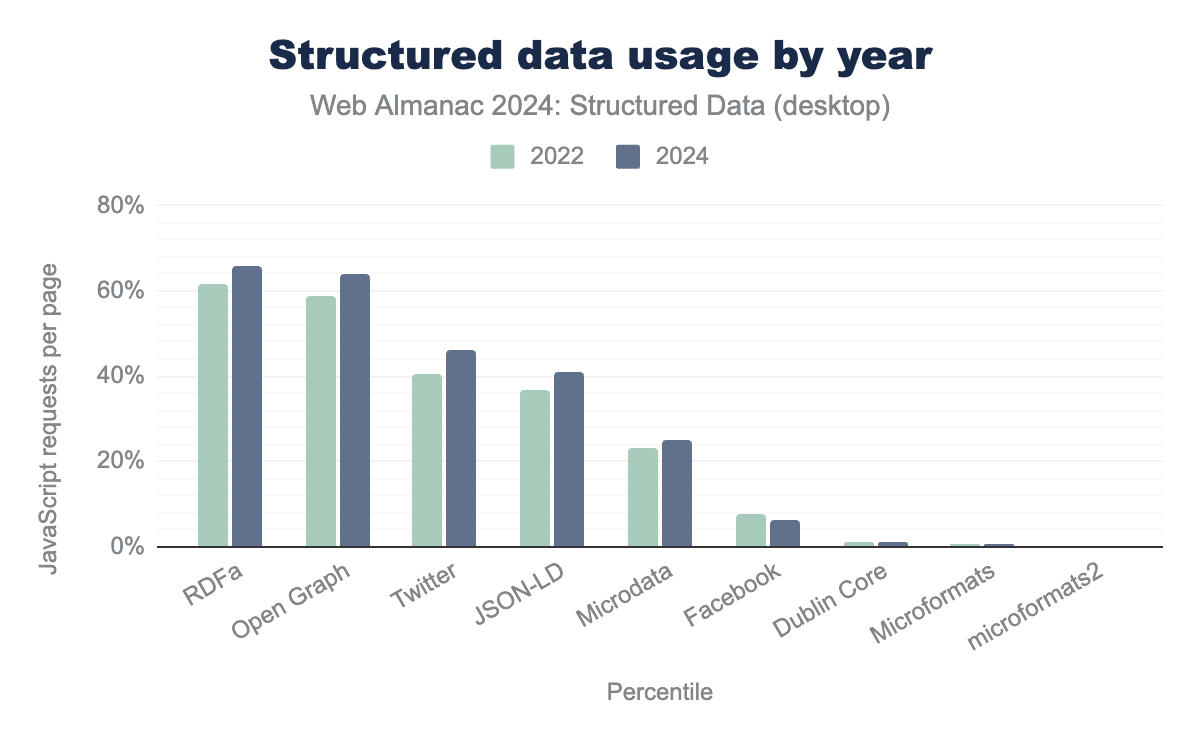
Platform differences between desktop and mobile implementations are becoming less pronounced, suggesting a shift toward standardized structured data strategies across devices. This trend aligns with the growing reliance of search engines and AI systems on structured data for better content understanding and presentation.
Comparison of JSON-LD, Microdata, and RDFa usage
The three main structured data formats show distinctly different adoption patterns:
- RDFa: Highest adoption at 66% of pages Most prevalent on legacy CMS platforms Common implementations: Navigation elements (breadcrumbs) Basic page structure Image and document metadata List items
- JSON-LD: Present on 41% of pages (up from 34% in 2022). Growing fastest among the three formats, preferred by Google and gaining wider developer adoption. Most commonly used for: organization data, local business information, product listings, articles and creative works.
- Microdata: Present on 26% of pages. Showing steady but slower growth. Primarily used for webpage structure (8.34% of pages), site navigation (6.42%), headers and footers (5.97% and 5.33%), organization information (4.87%) |
Let’s analyze now more in detail each type.
RDFa
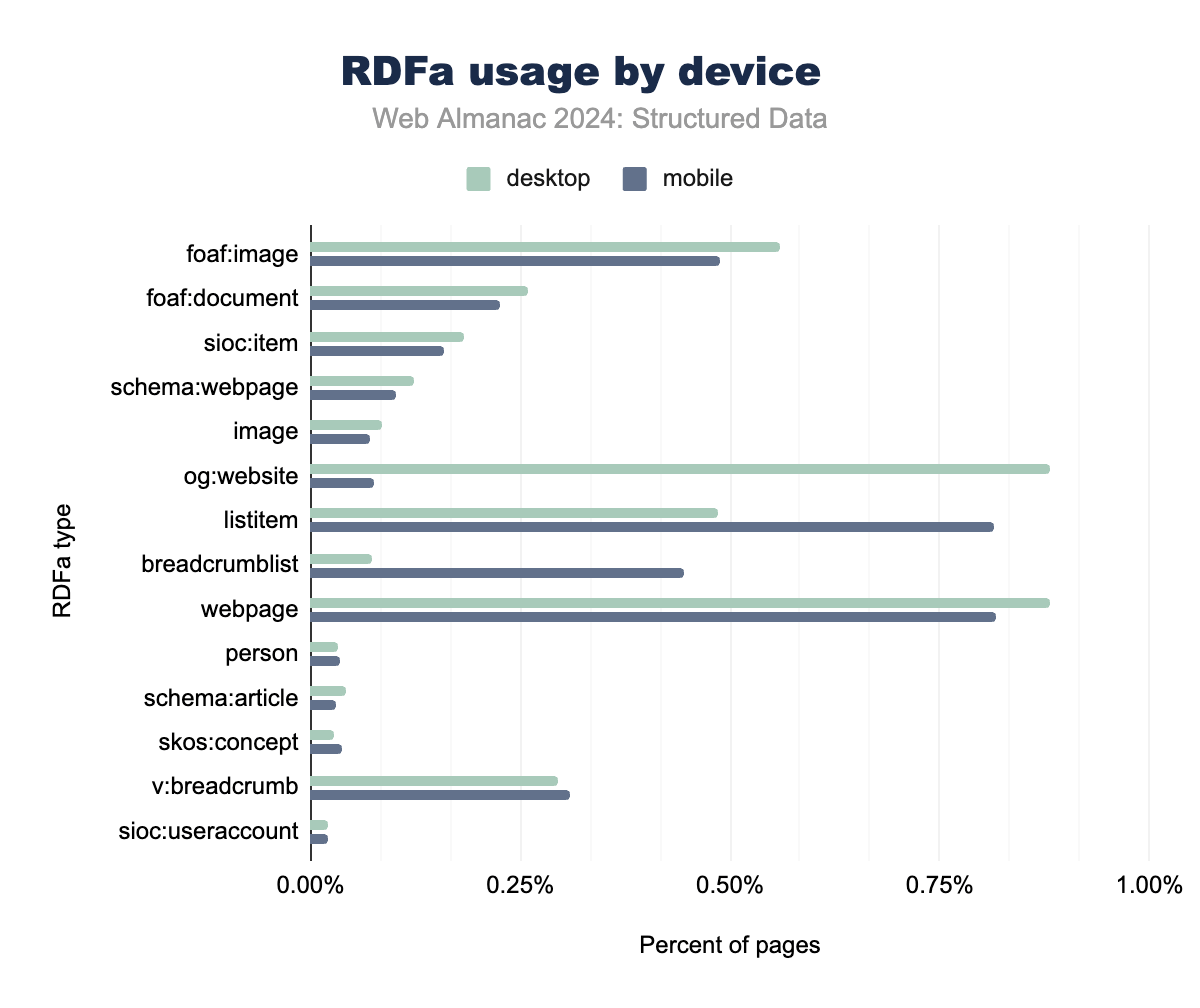
RDFa continues to play a significant role in structured data, particularly within legacy CMS platforms. However, there has been a noticeable shift towards using RDFa for navigation elements, such as listitem and breadcrumblist, which are now prevalent on a significant portion of web pages. This reflects an industry-wide emphasis on enhancing structured navigation data for better user experience, particularly on mobile platforms.
In contrast, traditional RDFa types like foaf:image and foaf:document have seen declining usage, as newer formats like JSON-LD and Open Graph offer more flexible solutions for image and document metadata. The adoption of Schema.org types within RDFa, such as schema:webpage, has shown modest but stable growth, further indicating a shift towards Schema.org vocabularies.
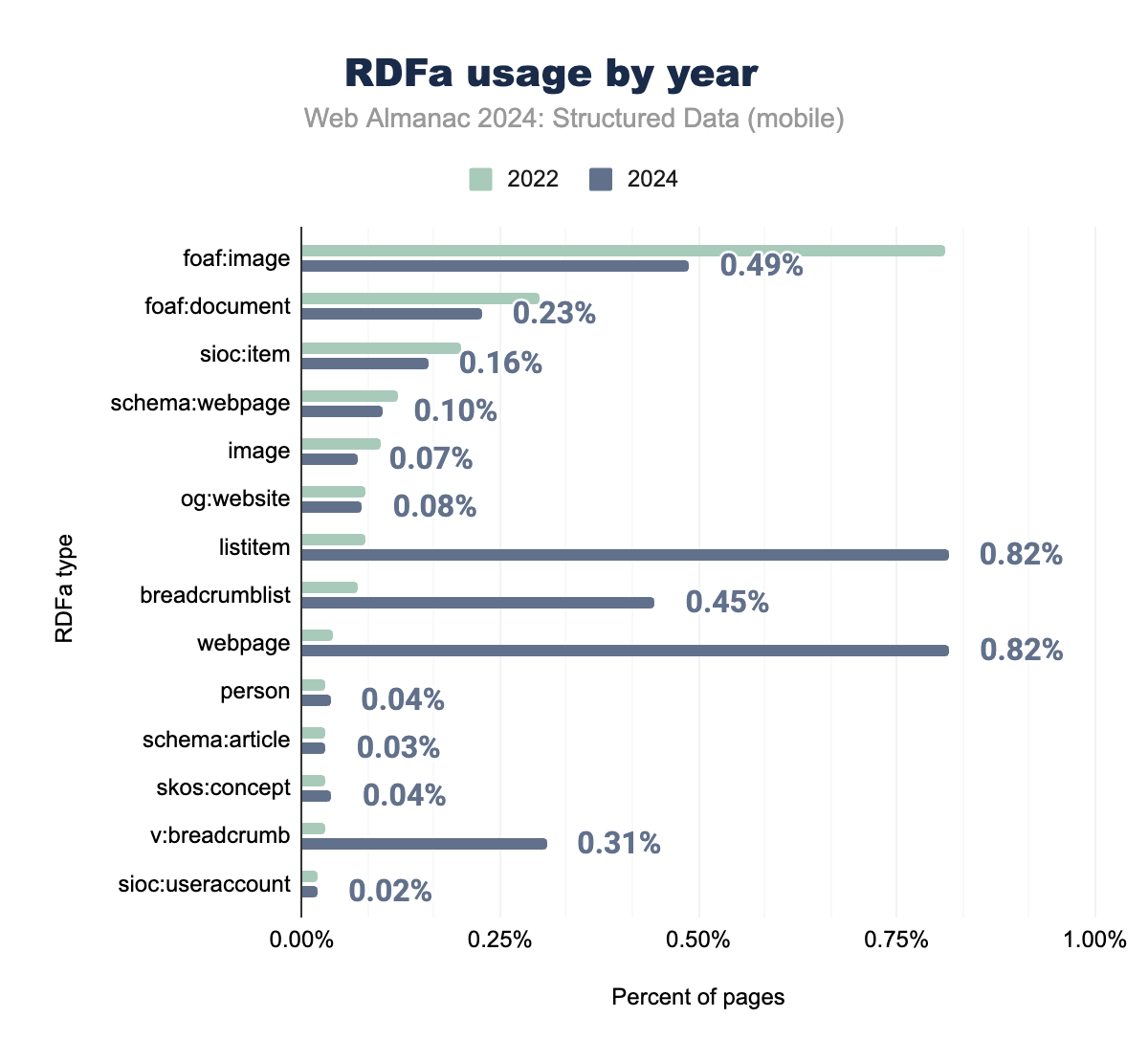
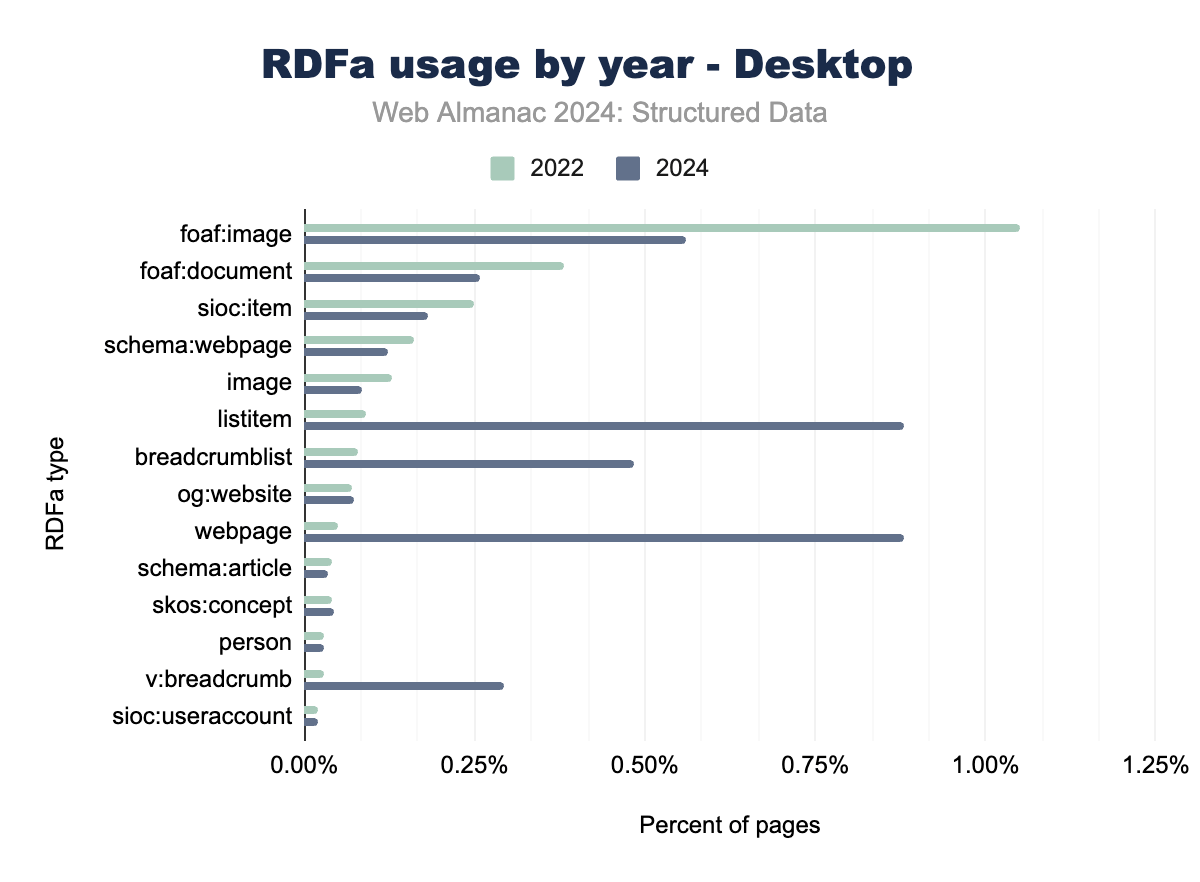
The data suggests that while RDFa remains a valuable tool, its dominance is gradually being overtaken by modern structured data formats like JSON-LD, particularly in dynamic content applications.
Dublin Core
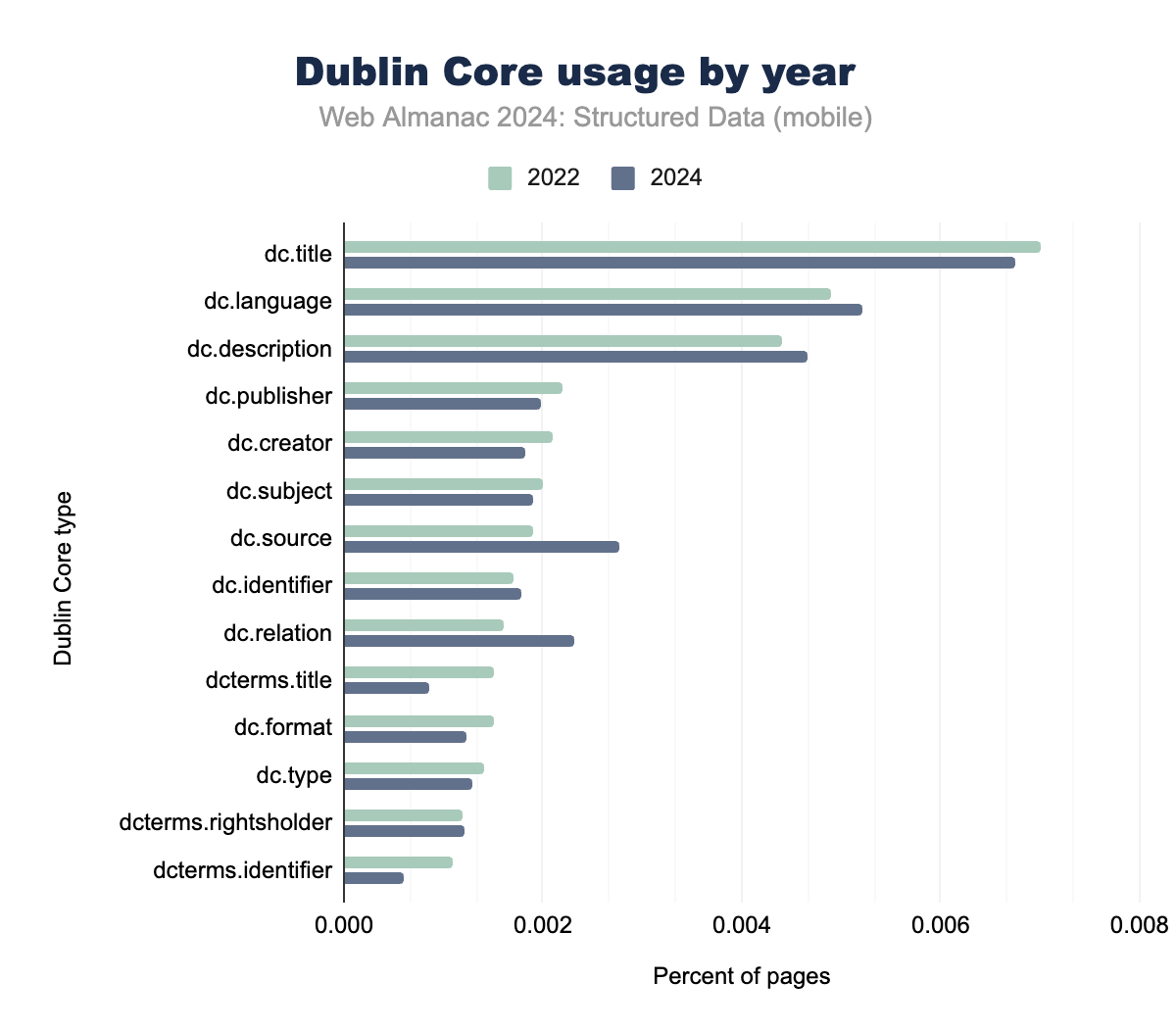

Dublin Core remains a stable but less frequently used format for metadata, especially when compared to modern formats like JSON-LD and Open Graph.
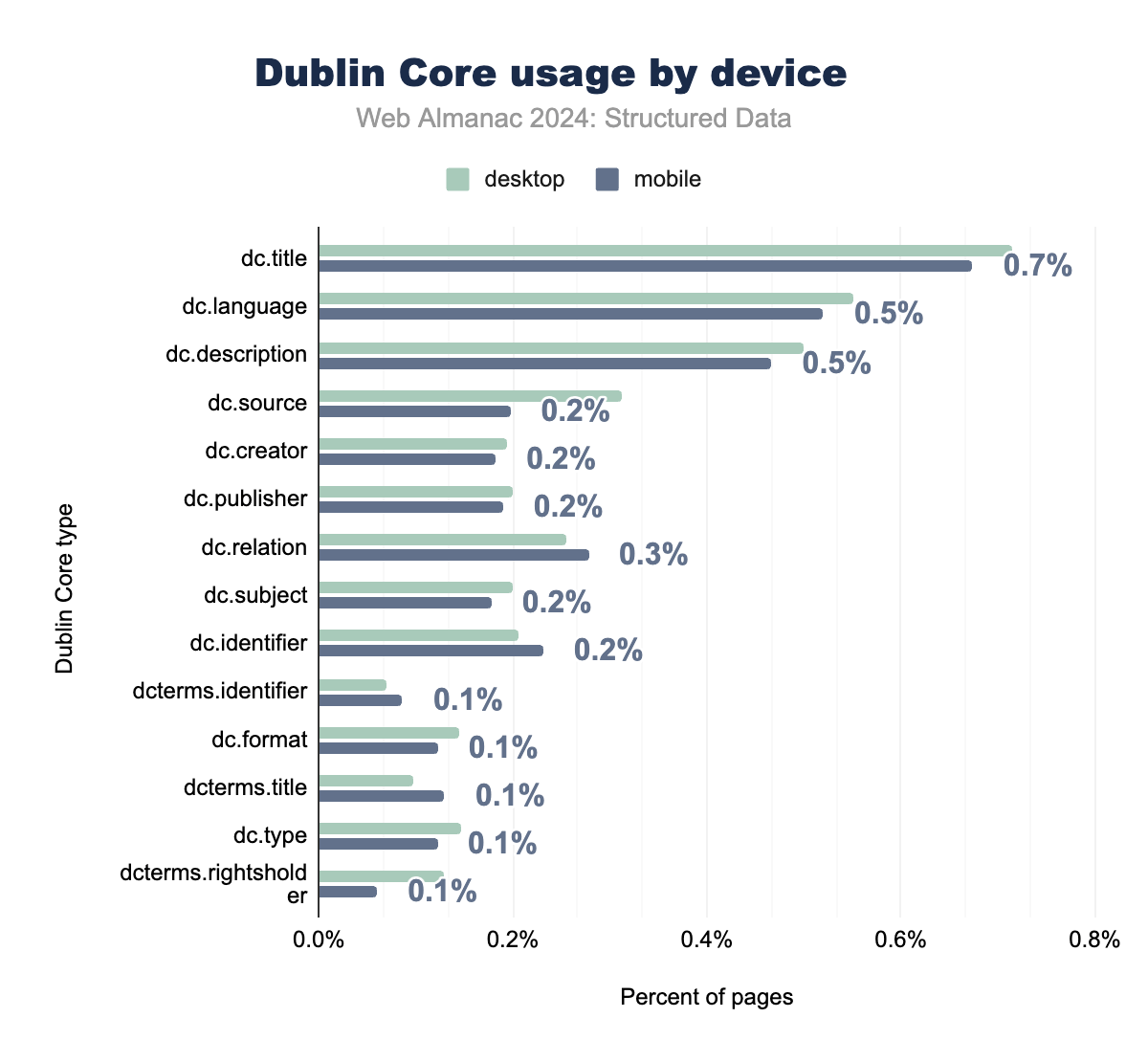
Its key fields, such as dc.title and dc.language, show minimal year-on-year changes, maintaining a consistent presence primarily in academic and legacy web projects.
An increase in the use of dc.source reflects a growing emphasis on citing original sources, while fields like dc.identifier continue to be crucial for resource identification. However, specialized fields such as dcterms.identifier have seen declining adoption, signaling that Dublin Core is less central in today’s web environments.
Interestingly, Dublin Core retains relevance in multilingual document management, particularly through the dc.language field, which is essential for managing and categorizing content in multiple languages. This makes it a valuable tool in contexts where document metadata needs to support internationalization and localization efforts.
Overall, while Dublin Core is being gradually outpaced by more versatile formats like JSON-LD, it continues to serve niche needs where structured document metadata and multilingual support are critical.
Open Graph
Open Graph continues to be one of the most widely implemented structured data formats, particularly in the context of social media sharing. The og:image tag remains the most frequently used property, reflecting the growing emphasis on visual content optimization. Other image-related tags, such as og:image:width and og:image:height, have also seen a steady increase in adoption as websites strive to enhance the presentation of shared content across platforms.
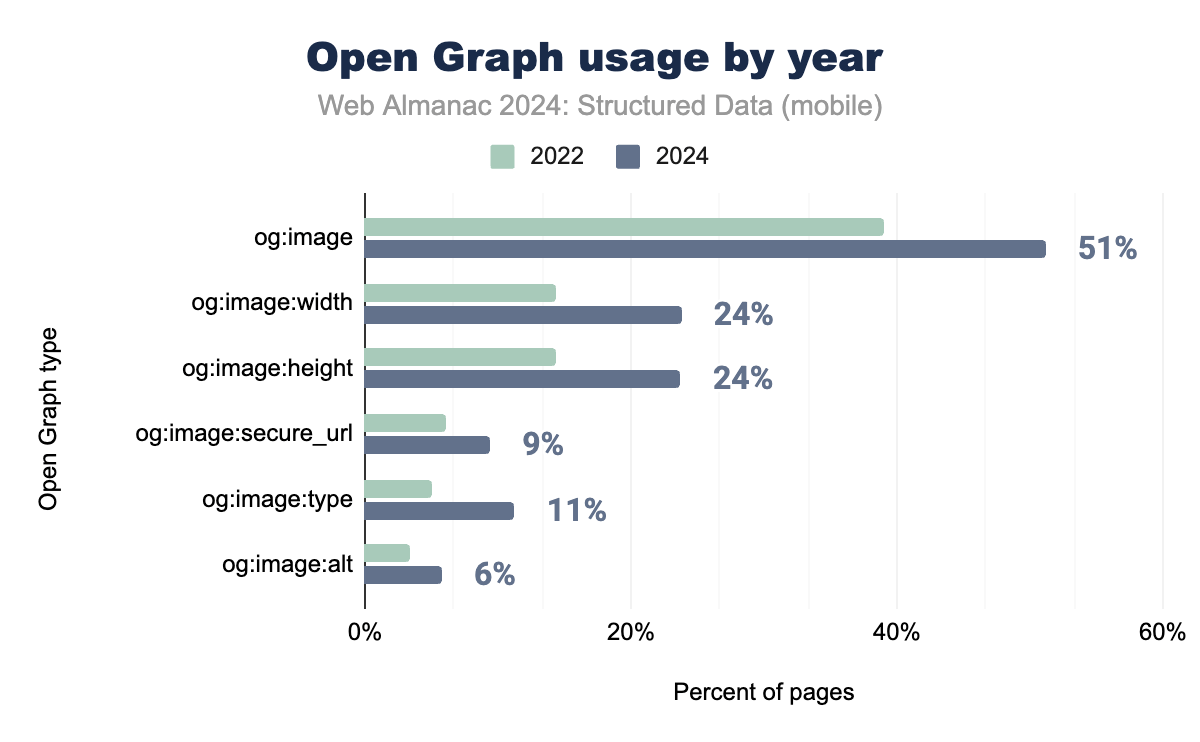
A key development in 2024 is Google’s update to its search documentation, now including the og:title meta tag as a source for generating title links in search results. This update allows Google to consider the og:title tag alongside traditional sources, such as the HTML <title> tag, when determining how clickable titles are displayed in search results. As a result, the og:title tag has gained renewed significance, not only for social media visibility but also for SEO.
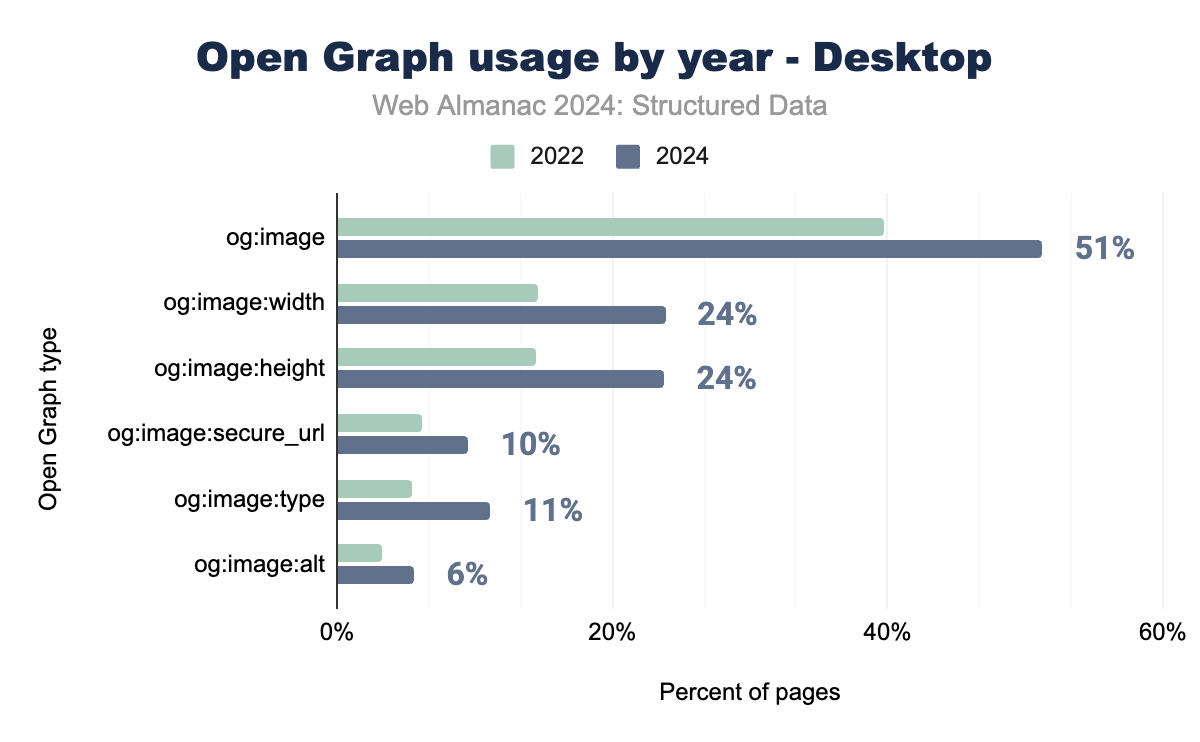
This dual role of Open Graph in social sharing and search engine optimization makes it a critical tool for webmasters looking to improve both user engagement on social platforms and visibility in search results.
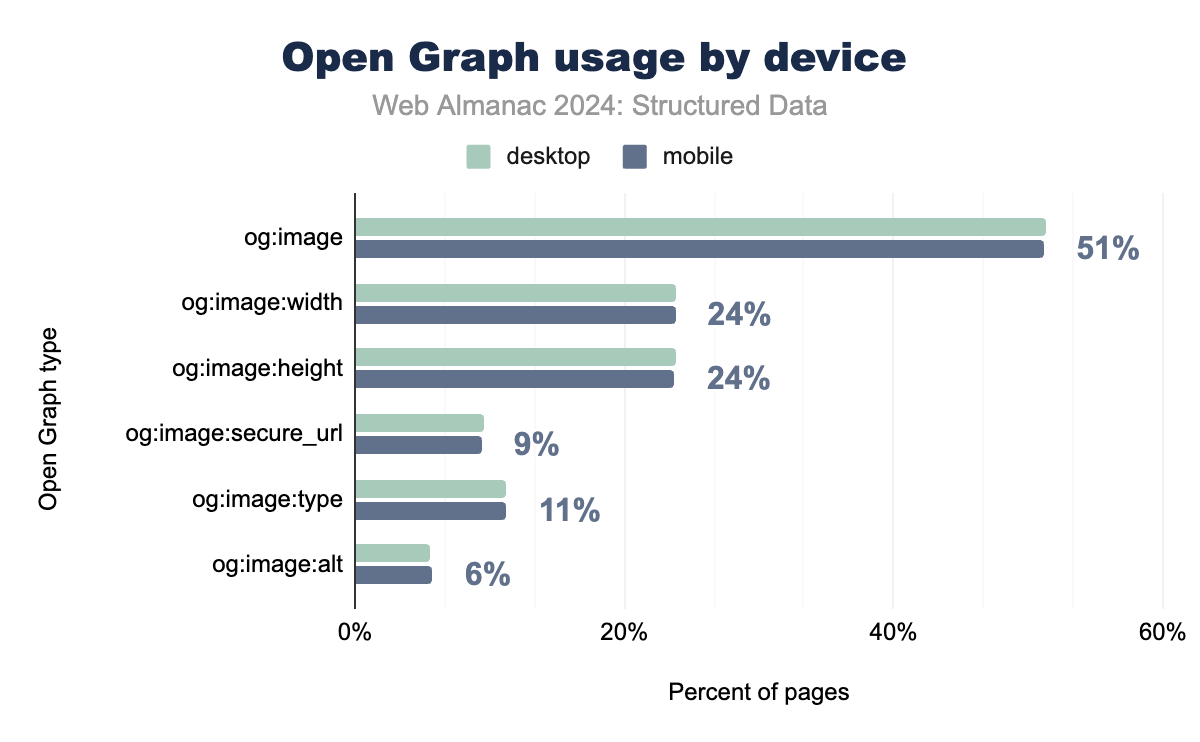
Security and type-related properties have also gained traction. The og:image:secure_url property, which ensures image URLs are served over secure HTTPS connections, has increased to 9.41% on mobile and 9.56% on desktop. Similarly, og:image:type, which specifies the MIME type of the image, has grown to 11.26% on mobile and 11.17% on desktop. These properties help ensure consistent and secure media delivery across devices and platforms.
Despite the platform’s transition to new ownership and its rebranding as X, Twitter’s meta tags remain a vital part of the structured data landscape, particularly in the realm of social media optimization. The twitter:card tag continues to dominate, showing significant growth across mobile and desktop pages, as it plays a key role in defining how content is displayed when shared on the platform.
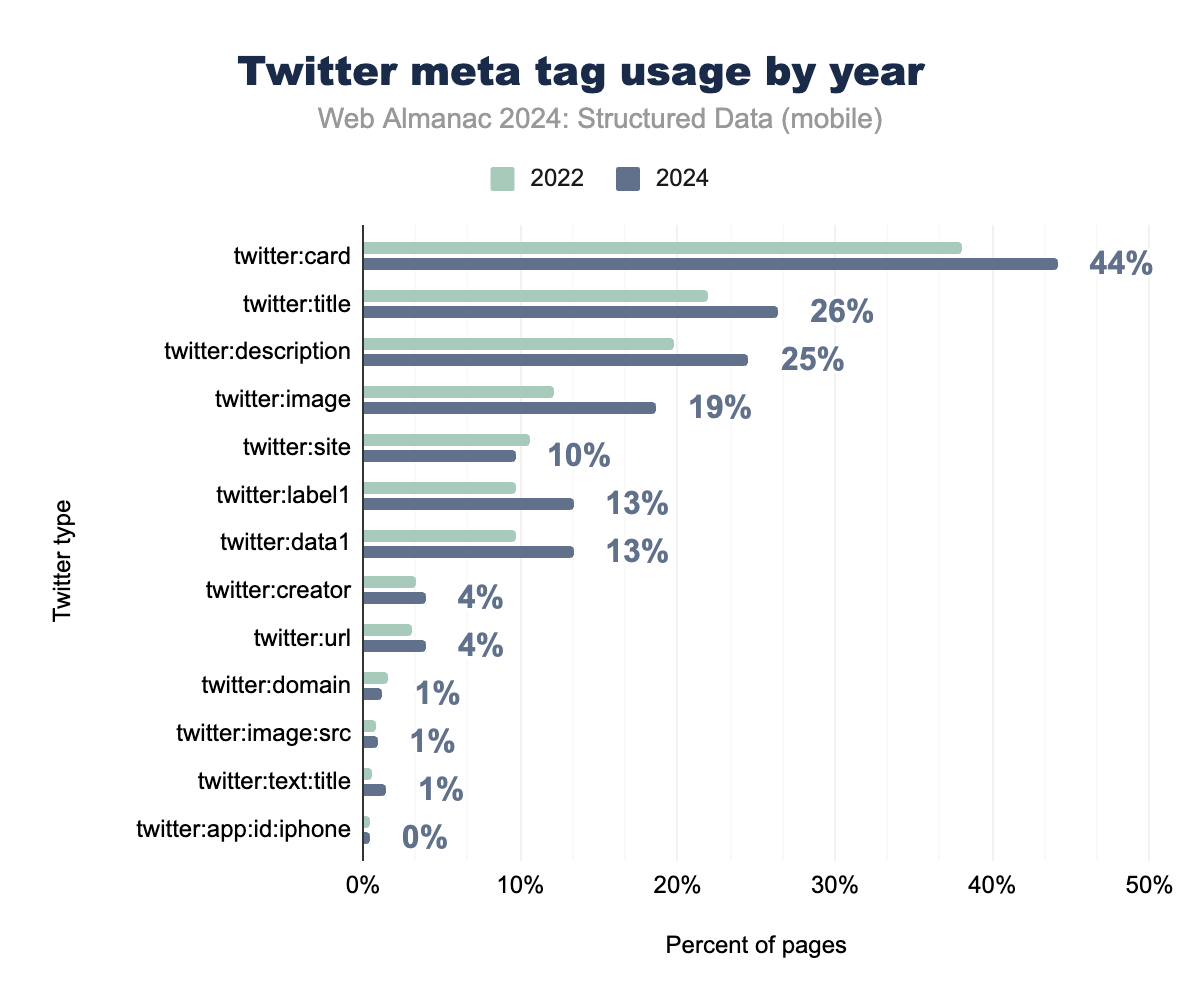
Core descriptive tags like twitter:title and twitter:description have also seen widespread adoption, appearing on approximately 26% of mobile pages and 24% of desktop pages. These tags are essential for content previews, enhancing how web pages appear when shared on social media, and ensuring key information is highlighted.
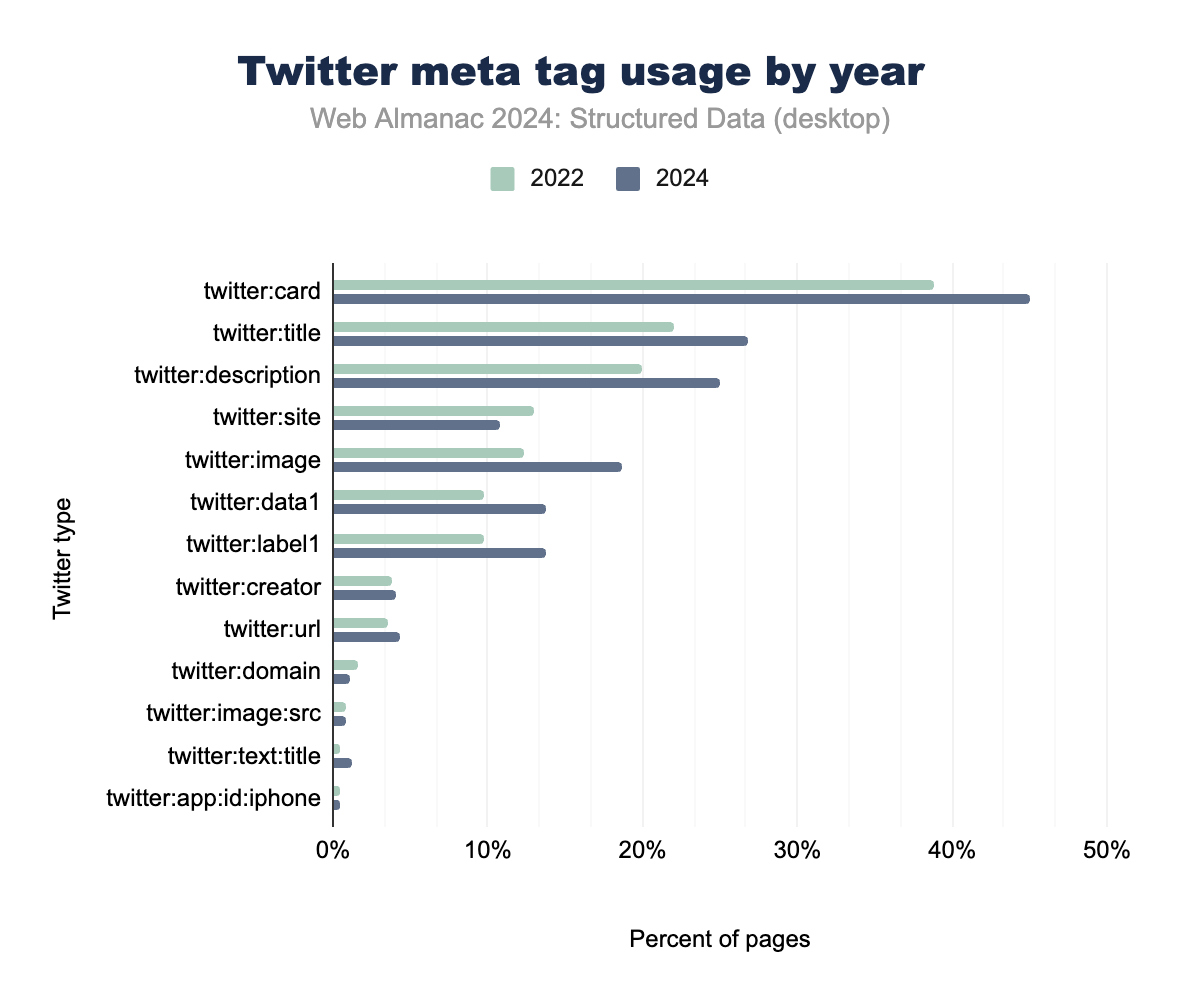

The platform’s enhanced metadata properties, such as twitter:data1 and twitter:label1, which support rich card features, have seen coordinated growth, now appearing on 13.36% of mobile pages. This indicates the increasing use of Twitter Cards for more detailed content representations, such as for product listings or event details.
While X has undergone major branding changes, the metadata architecture it introduced remains critical for webmasters and SEO professionals, ensuring content shared on social media is engaging, informative, and optimized for interaction. This highlights the platform’s enduring importance in the social media and metadata ecosystem.
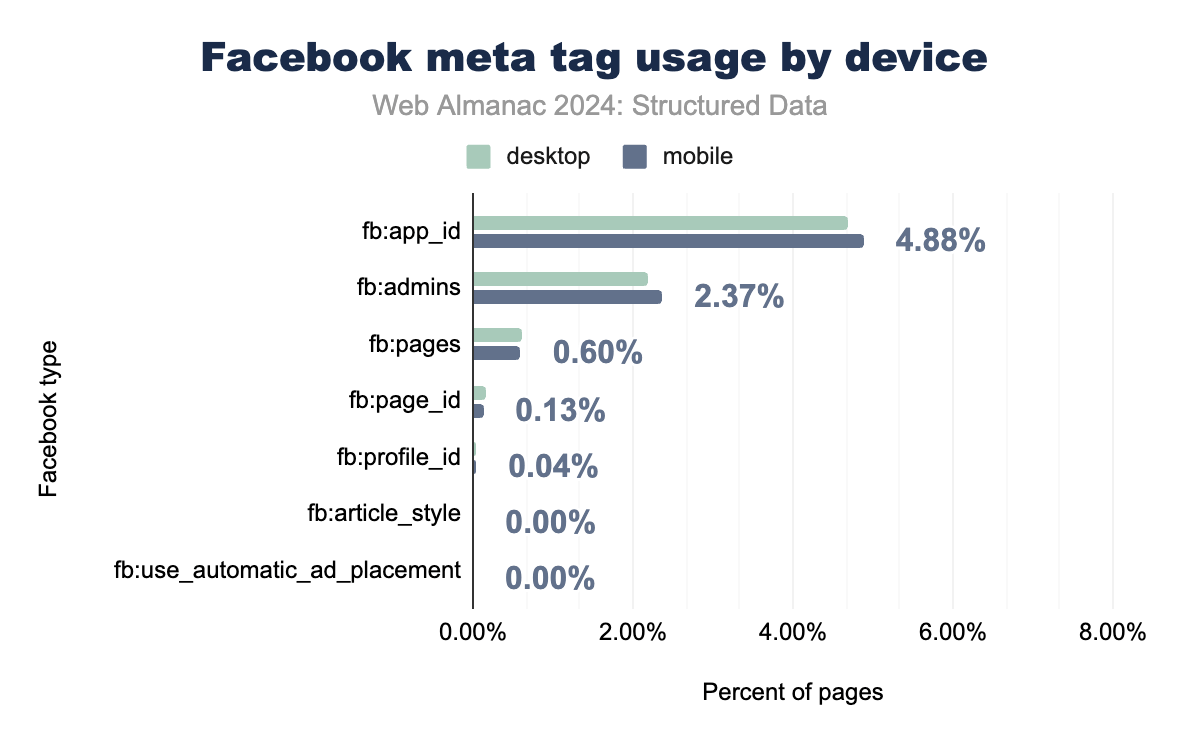
Facebook-specific meta tags have seen a marked decline in usage between 2022 and 2024, reflecting the broader industry shift toward Open Graph as the preferred format for social sharing metadata. The fb:app_id tag, once widely used to integrate apps with the Facebook platform, now appears on only 4.9% of mobile pages, down from previous years. Similarly, administrative tags like fb:admins have dropped to just 2.4%, serving primarily for backend management rather than enhancing content visibility.
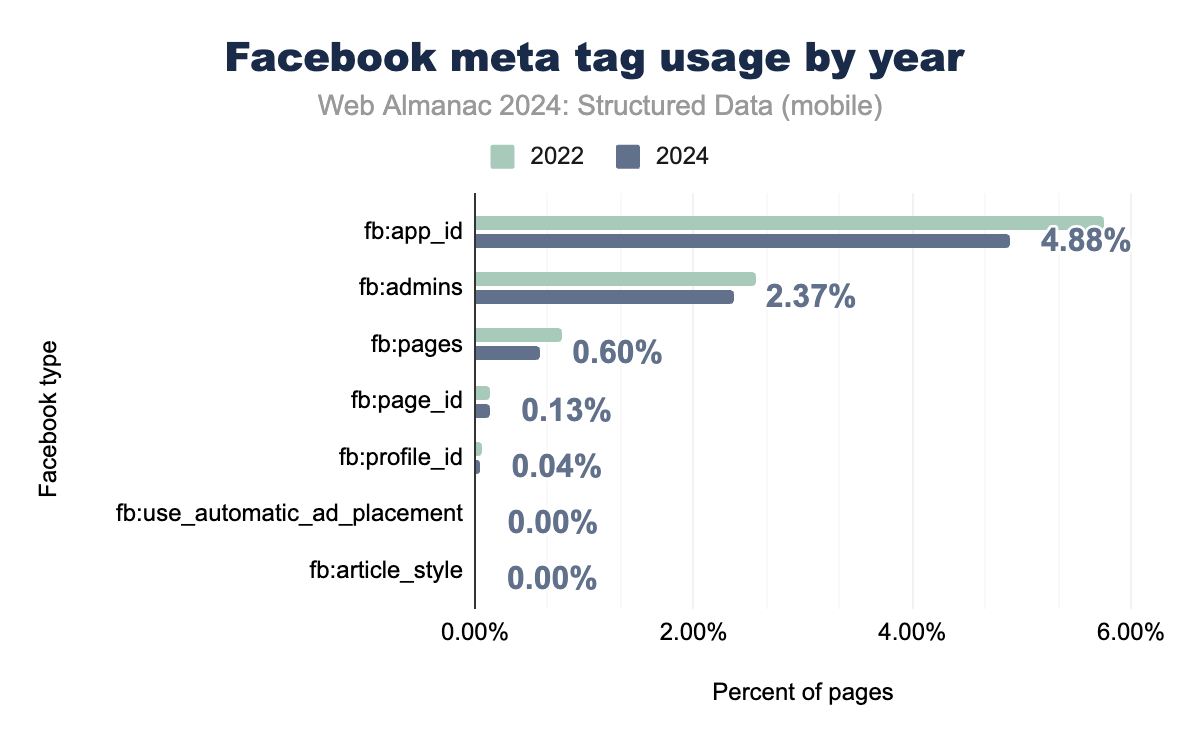
This decline underscores a strategic move by developers and webmasters to adopt Open Graph, which originated with Facebook but has since become the standard for social media sharing across platforms. The Open Graph format offers greater flexibility and interoperability, making it the go-to choice for content optimization on Facebook as well as other social networks.
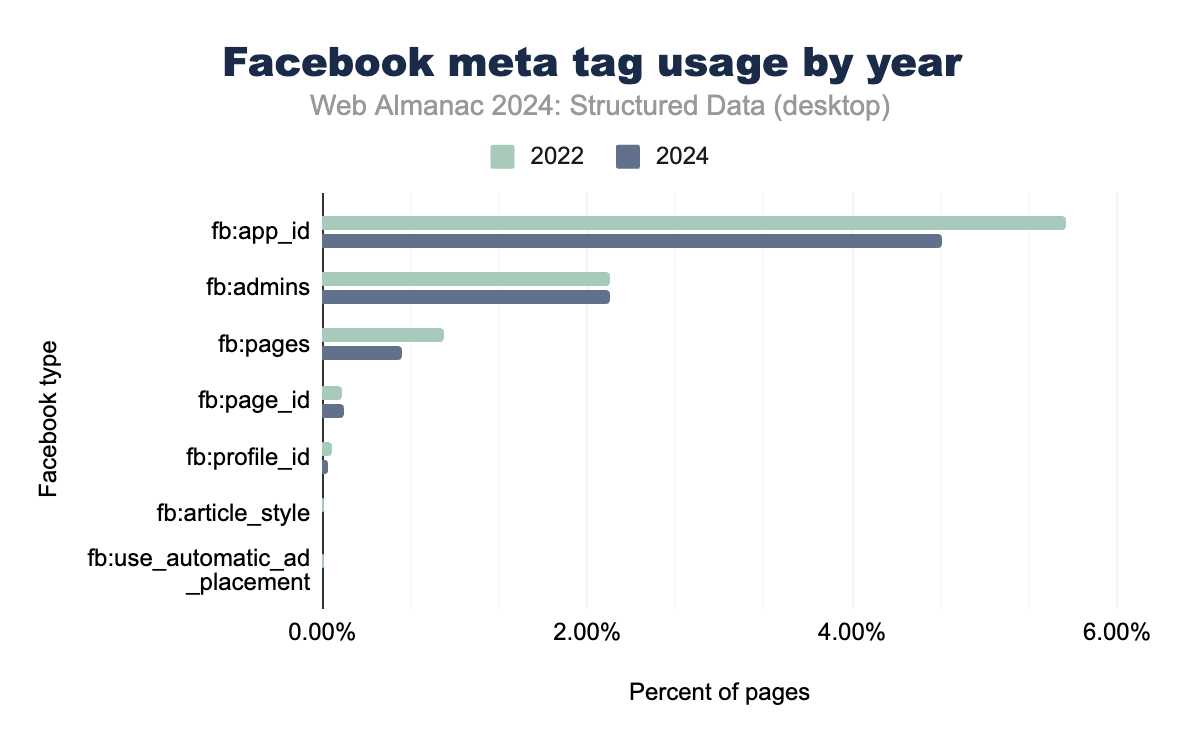
Despite the decreasing adoption of Facebook-specific tags, Facebook itself remains a key player in the social media landscape, with Open Graph handling most of its metadata needs. This trend reflects the consolidation of social sharing standards, where platform-agnostic tags provide greater reach and functionality.
Microformats and Microformats2
Microformats continue to show limited adoption, primarily in niche use cases where simple, semantic data is required. The adr tag, used for address-related data, remains the most widely adopted Microformats type, appearing on approximately 0.4% of pages across both mobile and desktop platforms. Other tags, such as geo and hReview, have minimal usage, as more sophisticated formats like JSON-LD and Open Graph have become more prevalent.
Microformats2, while still relatively niche, has seen slightly higher adoption than its predecessor. Tags like h-entry and h-card, which are used for blogging and personal identity data, now appear on 0.22% of mobile pages and 0.15% of desktop pages. These tags continue to serve specific needs, particularly for address data and simple content structures.


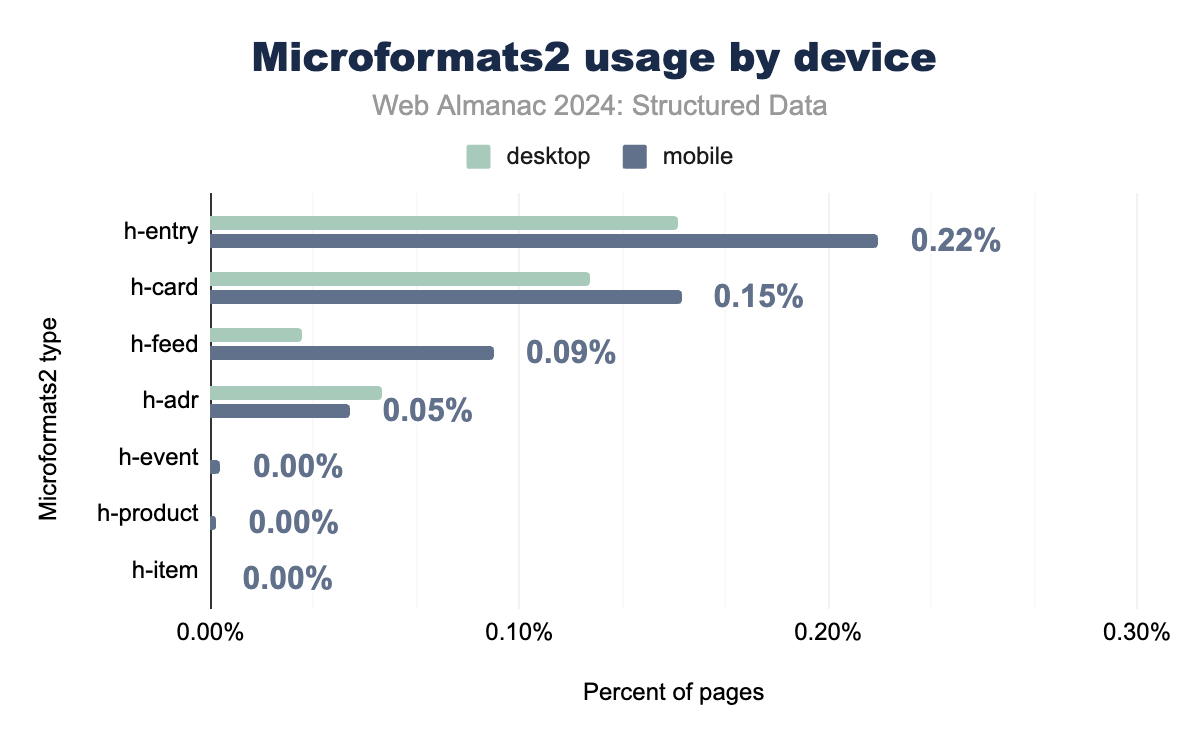

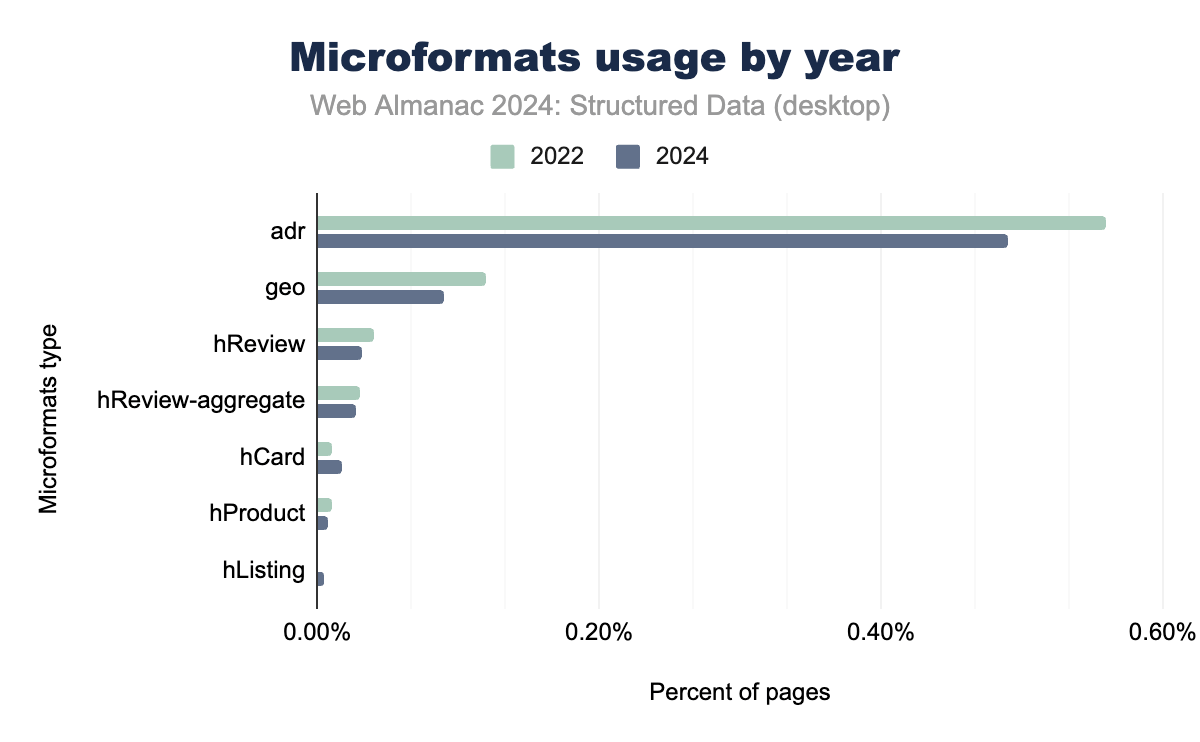
Cross-device implementation remains relatively consistent, though with some variation between mobile and desktop. The data shows a general decline in traditional Microformats usage from 2022 to 2024, particularly in review-related properties like hReview and hReview-aggregate. This decline reflects the industry’s shift toward more modern structured data formats like JSON-LD and RDFa, which offer broader functionality and better integration with current web standards.
Despite this decline, Microformats and Microformats2 remain useful in specific contexts where lightweight, human-readable semantic data is needed. However, their overall presence continues to be eclipsed by more versatile formats like JSON-LD, which dominate the structured data landscape.

Microdata
Microdata continues to be widely used for structural elements and navigation data, particularly within legacy platforms and sites where simpler, static page structures are required. The most frequently implemented types include schema.org/webpage (appearing on 8.34% of mobile pages) and schema.org/sitenavigationelement (used on 6.42% of mobile pages), indicating the format’s enduring relevance for webpage structure and site navigation.

Navigation-related types like listitem and breadcrumblist have also seen steady growth, reflecting the need for more organized and structured navigation data, particularly on mobile devices. However, content-specific types such as schema.org/article and schema.org/product remain less common, with adoption rates of 1.77% and 1.50% respectively, as developers increasingly turn to JSON-LD for more flexible and scalable implementations.
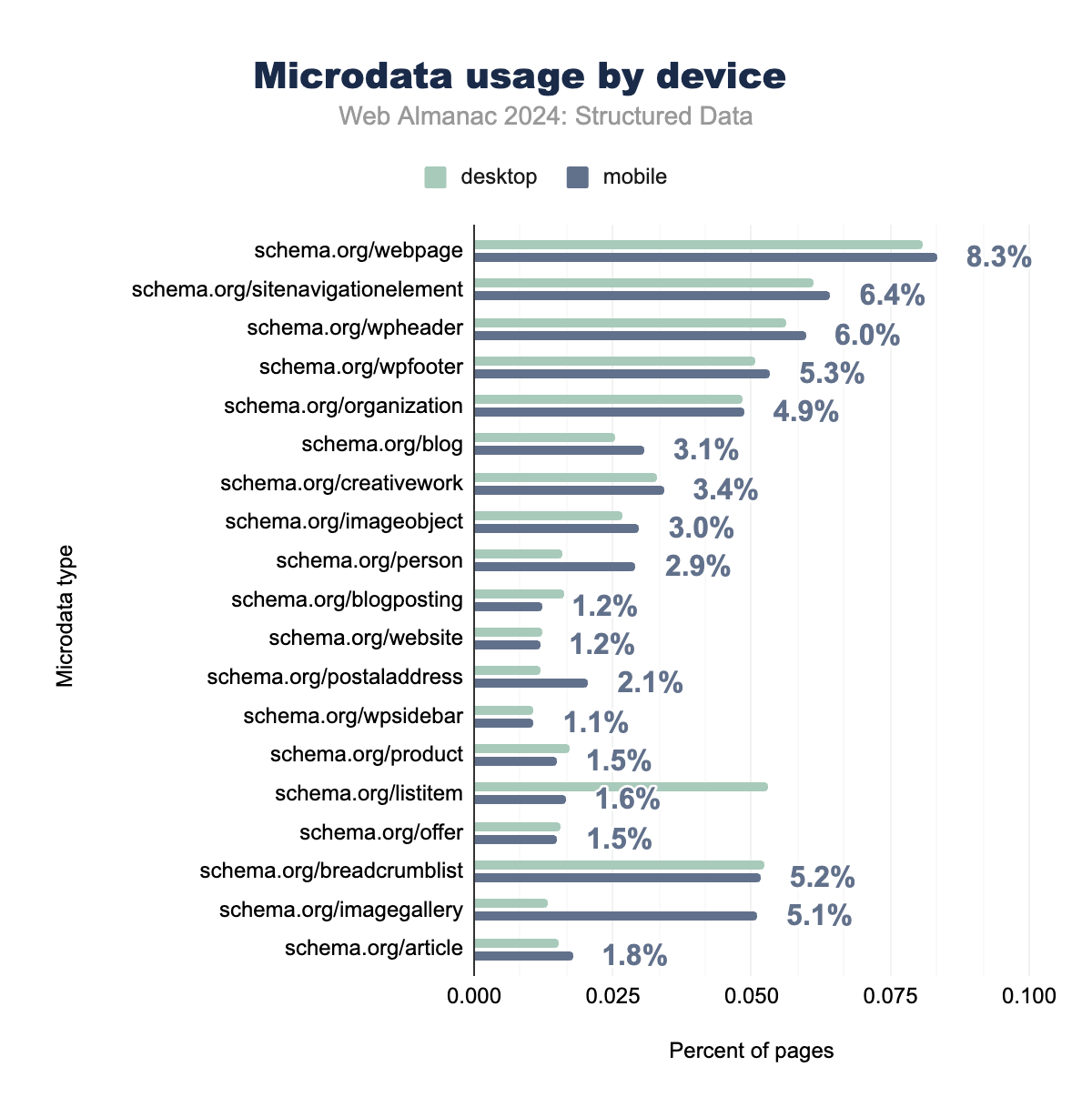
While Microdata remains a significant format for fundamental webpage structure, its use in dynamic content and ecommerce applications has been gradually overtaken by more modern formats like JSON-LD, which offer broader support for content enrichment and structured data scaling across large websites.
JSON-LD
JSON-LD types continue to be widely implemented across websites, with varied types of data used depending on the purpose of the site. The WebSite schema leads adoption, appearing on 12.73% of mobile pages, followed by Organization and LocalBusiness types at 7.16% and 3.97%, respectively. These types are crucial for establishing entity identity and providing contextual information to search engines.
The diversity in implementation patterns reflects how different industries and website types prioritize specific structured data. For instance:
- Ecommerce sites frequently implement
Product,Offer, andReviewschemas. - Local businesses prioritize
LocalBusiness,GeoCoordinates, andOpeningHoursSpecificationto enhance local search visibility. - Content publishers often utilize
ArticleandBlogPostingschemas to structure written content effectively.
BreadcrumbList implementation has seen notable growth, appearing on 5.66% of pages, suggesting an increased focus on structured navigation data. The WebPage schema shows steady adoption at 1.49%, while the Product schema appears on 0.77% of pages. Content-specific types like BlogPosting (1.40%) and Article (0.18%) maintain consistent presence, though at lower levels.
Specialized business types such as Restaurant (0.19%), AutoDealer (1.09%), and Store (0.17%) demonstrate the growing adoption of industry-specific markup, corresponding to Google’s increased support for these schemas. Supporting content types including VideoObject, FAQPage, and Event each appear on approximately 0.34% of pages, indicating steady but modest implementation of specialized content markup.
ItemList schema shows healthy adoption at 2.44%, suggesting increased use of structured listing data. The overall distribution of JSON-LD types reflects a maturing ecosystem where fundamental entity types dominate, while specialized schemas serve specific business and content needs.
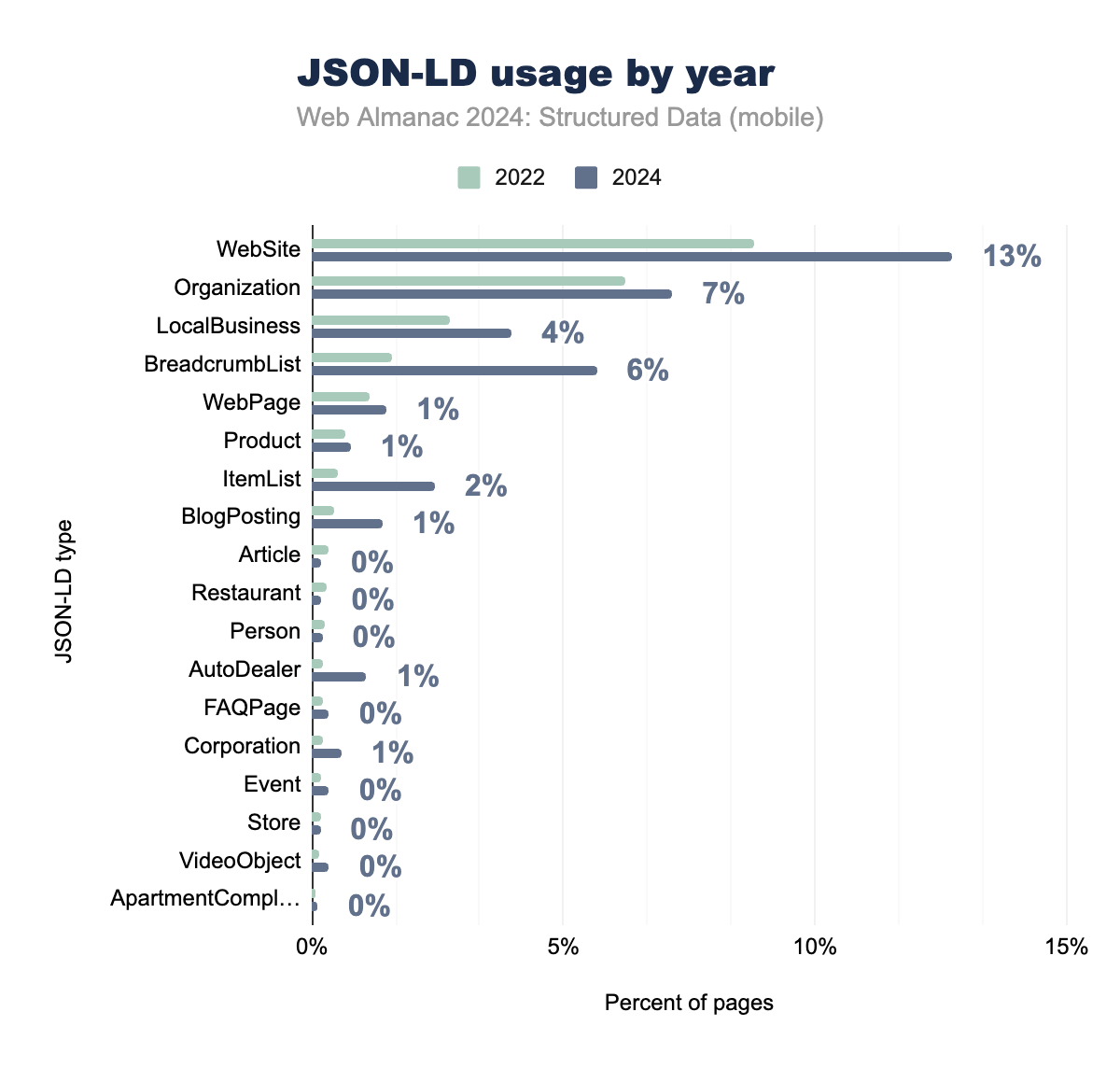
The consistency in implementation across devices indicates a mature approach to structured data deployment, where developers are ensuring uniform markup regardless of the target platform. This alignment between mobile and desktop implementations suggests that organizations are following best practices for responsive design while maintaining consistent structured data across all user experiences.
Despite Google’s deprecation of FAQ and HowTo rich results in August 2023 (source), we see limited impact on their adoption rates. HowTo schema adoption has historically been low due to its complexity, with implementation rates below 1% for both desktop and mobile. FAQPage, on the other hand, has not only maintained its adoption but even shows a slight increase on desktop, rising from 0.2% in 2022 to 0.6% in 2024. This trend suggests that webmasters may still find value in implementing FAQPage for additional search engine visibility besides rich results.
These observations highlight the resilience of certain structured data types despite changes in Google’s support. It also points to the importance of monitoring how structured data evolves across various platforms, as its utility often extends beyond immediate search result enhancements.

WebSite, Organization, LocalBusiness, and more.JSON-LD relationships
When evaluating JSON-LD relationships in structured data implementations, several key patterns emerge in how entities are connected in a graph. These relationship patterns reflect how structured data is used to create comprehensive, interconnected entity descriptions that help search engines better understand content context and relationships. The most successful implementations leverage these connections to provide rich, detailed information while maintaining logical content relationships.
Let’s review the most critical patterns from the JSON-LD relationship analysis:
- Local business ecosystem. The most sophisticated structured data implementations are occurring in the local business sector, where we see rich interconnections between
LocalBusiness,OpeningHoursSpecification,PostalAddress, andGeoCoordinates. This suggests businesses are creating comprehensive digital identities that go beyond basic location information to include detailed operational data. This aligns with Google’s increasing focus on local search and the growing importance of location-based services. - Content organization. Maturity There’s a clear pattern of publishers implementing more sophisticated content structures. The relationships between
Article,BlogPosting, andWebPageentities consistently link toImageObject, author attributes, and publishing details. This isn’t just about marking up individual pieces of content – it’s about creating proper content graphs that establish clear relationships between content, creators, and organizational entities. - Ecommerce integration. The product-related relationships show an interesting evolution. Beyond basic product markup, we’re seeing more connections to
ReviewRating,AggregateOffer, andPriceSpecificationentities. This suggests ecommerce sites are building more comprehensive product knowledge graphs that can support advanced features like price tracking and inventory status.
Most notably, these patterns indicate that structured data implementation is moving beyond simple SEO markup toward creating true knowledge graphs that can support AI-powered search experiences and rich data integrations.

potentialAction, itemListElement, and isPartOf connecting to various schemas.
WebSite, SearchAction, and Organization.As seen also in the previous chart the most frequent JSON-LD property relationships reveal several critical implementation patterns across websites. PotentialAction emerges as a dominant property, showing strong connections to SearchAction and WebSite, indicating widespread implementation of site search functionality (we expect this to decrease as Google is removing support for this feature snippet). Image-related properties form another major cluster, with ImageObject frequently connected to Organization and WebPage entities, demonstrating the importance of visual content attribution. The publisher and logo properties frequently link to Organization entities, establishing clear brand identity.
Navigation structures show clear patterns through BreadcrumbList and itemListElement properties, typically connecting to WebPage entities. Content relationships are evidenced by mainEntityOfPage connections, while business-specific information flows through address, openingHoursSpecification, and geo properties.
Particularly noteworthy is the consistent implementation of contact and location information, with PostalAddress, ContactPoint, and GeoCoordinates forming a well-defined cluster. This suggests businesses are prioritizing local presence markup. The presence of review-related properties (reviewRating, rating) connected to various entities indicates strong focus on reputation management through structured data.
sameAs
The sameAs property plays a crucial role in entity disambiguation and knowledge graph development, extending far beyond simple social media profile linking. While our data shows strong implementation for major platforms (Facebook at 4.53%, Instagram at 3.67%), the true strategic value lies in how sameAs helps search engines understand and validate entity relationships.
When properly implemented, sameAs serves as a powerful tool for entity disambiguation, particularly for organizations and persons. By linking to authoritative sources like Wikidata (0.17%) and Wikipedia (0.13%), brands can establish unambiguous entity identification. This creates what we might call a “entity fingerprint” that helps search engines confidently associate various online presences with the correct entity.
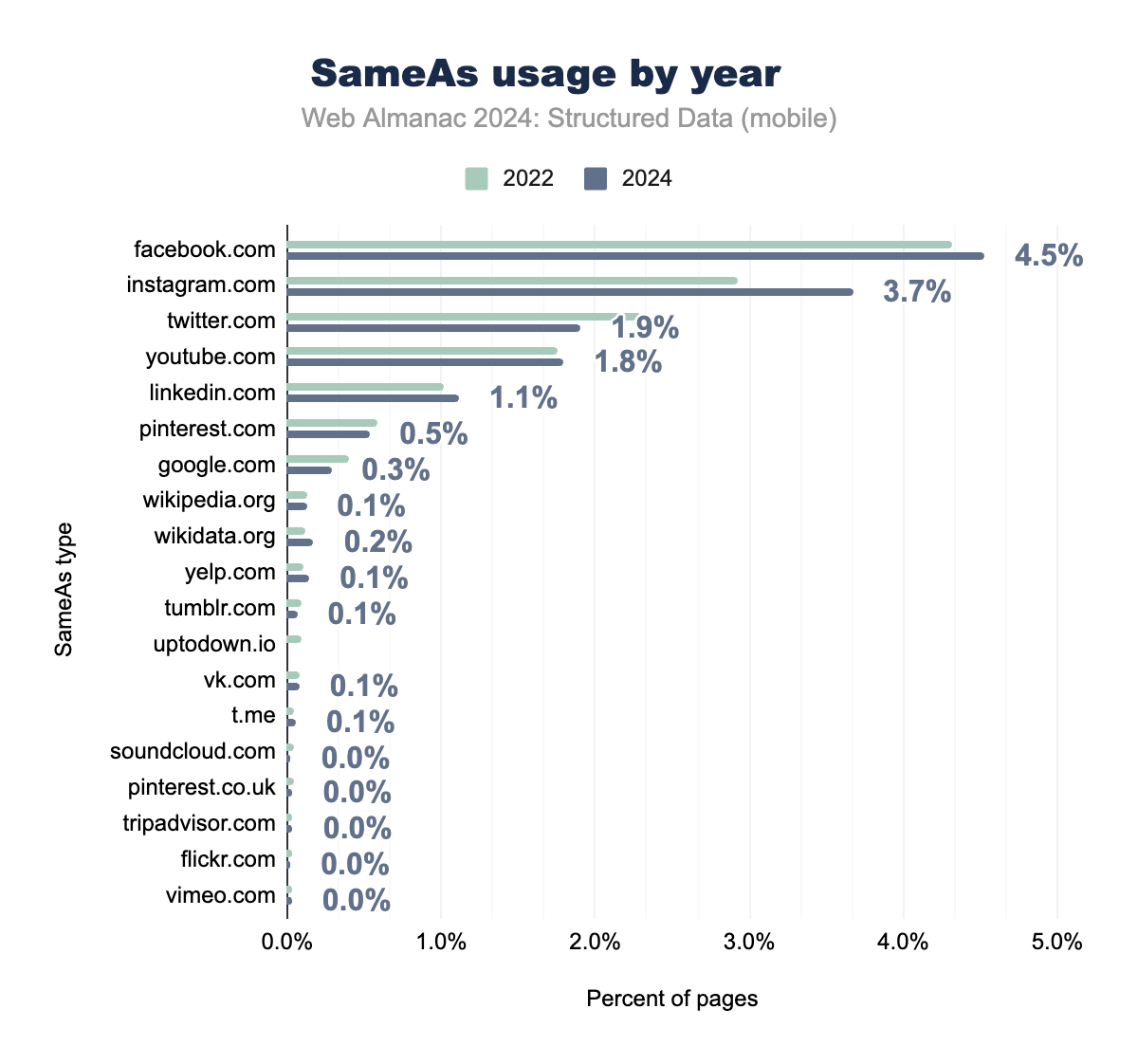
sameAs links by type for mobile pages in 2022 and 2024. The chart shows Facebook.com leading with 4.5% in 2024, followed by Instagram.com with 3.7%. Other platforms include Twitter.com, YouTube.com, and LinkedIn.com, highlighting usage trends over two years.sameAs usage on mobile pages in 2022 and 2024.
For personal entities (executives, authors, experts), sameAs similarly helps establish authority and credibility by connecting professional profiles (LinkedIn at 1.11%) with other authentic entity markers. This becomes particularly valuable for E-E-A-T signals and knowledge panel generation.
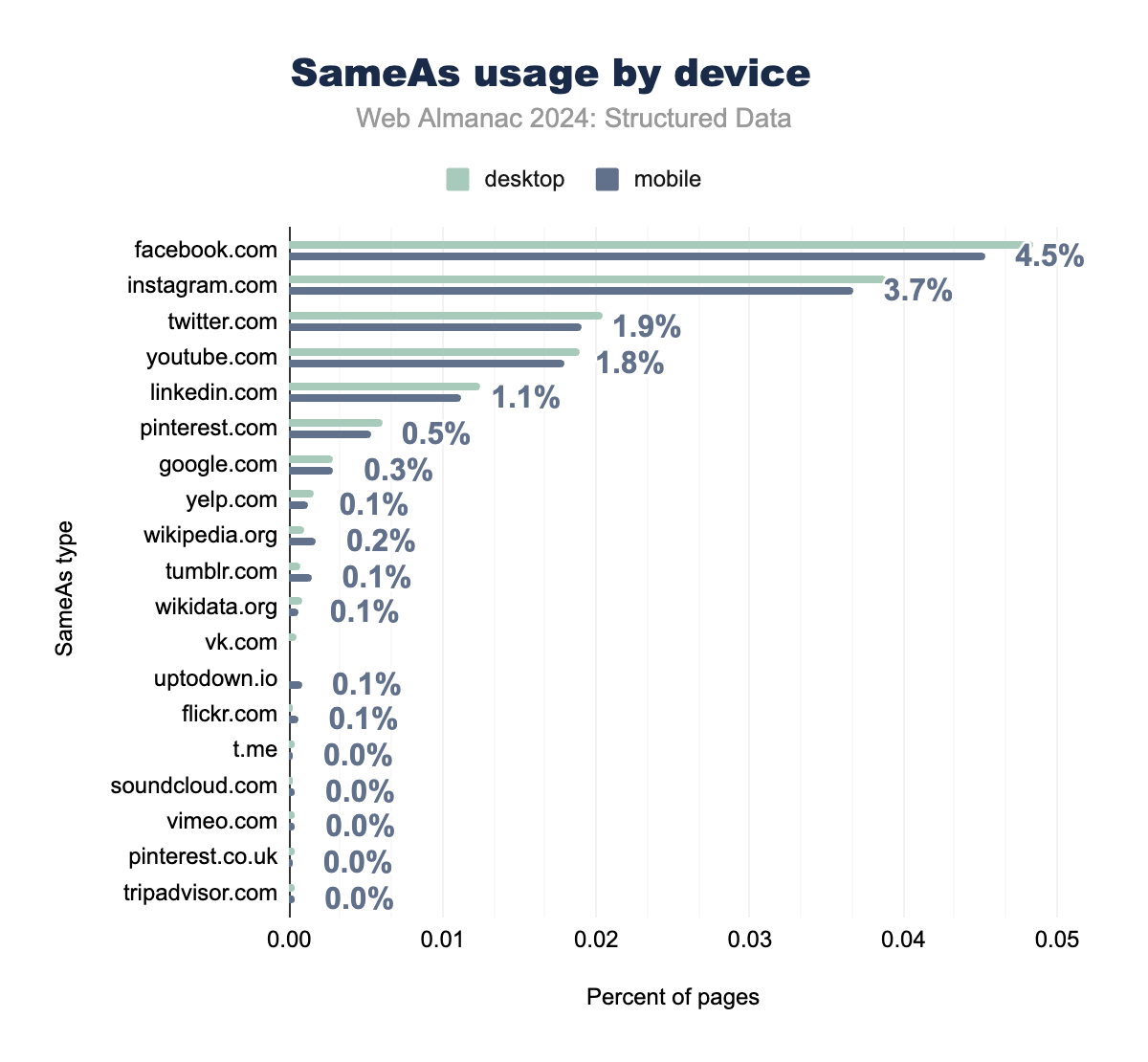
sameAs links by device type (desktop and mobile). Facebook.com leads with 4.5% on desktop and 3.7% on mobile, followed by Instagram.com, Twitter.com, and others. The data highlights differences in usage patterns across platforms.sameAs usage by device on mobile and desktop for various platforms.
This parity between mobile and desktop implementations represents a significant advancement in structured data deployment. It suggests that organizations are increasingly using consistent templating systems or automated solutions to manage their structured data, rather than maintaining separate implementations for different devices.
JSON-LD context
Schema.org remains the dominant force in JSON-LD context implementation with over 20 million instances, far exceeding all other contexts. This dominance (20,960,693 implementations versus the next highest at 11,973) reflects its position as the industry standard for structured data markup.
Among secondary implementations, contao.org leads with 11,973 instances, primarily within its CMS ecosystem, followed by googleapis.com (3,743) and baidu.com (1,409). Educational institutions show consistent adoption patterns around 25-50 implementations each, while regional variations appear through implementations like Schema.org.cn and Schema.gov.sg, indicating global adoption of structured data standards.
The vast gap between Schema.org and other contexts underscores its critical role in structured data standardization and reflects strong alignment with search engine requirements.
Emerging trends and future outlook
The structured data landscape is rapidly evolving, marked by Google’s introduction of specialized schemas for vehicles, courses, and 3D product models, alongside increased support for Digital Product Passports through GS1 Digital Link. The growing adoption of JSON-LD (now at 41% of pages) and sophisticated entity relationships through sameAs properties indicates a maturing ecosystem focused on comprehensive knowledge graph development.
The data shows a clear shift toward more specialized implementation patterns, particularly in ecommerce and local business contexts. For instance, structured data types like Product, Offer, and Review have become more prevalent in ecommerce, while LocalBusiness and GeoCoordinates are increasingly used to improve local search visibility.
This shift can be partially attributed to Google’s policy changes, which encouraged webmasters to focus on more domain-specific schemas. Entity disambiguation has also become increasingly critical, with organizations leveraging structured data like sameAs and Organization to establish clear digital identities across platforms and knowledge bases.
Looking ahead: the future of structured data
As we analyze current trends, we also cast our gaze forward to emerging developments:
-
AI and structured data symbiosis
The growing interdependence between AI systems and structured data is becoming crucial for delivering grounded, hallucination-free content generation and enhancing conversational search experiences. As AI relies increasingly on structured data for accurate and context-rich information, this symbiosis is redefining how AI-powered tools interact with content across the web.
-
Data Commons and knowledge graph integration
The expansion of open data initiatives, such as Google’s Data Commons, which leverages Schema.org for structuring and linking public datasets, is further fueling the evolution of knowledge graph-based systems. These initiatives provide a rich, unified foundation for AI-driven data enrichment and exploration, creating new possibilities for scalable and reliable data integration across platforms.
-
SEOntology and specialized vocabularies
In parallel, the development of SEOntology and other specialized vocabularies is addressing the need for SEO-specific structured data that can improve content discoverability and search engine optimization. By creating vocabularies tailored to the unique requirements of SEO, we can further enhance the alignment between structured data and AI, driving more targeted and efficient search experiences.
-
Regulatory impacts
Finally, regulations such as the EU’s Digital Product Passport are poised to reshape future structured data standards. These initiatives will likely influence how structured data is applied, especially in domains like ecommerce and product traceability, encouraging more structured and transparent data practices.
By examining these aspects, we aim to provide a comprehensive overview of the state of structured data in 2024, its recent evolution, and its future trajectory. Whether you’re a seasoned SEO professional, a web developer, an ecommerce strategist, or simply interested in the evolution of the web, this chapter offers valuable insights into how structured data is reshaping our digital world and paving the way for a more connected, transparent, and intelligent online experience.
Conclusion
The analysis of structured data in 2024 highlights a clear shift from its SEO roots toward a broader, more strategic role in AI and semantic metadata. The dominance of RDFa and Open Graph on over 60% of pages, combined with JSON-LD’s growth (now on 41% of pages, particularly in ecommerce), points to a maturing technology. But the true impact lies in how structured data is transforming AI discovery and enhancing machine understanding.
This year, we’ve seen significant changes in how search engines handle structured data. While Google has deprecated certain rich results, such as FAQs, HowTos, and SiteLinks, they’ve simultaneously introduced new types for vehicles, courses, 3D product models, loyalty cards, and certifications, expanding the scope of structured data. Even more importantly, structured data is now essential for AI systems, supporting tasks from fact-checking to improved search capabilities and training large language models (LLMs).
The advent of Digital Product Passports and increased adoption of GS1 standards underlines the growing importance of structured data in commerce and regulatory compliance. As AI-driven search becomes the norm, businesses are realizing that structured data is no longer just about search visibility—it’s key to ensuring content is machine-readable and future-proof.
For businesses developing their structured data strategy, the way forward is clear: implement it comprehensively, maintain it rigorously, and adapt continuously. New projects should focus on JSON-LD, while legacy formats should be preserved where appropriate. Systems must be built to scale and evolve alongside emerging technologies and standards.
In conclusion, the future of the web is structured, semantic, and increasingly intelligent. Organizations that invest on structured data today won’t just improve their search visibility – they are building the foundation for success in AI Discovery.
