Performance
Introduction
Il est incontestable que la lenteur a un effet néfaste sur l’expérience d’utilisation en général et, par conséquent, sur les conversions. Mais de mauvaises performances ne se traduisent pas seulement par de la frustration ou des effets négatifs sur les objectifs commerciaux, elles créent de véritable barrières à l’entrée. La pandémie mondiale de cette année a rendu ces obstacles encore plus évidents. Avec le développement de l’apprentissage à distance, du télétravail et de la socialisation en ligne, c’est toute notre vie qui s’est soudainement retrouvée sur Internet. La mauvaise connectivité et le manque d’accès à des appareils performants ont rendu ce changement douloureux, voire impossible, pour beaucoup. Ce fut un véritable test, mettant en évidence les inégalités de connectivité, d’appareils et de vitesse dans le monde entier.
Les outils de performance continuent d’évoluer pour décrire ces divers aspects de l’expérience d’utilisation et faciliter la recherche des problèmes sous-jacents. Depuis le chapitre Performance de l’année dernière, de nombreux développements importants ont eu lieu dans le domaine qui ont déjà transformé notre approche de la surveillance de la vitesse.
Par exemple, une version majeure du populaire outil d’audit de qualité, Lighthouse 6 (l’algorithme du célèbre score de performance a considérablement changé), et les scores ont également évolué. Les Signaux Web Essentiels (Core Web Vitals), un ensemble de nouveaux indicateurs décrivant différents aspects de l’expérience d’utilisation, sont désormais disponibles. Ils seront l’un des facteurs de classement des résultats de recherche à l’avenir, attirant l’attention de la communauté du développement sur de nouveaux signaux de vitesse.
Dans ce chapitre, nous examinerons les données de performance de terrain fournies par le Chrome User Experience Report (CrUX) à travers la lentille de ces ajouts ainsi que l’analyse d’une poignée d’autres mesures pertinentes. Il est important de noter qu’en raison des limitations d’iOS, les résultats du CrUX mobile n’incluent pas les appareils utilisant le système d’exploitation mobile d’Apple. Ce fait affectera indéniablement notre analyse, en particulier lorsque nous examinerons les valeurs des indicateurs de performances par pays.
Allons-y.
Le score de performance de Lighthouse
En mai 2020, est sorti Lighthouse 6. La nouvelle version majeure du très populaire logiciel d’audit de performance a apporté des changements notables à son algorithme de score de performance. Le score de performance est une représentation de haut niveau de la vitesse du site. Dans Lighthouse 6, le score est mesuré avec une échelle de six indicateurs, au lieu de cinq auparavant : le First Meaningful Paint et le First CPU Idle ont été supprimés et remplacés par le Largest Contentful Paint (LCP), le Total Blocking Time (TBT, l’équivalent en laboratoire du First Input Delay) et le Cumulative Layout Shift (CLS).
Le nouvel algorithme de notation donne la priorité à la nouvelle génération d’indicateurs des performance : les Signaux Web Essentiels (Core Web Vitals) et baisse la priorité des First Contentful Paint (FCP), Time to Interactive (TTI) et Speed Index, puisque leurs poids respectifs dans le score diminuent. L’algorithme met désormais aussi nettement l’accent sur trois aspects de l’expérience d’utilisation : l’interactivité (Total Blocking Time et Time to Interactive), la stabilité visuelle (Cumulative Layout Shift) et les chargements perçus (First Contentful Paint, Speed Index et Largest Contentful Paint).
En outre, le score est désormais calculé en utilisant différents points de référence pour les ordinateurs de bureau et les téléphones portables. En pratique, cela signifie qu’il sera moins indulgent sur ordinateur de bureau (en attendant des sites web rapides) et plus souple sur mobile (puisque les performances de référence sur mobile sont moins rapides que sur ordinateur de bureau). Vous pouvez comparer la différence de score de votre Lighthouse 5 et 6 dans le calculateur de score. Alors, comment les scores ont-ils réellement changé ?
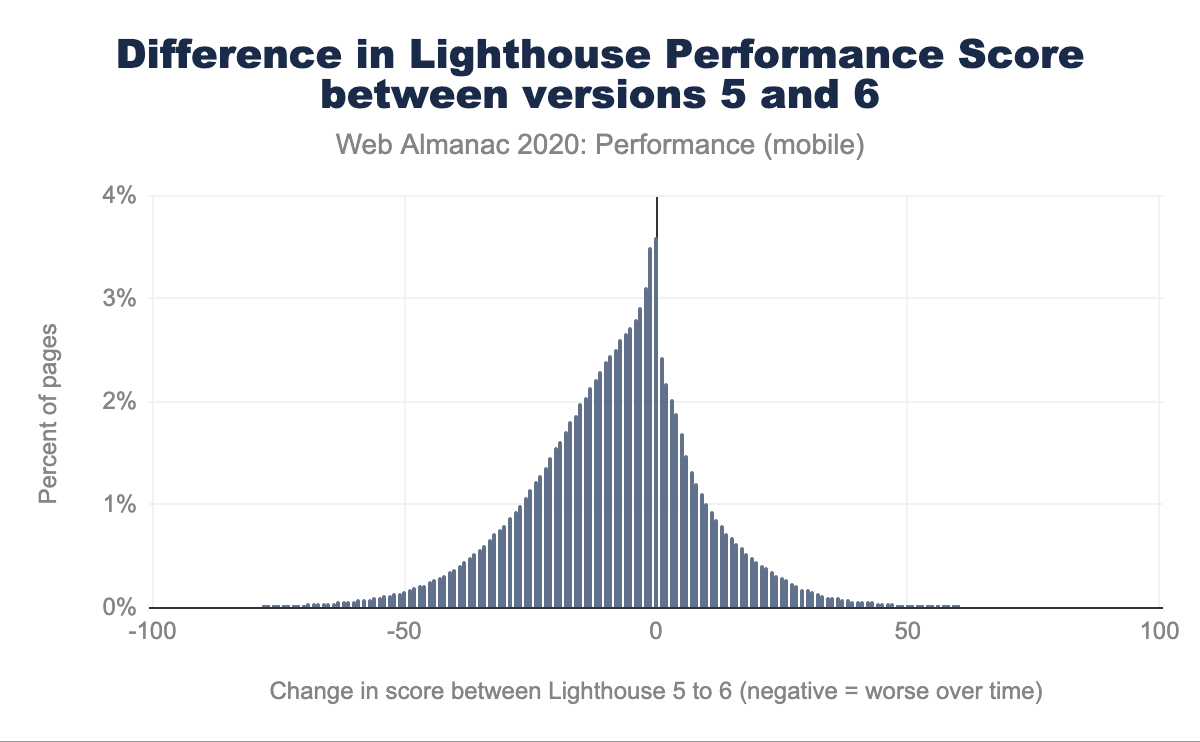
Ci-dessus, nous observons que 4 % des sites web n’ont enregistré aucun changement dans leur score de performance, mais le nombre de sites ayant enregistré des changements négatifs dépasse celui des sites dont le score s’est amélioré. Les notes de performance se sont détériorées (avec la courbe de diminution la plus marquée dans la zone des 10-25 points), ce qui est illustré encore plus directement ci-dessous :
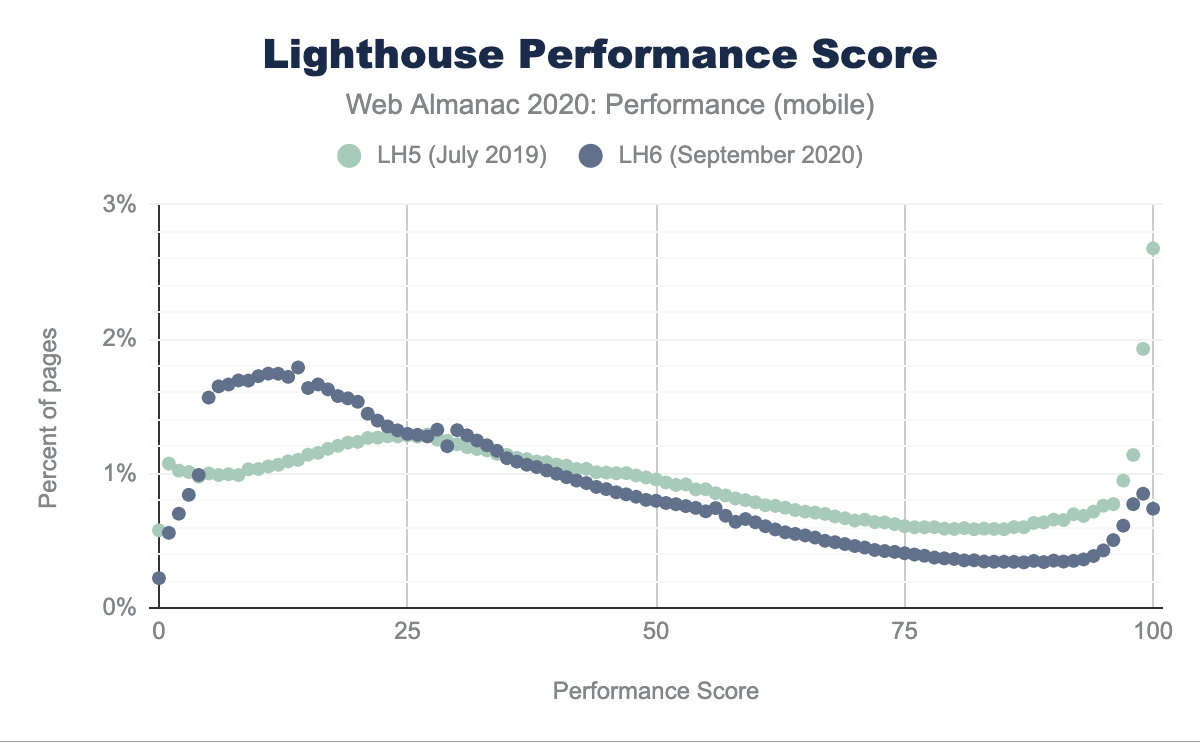
En comparant Lighthouse 5 et 6, nous pouvons directement observer comment la répartition des points a changé. Avec l’algorithme de Lighthouse 6, nous observons une augmentation du pourcentage de pages recevant des notes entre 0 et 25 et une diminution entre 50 et 100. Alors que dans Lighthouse 5, nous avons vu 3 % des pages recevant une note de 100, dans Lighthouse 6, ce chiffre est tombé à seulement 1 %.
Ces changements globaux ne sont pas inattendus compte tenu d’une multitude de modifications apportées à l’algorithme lui-même.
Core Web Vitals : le Largest Contentful Paint
Le Largest Contentful Paint (LCP) est une mesure temporelle de référence qui indique le moment où le plus grand élément au-dessus du pli (traduction française) a été affiché.
LCP par matériel
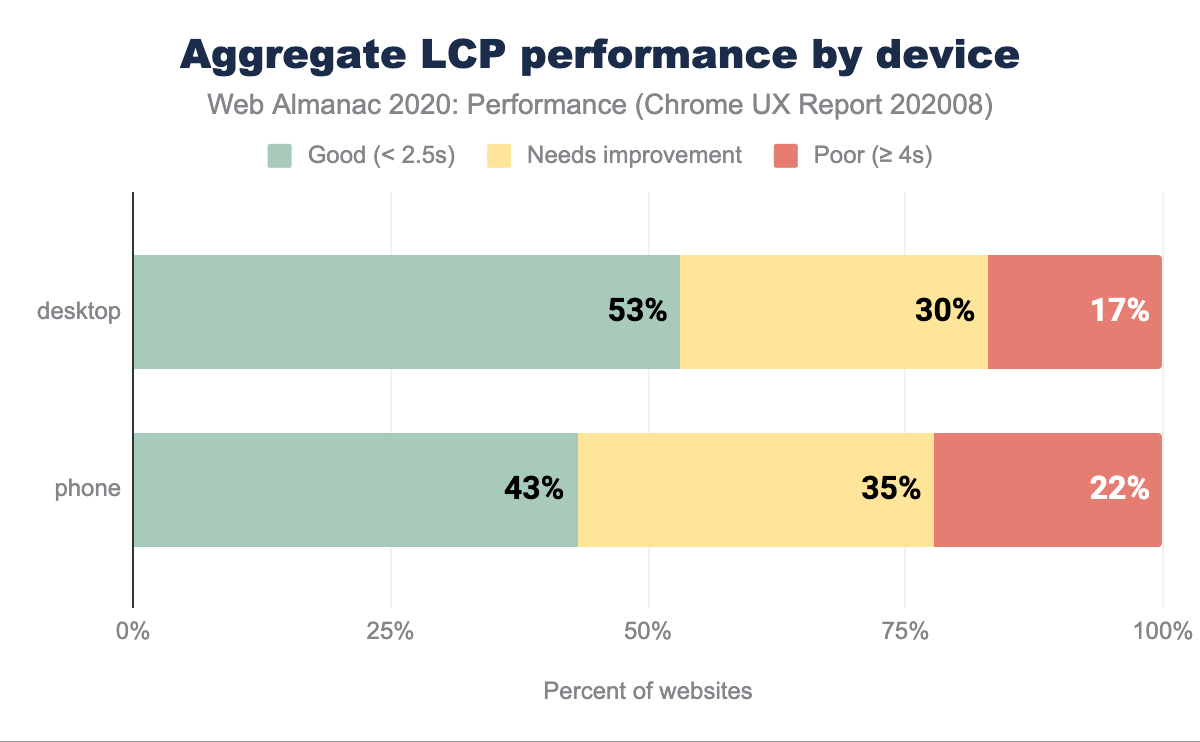
Dans le graphique ci-dessus, on peut observer qu’entre 43 % et 53 % des sites web ont de bonnes performances en matière de LCP (en dessous de 2,5 s) : la majorité des sites web parviennent à hiérarchiser et à charger rapidement leurs médias critiques et au-dessus du pli. Pour une mesure relativement nouvelle, c’est un bon signal. Le léger écart entre les ordinateurs de bureau et les téléphones portables est probablement dû à la variation de la vitesse du réseau, des capacités des appareils et de la taille des images (les grandes images spécifiques aux ordinateurs de bureau mettront plus de temps à être téléchargées et affichées).
LCP par répartition géographique
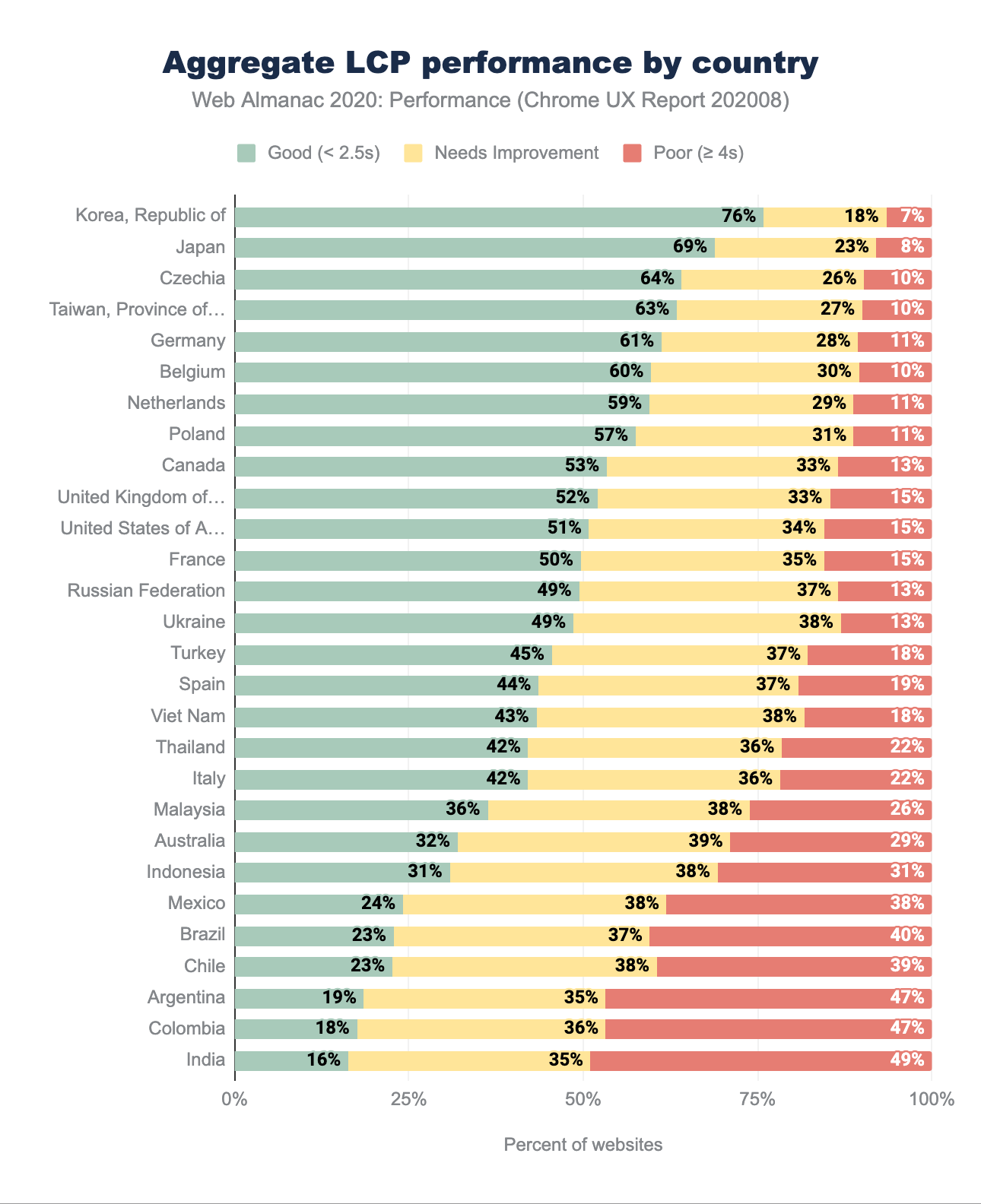
Le pourcentage le plus élevé de bonnes mesures du LCP est principalement réparti entre les pays européens et asiatiques, la République de Corée (Corée du Sud) étant en tête avec 76 % de bonnes mesures. La Corée du Sud est un leader constant en matière de vitesse de téléphonie mobile, avec une impressionnante vitesse de téléchargement de 145 Mo/s selon le Speedtest Global Index pour le mois d’octobre. Le Japon, la République tchèque, Taïwan, l’Allemagne et la Belgique sont également quelques pays qui offrent des débits mobiles élevés et fiables. L’Australie, bien que leader en matière de vitesse des réseaux mobiles, est désavantagée par la lenteur des connexions de bureau et la latence, ce qui la place dans la partie inférieure du classement ci-dessus.
L’Inde reste la dernière de notre série de données, avec seulement 16 % de bonnes expériences. Alors que la population de personnes se connectant à Internet pour la première fois ne cesse de croître, les vitesses des réseaux mobiles et de bureau sont toujours un problème, avec des téléchargements moyens de 10 Mo/s pour la 4G, 3 Mo/s pour la 3G et moins de 50 Mo/s pour le bureau.
LCP par type de connexion
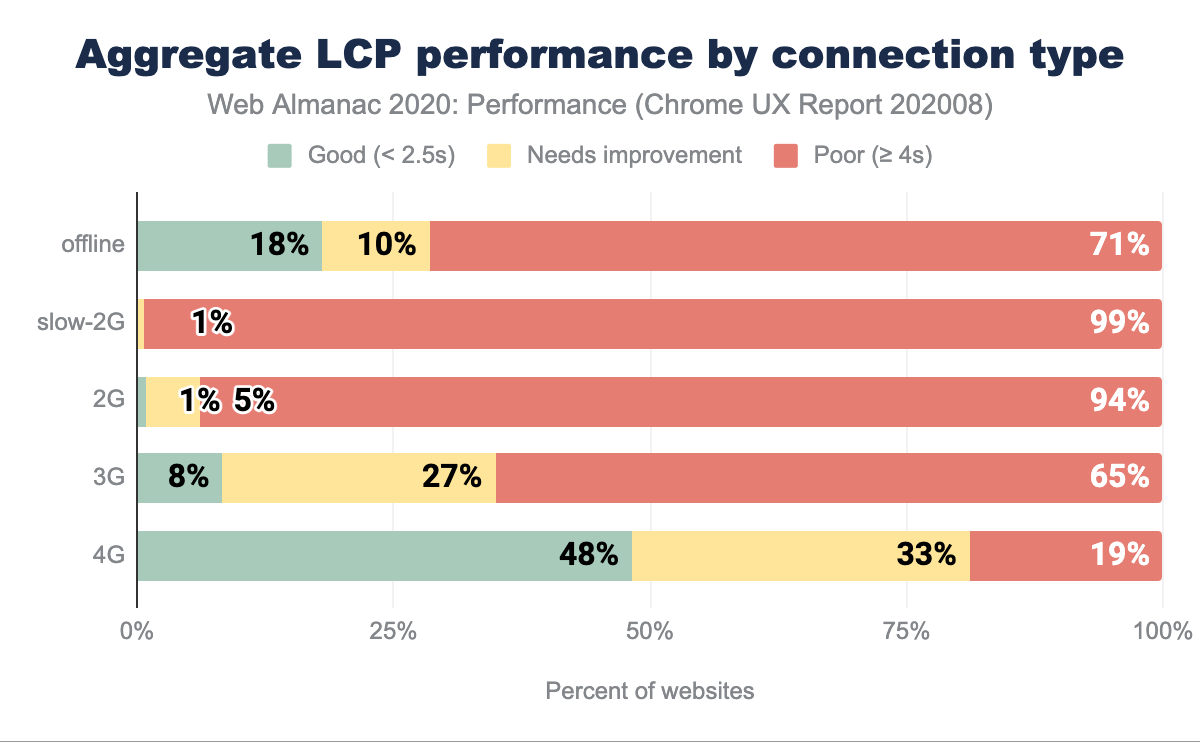
Comme le LCP est un indicateur permettant de voir quand le plus grand élément au-dessus du pli a été affiché (y compris les images, les vidéos ou les éléments de type bloc contenant du texte), il n’est pas surprenant que les mesures soient médiocres lorsque le réseau est lent.
Il existe une corrélation évidente entre la vitesse du réseau et de meilleures performances du LCP, mais même sur la 4G, seuls 48 % des résultats sont classés comme bons, ce qui laisse la moitié des analyses dans la cas « à améliorer ». L’automatisation de l’optimisation des médias, la transmission des bonnes dimensions et des bons formats, ainsi que l’optimisation pour le mode « Low Data », pourraient aider à faire bouger les choses. Apprenez-en plus sur l’optimisation du LCP dans ce guide (traduction française).
Core Web Vitals : le Cumulative Layout Shift
Le Cumulative Layout Shift (CLS) quantifie la façon dont les éléments affichés à l’écran se déplacent pendant la visite de la page. Il permet de déterminer le degré de mouvement inattendu sur vos sites web afin d’évaluer l’expérience d’utilisation, plutôt que d’essayer de mesurer une partie spécifique de l’interaction à l’aide d’une unité comme les secondes ou les millisecondes.
En ce sens, le CLS est un nouveau type de mesure holistique de l’UX, différent des autres mesures mentionnées dans ce chapitre.
CLS par matériel
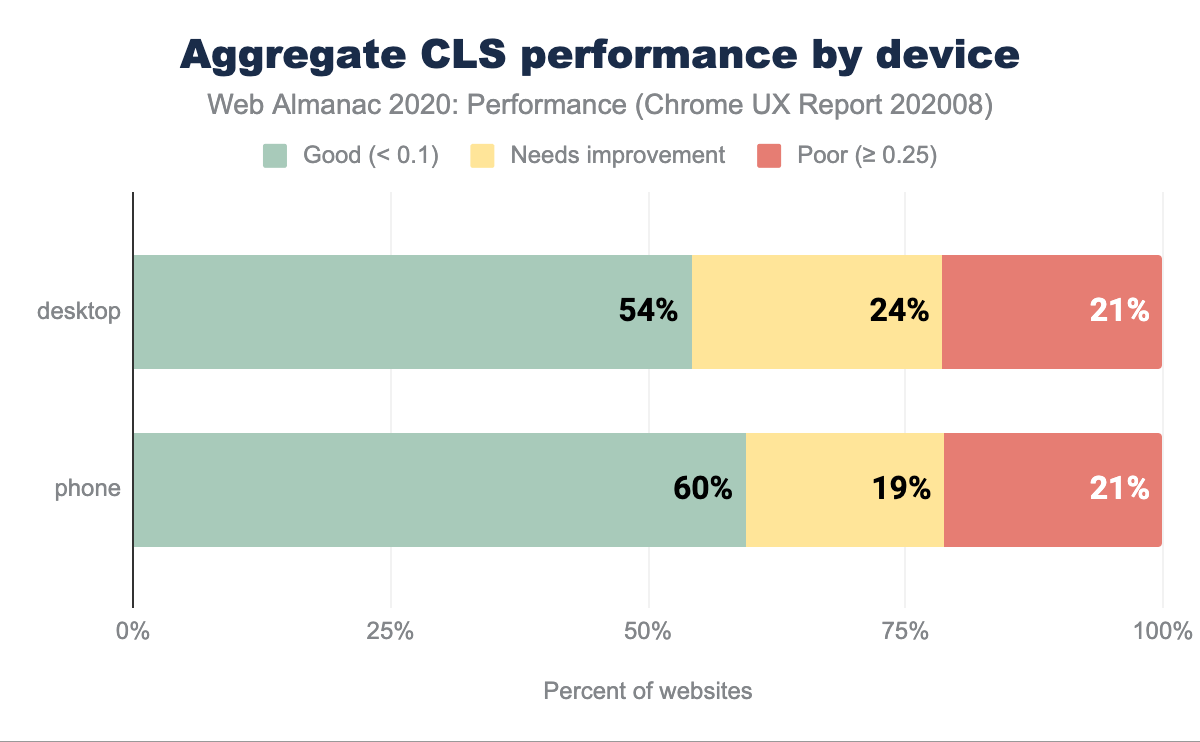
Selon les données du CrUX, tant pour les appareils de bureau que pour les appareils mobiles, plus de la moitié des sites web ont un bon score CLS. Il y a une légère différence (6 points de pourcentage) entre le nombre de sites web bien notés pour les ordinateurs de bureau et les téléphones portables, ce qui favorise ces derniers. On peut supposer que les téléphones sont en tête des bonnes notes CLS en raison des expériences optimisées pour les mobiles qui ont tendance à être moins riches en fonctionnalités et en images.
CLS par répartition géographique
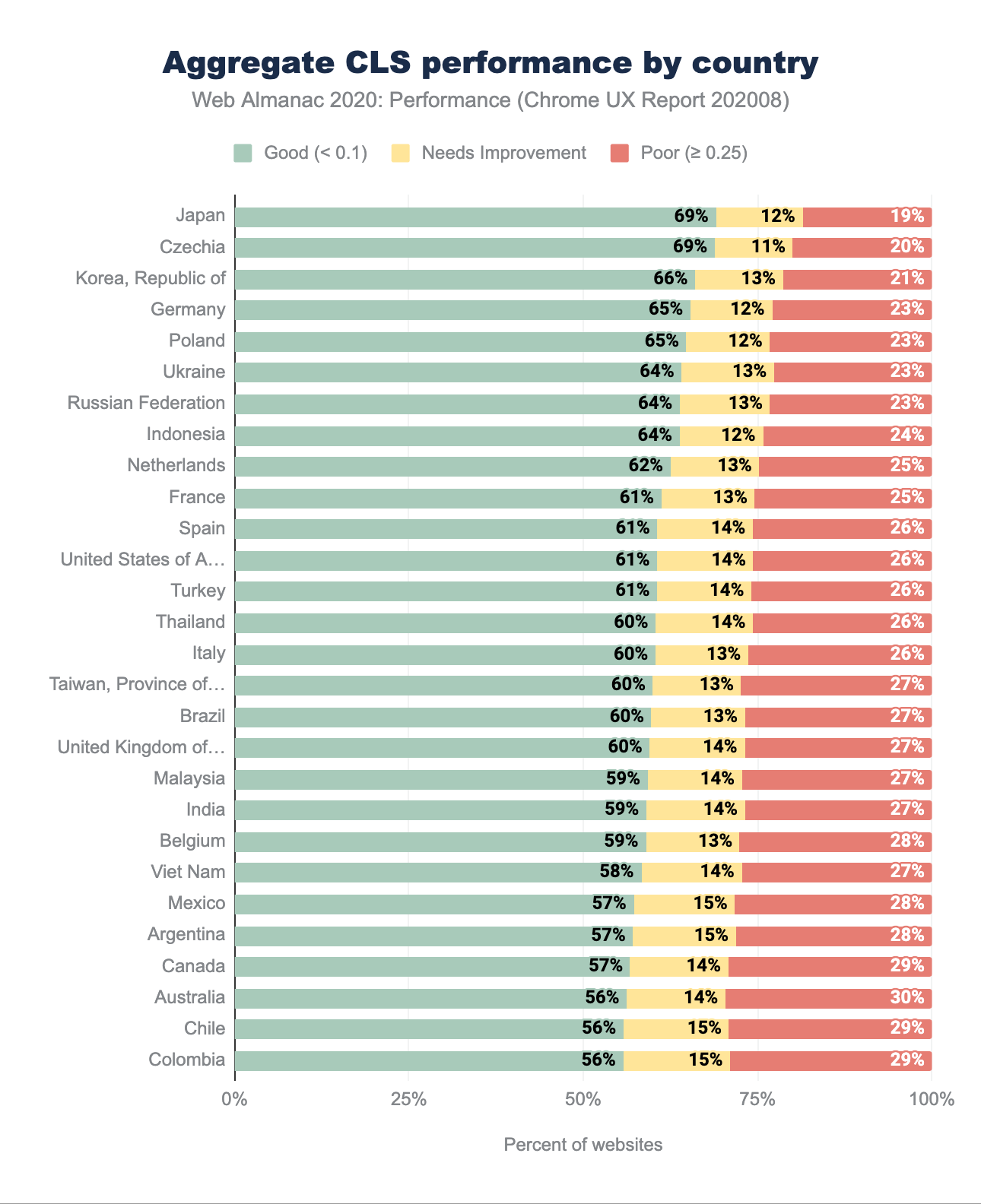
Les performances du CLS dans les différentes régions géographiques sont majoritairement bonnes, avec au moins 56 % des sites ayant une bonne note. C’est une excellente nouvelle pour la stabilité visuelle perçue. Nous pouvons observer les mêmes pays en tête, comme nous l’avons vu dans la répartition géographique du LCP - République de Corée, Japon, Tchéquie, Allemagne, Pologne.
La stabilité visuelle est moins affectée par la géographie et la latence que d’autres mesures, comme le LCP. La différence de pourcentage de bonnes notes entre le pays en tête et le pays en queue de peloton est de 61 % pour le LCP et de seulement 13 % pour le CLS. Le pourcentage de sites web ayant obtenu une note modérée est relativement faible dans l’ensemble, laissant place à 19 à 29 % de mauvaises expériences dans l’ensemble. Il existe de nombreux facteurs qui peuvent contribuer à un mauvais CLS - apprenez comment les traiter dans le guide d’optimisation du Cumulative Layout Shift (traduction française).
CLS par type de connexion
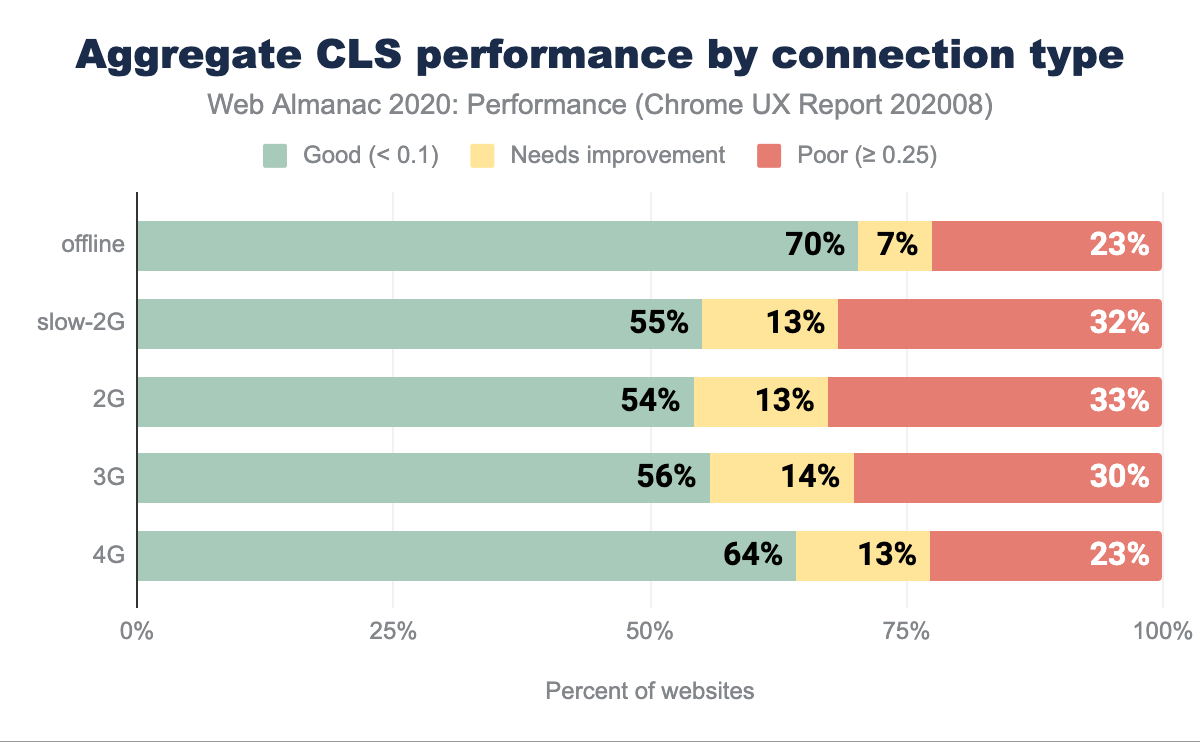
La répartition des scores CLS est raisonnablement homogène pour la plupart des types de connexion, à l’exception des connexions hors ligne et de la 4G. Dans le scénario hors ligne, on peut supposer que les Service Workers délivrent les sites web. Par conséquent, il n’y a pas de retard dans le téléchargement causé par le type de connexion, ce qui explique la part la plus importante de bonnes notes.
Il est difficile de tirer des conclusions définitives sur la 4G, mais on peut supposer que les connexions 4G+ sont peut-être utilisées comme méthode d’accès à Internet sur les appareils de bureau. Si cette hypothèse était valable, les polices de caractères et les images du web pourraient être mises en cache de manière importante, ce qui a un effet positif sur les mesures du CLS.
Core Web Vitals : le First Input Delay
Le First Input Delay (FID) mesure le temps entre la première interaction d’un utilisateur ou d’une utilisatrice et le moment où le navigateur est capable de répondre à cette interaction. Le FID est un bon indicateur du degré d’interactivité de vos sites web.
FID par matériel
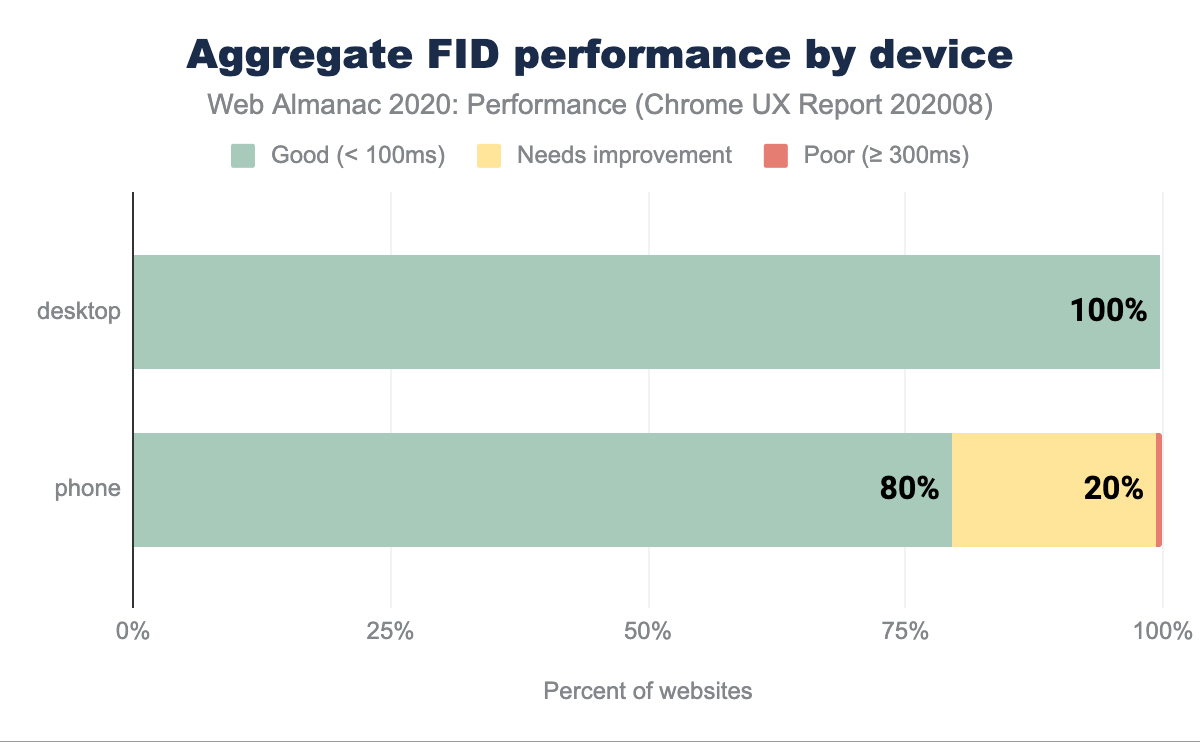
Il est relativement rare de voir de bons scores répartis sur un pourcentage aussi élevé de sites web. Sur le bureau, sur la base du 75e percentile des distributions des sites, 100 % des sites font état de temps rapides pour le FID, ce qui signifie que le nombre de personnes subissant des retards d’interaction est très faible.
Sur mobile, 80 % des sites sont classés comme bons. Une explication probable est la capacité réduite du CPU par rapport à un ordinateur de bureau, la latence du réseau sur les mobiles (qui entraîne un retard dans le téléchargement et l’exécution des scripts) ainsi que l’efficacité de la batterie et les limites de température, qui plafonnent le potentiel du CPU des appareils mobiles. Tous ces facteurs ont une incidence directe sur les mesures d’interactivité comme le FID.
FID par répartition géographique
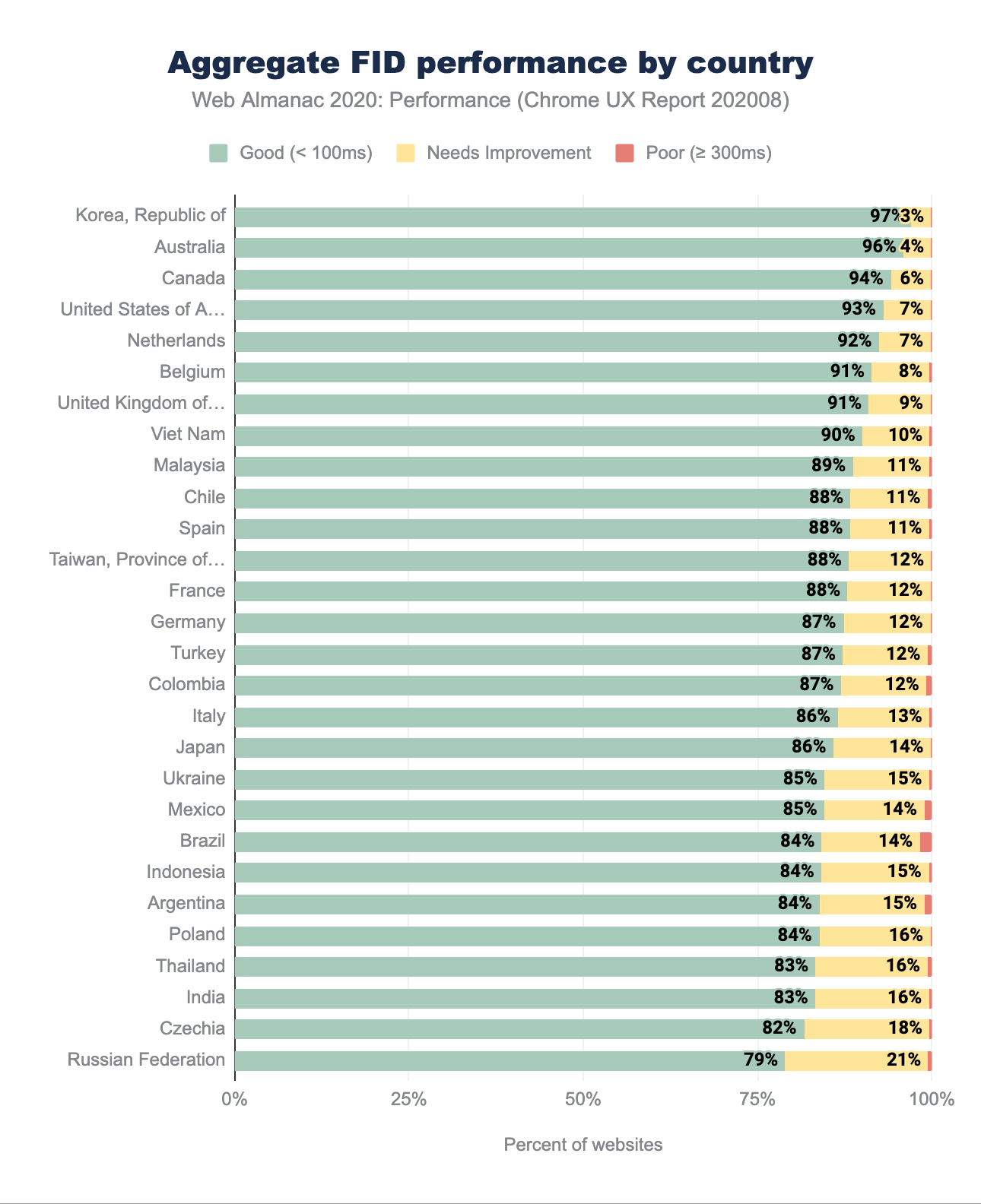
La répartition géographique des scores du FID confirme les conclusions du tableau agrégé des appareils, partagé précédemment. Au pire, 79 % des sites web ont un bon FID, avec un impressionnant 97 % en première position, la République de Corée étant de nouveau en tête. Il est intéressant de noter que certains des principaux prétendants au classement CLS et LCP, tels que la République tchèque, la Pologne, l’Ukraine et la Fédération de Russie, se retrouvent ici au bas du classement.
Encore une fois, il n’est pas facile de déterminer les raisons de cette situation. Si l’on suppose que le FID est en corrélation avec les capacités d’exécution de JavaScript, les pays où les appareils les plus performants sont plus chers et traités comme des articles de luxe devraient afficher un meilleur FID. La Pologne est un bon exemple - avec l’un des prix les plus élevés pour l’iPhone en comparaison du marché US, combiné avec des revenus relativement faibles, un seul salaire n’est pas suffisant pour acheter le produit phare d’Apple. Pour contraster, les Australiens touchant un salaire moyen pourraient acheter un iPhone avec une semaine de salaire. Heureusement, le pourcentage de sites web ayant une faible note se situe pour la plupart à 0, à quelques exceptions près (1 à 2 %), ce qui indique une réaction relativement rapide lors d’une interaction.
FID par type de connexion
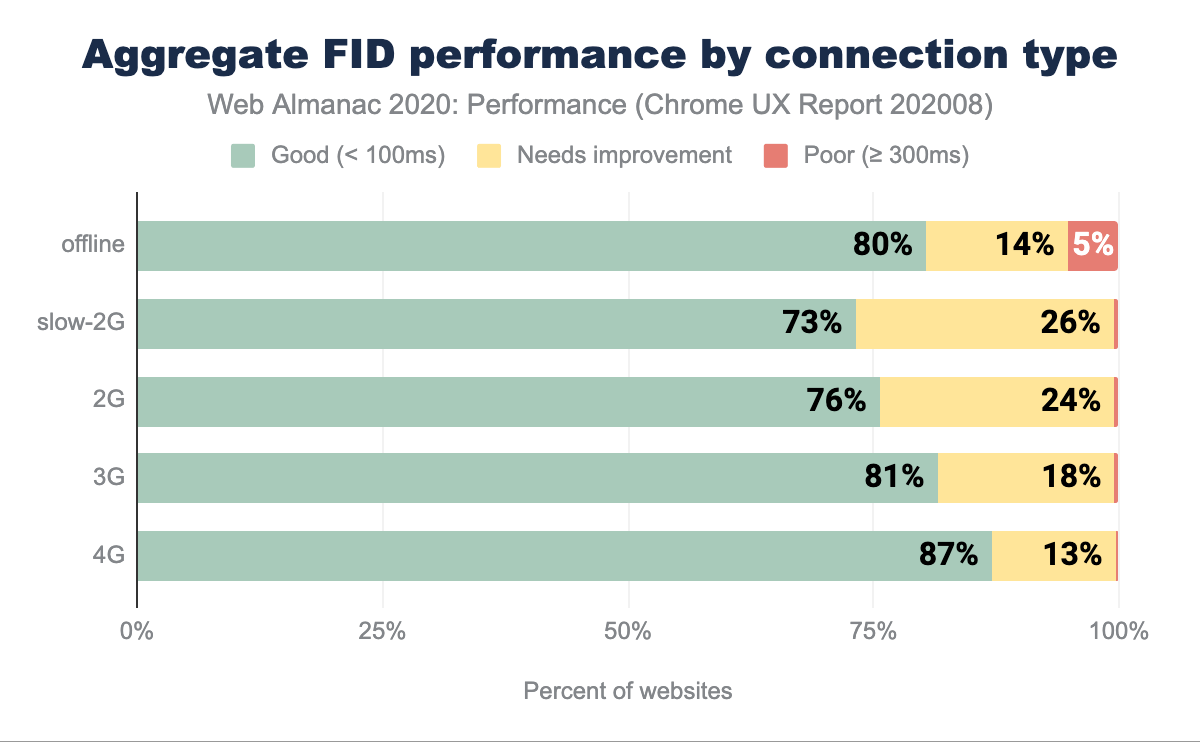
Nous pouvons observer une corrélation directe entre la vitesse du réseau et la rapidité du FID, allant de 73 % sur les réseaux 2G à 87 % sur les réseaux 4G. Des réseaux plus rapides permettent un téléchargement plus rapide des scripts, ce qui accélère le début de l’analyse et réduit le nombre de tâches bloquant le fil conducteur. De tels résultats sont encourageants, surtout lorsque le taux d’expériences de sites mal notés ne dépasse pas 5 %.
First Contentful Paint
First Contentful Paint (FCP) mesure la première fois que le navigateur a affiché un texte, une image, un canvas non blanc ou un contenu SVG. Le FCP est un bon indicateur de la vitesse perçue, car il indique le temps d’attente avant de voir les premiers signes de chargement d’un site.
FCP par matériel
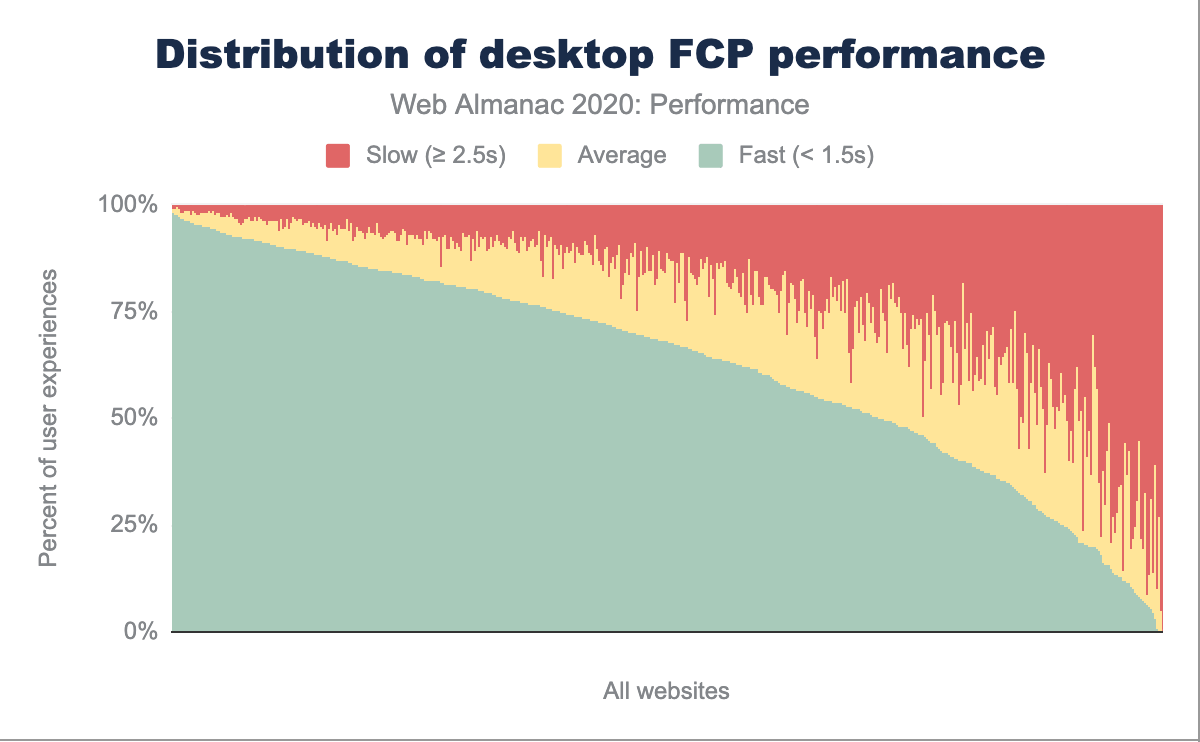
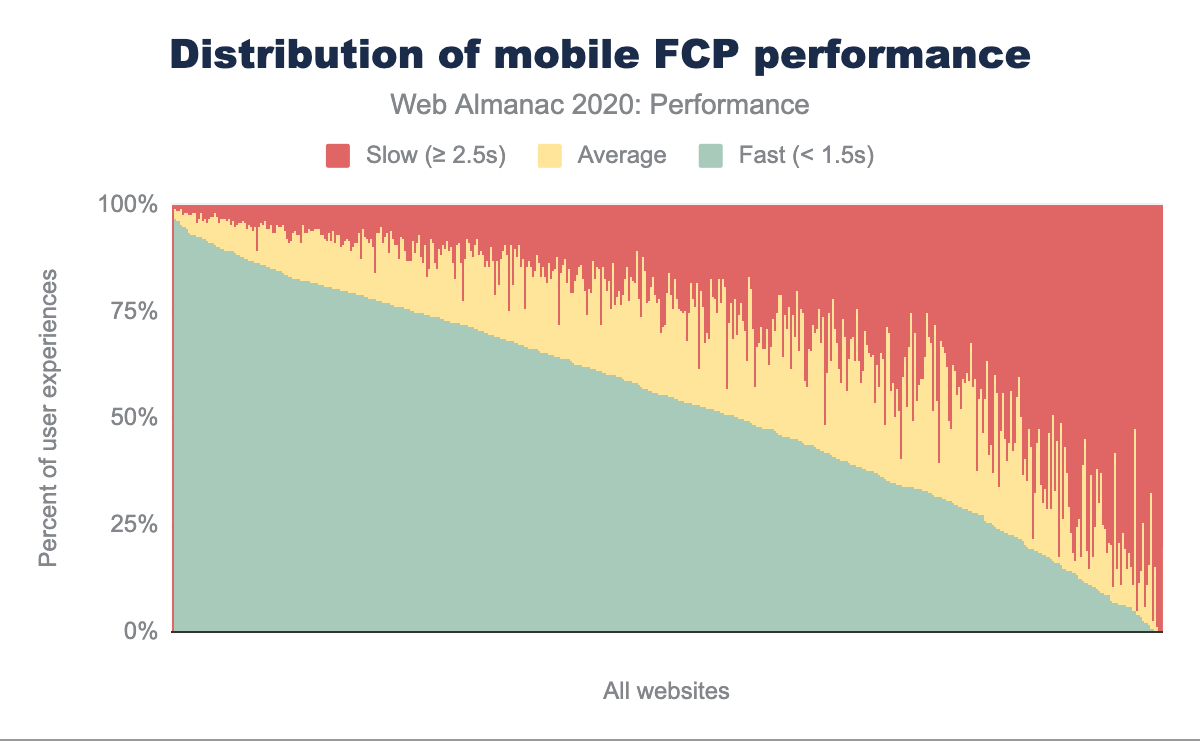
Dans les graphiques ci-dessus, les distributions de FCP sont réparties entre les ordinateurs de bureau et les téléphones portables. Par rapport à l’année dernière, on constate une diminution notable des relevés FCP moyens, tandis que le pourcentage d’expériences d’utilisation rapides et lentes a augmenté quel que soit le type d’appareil. Nous pouvons toujours observer la même tendance, à savoir que les personnes utilisant des téléphones portables connaissent plus fréquemment des FCP plus lents que celles qui utilisent des ordinateurs de bureau. Dans l’ensemble, ces personnes sont plus susceptibles d’avoir une bonne ou une mauvaise expérience, plutôt qu’une expérience moyenne.
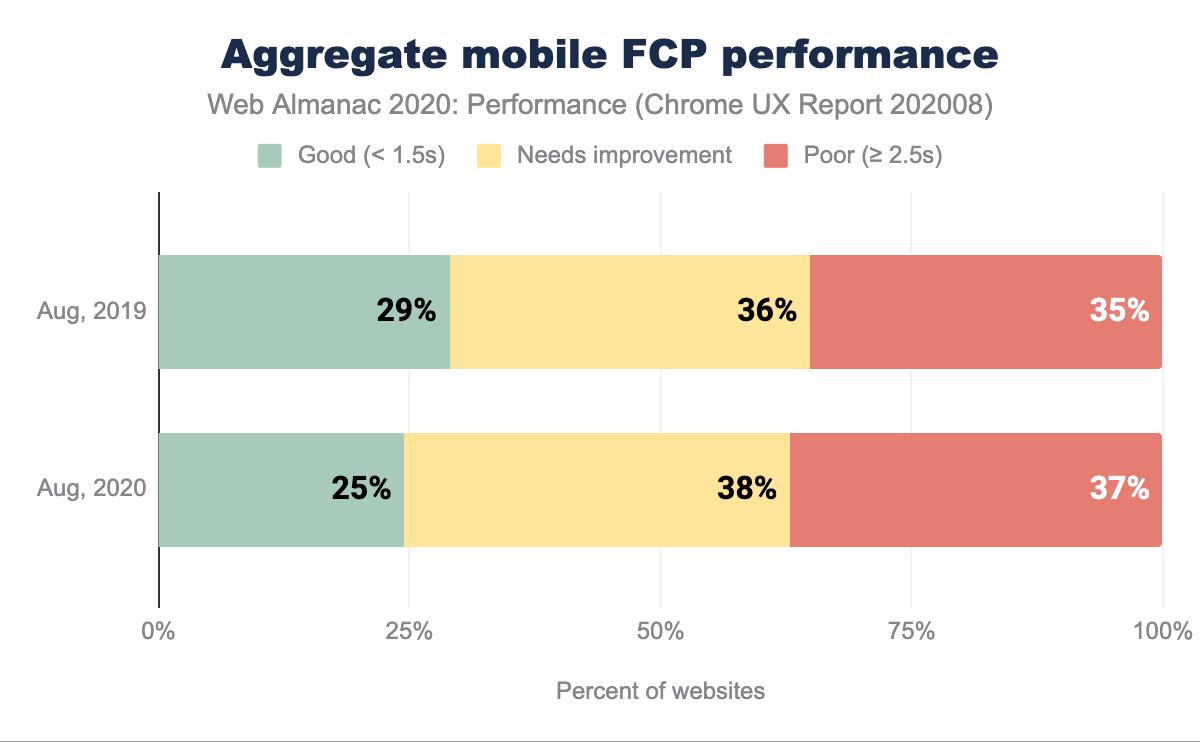
En comparant le FCP sur les appareils mobiles sur une base annuelle, nous observons moins de bonnes expériences et plus d’expériences modérées et mauvaises. 75 % des sites web ont un FCP inférieur à la moyenne. Nous pouvons supposer que ce pourcentage élevé de mesures de FCP inférieures à l’idéal est une source de frustration et de dégradation de l’expérience d’utilisation.
De nombreux facteurs peuvent retarder le rendu, comme la latence du serveur (mesurée par une poignée d’indicateurs, tels que Time to First Byte (TTFB) et RTT), le blocage des requêtes JavaScript, ou la manipulation inappropriée des polices personnalisées, pour n’en citer que quelques-uns.
FCP par répartition géographique
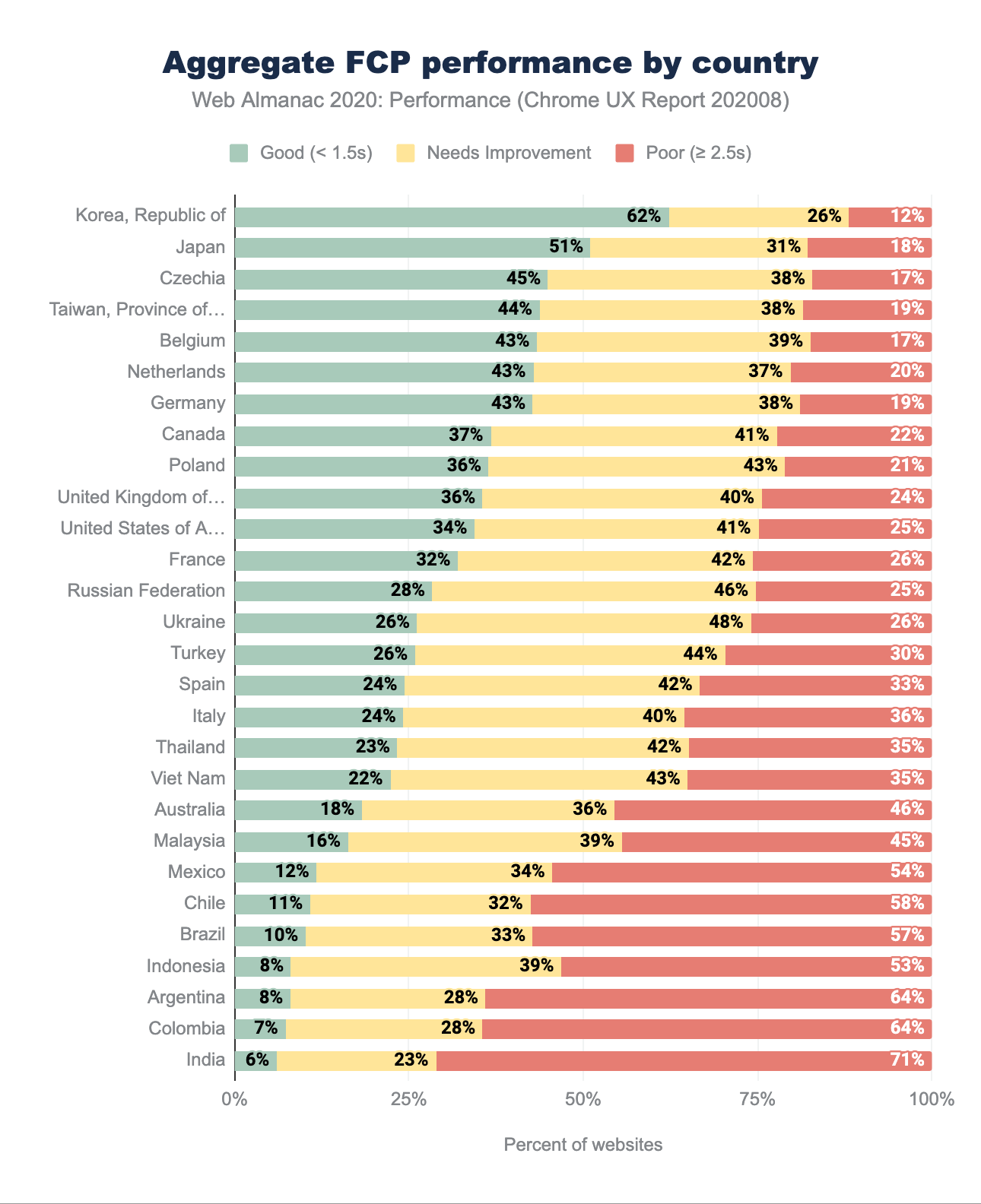
Avant d’approfondir l’analyse, il convient de mentionner que dans le chapitre sur les performances de 2019, les seuils de classification « bon » et « mauvais » étaient différents de ceux de 2020. En 2019, les sites avec un FCP inférieur à 1 s étaient considérés comme bons, tandis que ceux avec un FCP supérieur à 3 s étaient classés comme mauvais. En 2020, ces fourchettes sont passées à 1,5 s pour les bons et à 2,5 s pour les mauvais.
Ce changement signifie que la distribution se déplacerait vers des sites web mieux notés et moins bien notés. Nous pouvons observer cette tendance par rapport aux résultats de l’année dernière, à mesure que le pourcentage de bon et de mauvais sites web augmente. Les dix premières régions géographiques ayant le taux le plus élevé de sites web rapides restent relativement inchangées par rapport à 2019, avec l’ajout de la République Tchèque et de la Belgique et la chute des États-Unis et du Royaume-Uni. La République de Corée est en tête avec 62 % des sites web qui déclarent un FCP rapide, soit près du double de l’année dernière (ce qui, une fois encore, est probablement dû à la redistribution des résultats). Les autres pays en tête du classement doublent également le nombre de bonnes expériences.
Alors que le pourcentage des résultats moyens (« à améliorer ») diminue, le nombre de sites ayant de mauvais résultats augmente, ce qui est particulièrement prononcé dans le bas du classement avec les régions d’Amérique latine et d’Asie du Sud.
Là encore, il existe plusieurs facteurs ayant une incidence négative sur le FCP, tels que les mauvaises valeurs du TTFB, mais il est difficile de les confirmer sans le contexte nécessaire. Par exemple, si nous devions analyser les performances de pays spécifiques, tels que l’Australie, nous trouverions étonnamment qu’elles se situent dans la partie inférieure. L’Australie a l’un des niveaux de pénétration des smartphones les plus élevés au monde, l’un des réseaux de téléphonie mobile les plus rapides et des niveaux de revenus moyens relativement élevés. On pourrait facilement supposer qu’il devrait être plus élevé. Cependant, compte tenu de la lenteur des connexions fixes, de la latence et de l’absence de représentation d’iOS dans le CrUX, son positionnement commence à être plus logique. Avec un exemple comme celui-ci (que nous n’avons effleuré qu’en surface), nous pouvons voir à quel point il serait difficile de comprendre le contexte de chacun des pays.
FCP par type de connexion
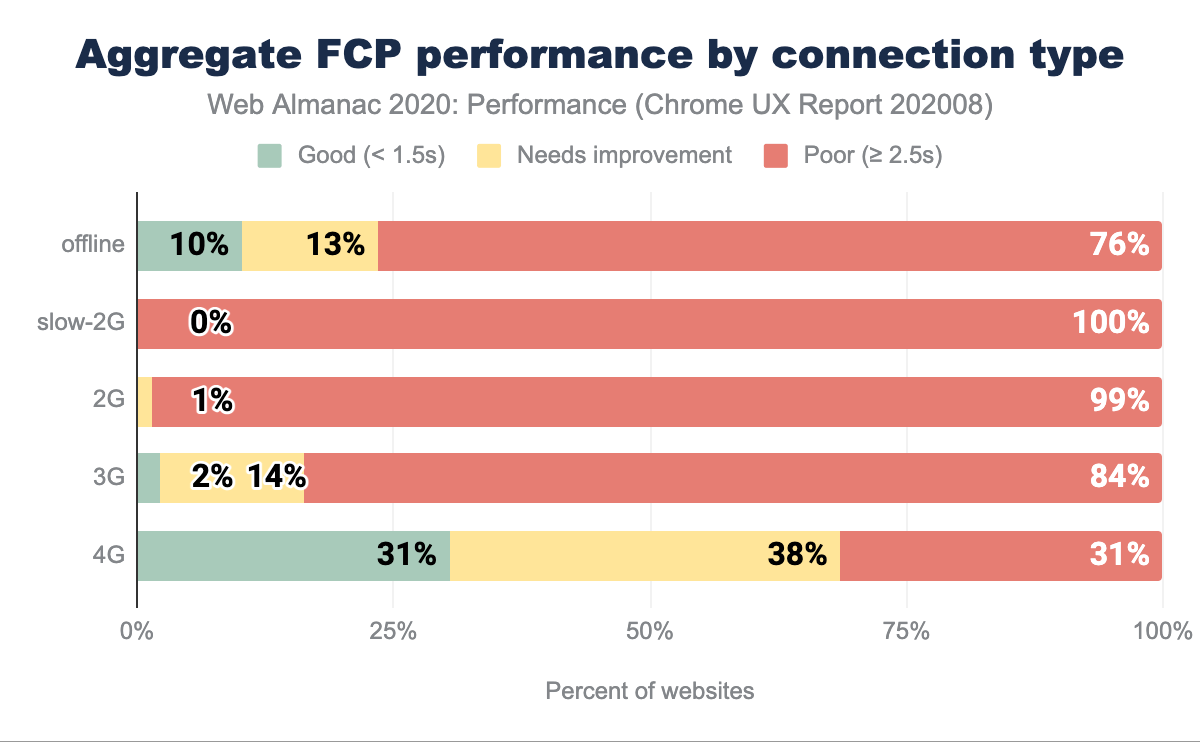
Comme d’autres mesures, le FCP est affecté par les vitesses de connexion. Sur la 3G, seulement 2 % des expériences sont bonnes, tandis que sur la 4G, 31 %. Ce n’est pas un niveau de performance idéal pour le FCP, mais il s’est amélioré depuis 2019 dans certains domaines, qui pourraient à nouveau être influencés par le changement de catégorisation des bonnes et mauvaises performances. Nous constatons la même augmentation du pourcentage de bons et de mauvais sites web, ce qui réduit le nombre de sites moyens (« à améliorer »).
Cette tendance illustre l’aggravation de la fracture numérique, où les expériences sur des réseaux plus lents et des appareils potentiellement moins performants sont toujours plus mauvaises. L’amélioration du FCP sur les connexions lentes est en corrélation directe avec l’amélioration du TTFB, que nous observons dans le graphique des performances agrégées du TTFB par type de connexion. Un TTFB faible = un FCP faible.
Le choix d’un hébergeur ou d’un CDN aura un effet en cascade sur la vitesse. En prenant ces décisions afin d’optimiser au mieux la livraison de contenu, on contribuera à améliorer le FCP et le TTFB, en particulier sur les réseaux les plus lents. Le FCP est également fortement influencé par le temps de chargement des polices, de sorte que s’assurer que le texte est visible pendant le téléchargement des polices sur le web est également une stratégie intéressante (en particulier lorsque, sur des connexions plus lentes, ces ressources seront coûteuses à récupérer).
En examinant les statistiques « hors ligne », nous pouvons déduire qu’un nombre important de questions relatives au FCP ne sont pas corrélées au type de réseau. Nous n’observons pas de gains significatifs dans cette catégorie, ce qui serait le cas si cette affirmation était vraie. Il semblerait que le rendu ne soit pas tant retardé par la récupération de JavaScript, mais qu’il soit affecté par l’analyse et l’exécution.
Time to First Byte
Le Time to First Byte (TTFB) est le temps écoulé entre la requête initiale du contenu HTML et la réception du premier octet par le navigateur. Les problèmes de rapidité de traitement des requêtes peuvent rapidement se répercuter sur d’autres mesures de performance, car ils retardent non seulement le rendu, mais aussi la récupération des ressources.
TTFB par matériel
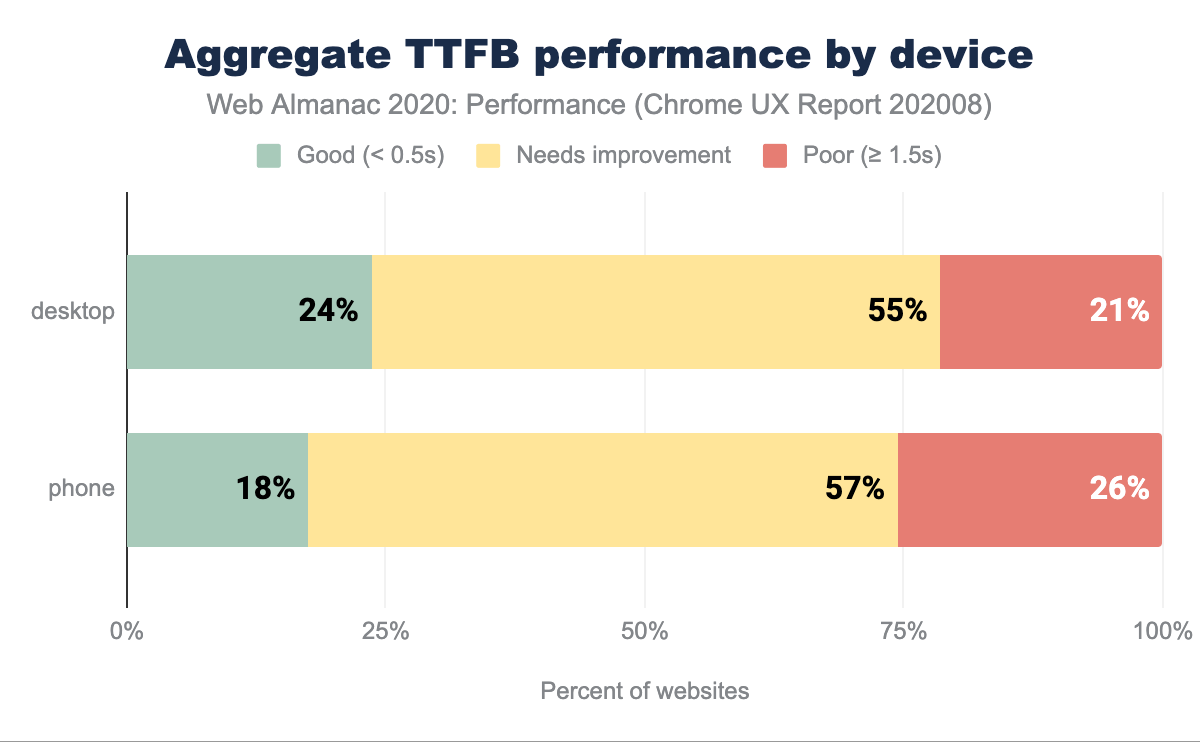
Sur les ordinateurs de bureau, 76 % des sites web ont un « mauvais » TTFB, tandis que sur les téléphones portables, ce pourcentage passe à 83 %. On peut supposer que les données montrent que la TTFB est une mesure souvent négligée, alors que la plupart des mesures et des efforts se concentrent sur le front-end et le rendu visuel, et non sur la diffusion des ressources et le travail côté serveur. Un TTFB élevé aura un impact direct et négatif sur une pléthore d’autres signaux de performance, ce qui est un domaine qui doit encore être abordé.
TTFB par répartition géographique
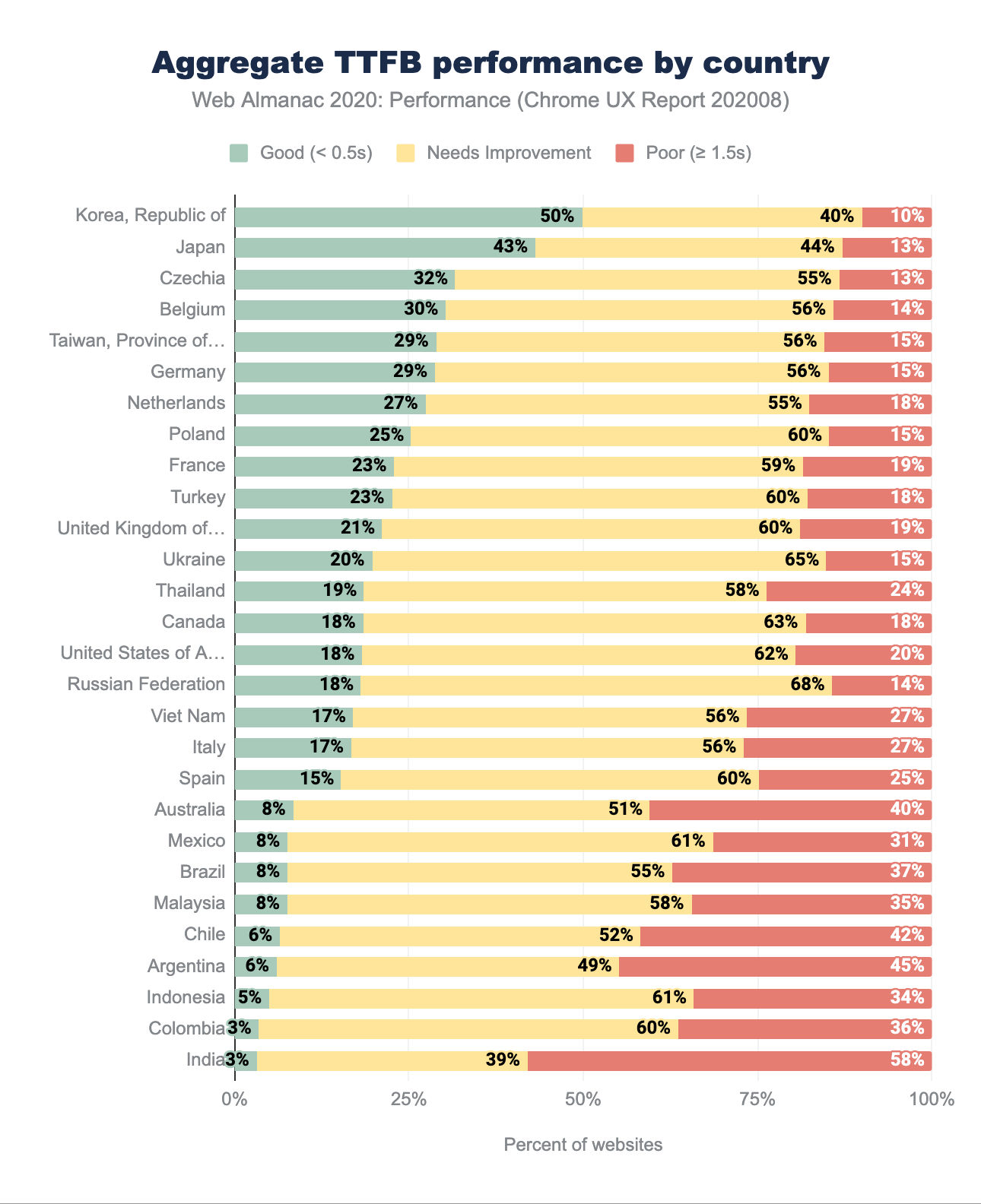
La comparaison des données géographiques du TTFB de cette année avec les résultats de 2019 montre une fois de plus que les sites web sont plus rapides, mais comme pour le FCP, les seuils ont changé. Auparavant, nous considérions les TTFB inférieurs à 200 ms comme rapides et supérieurs à 1000 ms comme lents. En 2020, la TTFB en dessous de 500 ms est bonne et au-dessus de 1500 ms, mauvaise. Des changements aussi importants dans la classification peuvent expliquer que nous observons des changements significatifs, comme une augmentation de 36 % des bonnes expériences de sites web en République de Corée ou de 22 % à Taïwan. Dans l’ensemble, nous observons toujours les mêmes régions en tête, telles que l’Asie-Pacifique et certaines régions européennes.
TTFB par type de connexion
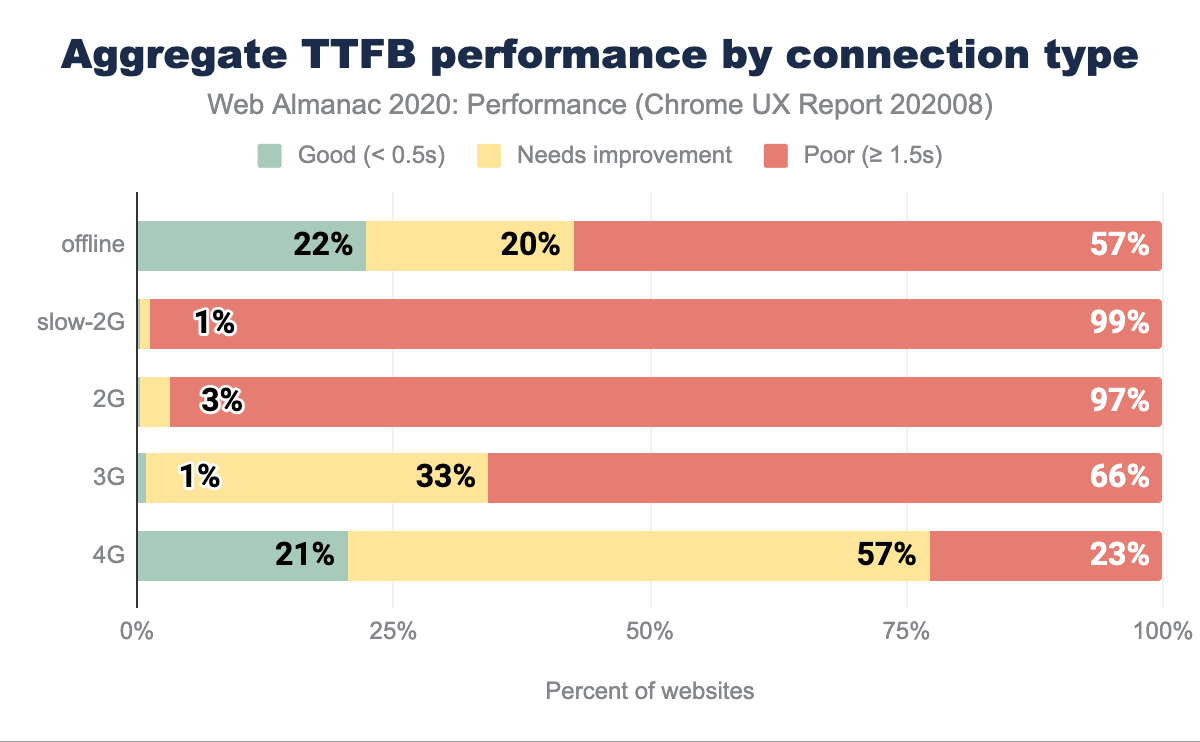
Le TTFB est affecté par la latence du réseau et le type de connexion. Plus la latence est élevée et plus la connexion est lente, plus les mesures de la TTFB sont mauvaises, comme nous pouvons l’observer ci-dessus. Même sur les connexions mobiles considérées comme rapides (4G), seuls 21 % des sites web ont un TTFB rapide. Il n’y a pratiquement aucun site classé comme rapide en dessous de la 4G.
Si on examine les vitesses de téléphonie mobile dans le monde pour la période décembre 2018-novembre 2019, on constate que, dans le monde, les connexions mobiles ne sont pas à haut débit. Ces vitesses et normes technologiques pour les réseaux cellulaires (comme la 5G) ne sont pas réparties de manière égale et affectent le TTFB. Par exemple, voir cette carte des réseaux au Nigeria - la plupart des régions du pays ont une couverture 2G et 3G, avec une faible portée en 4G.
Ce qui est surprenant, c’est le nombre relativement identique de bons résultats de TTFB entre les sources hors ligne et 4G. En ce qui concerne les travailleurs du secteur des services, on pourrait s’attendre à ce que certains des problèmes liés au TTFB soient atténués, mais cette tendance ne se reflète pas dans le graphique ci-dessus.
Utilisation des Performance Observers
Il existe des dizaines de mesures différentes, orientées utilisation, qui peuvent être utilisées pour évaluer les sites web et les applications. Cependant, il arrive que les mesures prédéfinies ne correspondent pas tout à fait à nos scénarios et besoins spécifiques. L’API PerformanceObserver nous permet d’obtenir des données de mesure personnalisées grâce à l’API User Timing, l’API Long Task, l’API Event Timing et une poignée d’autres API de bas niveau. Par exemple, avec leur aide, nous pourrions enregistrer les transitions temporelles entre les pages ou quantifier l’hydratation des applications en Server Side Rendering (SSR, rendues côté serveur).
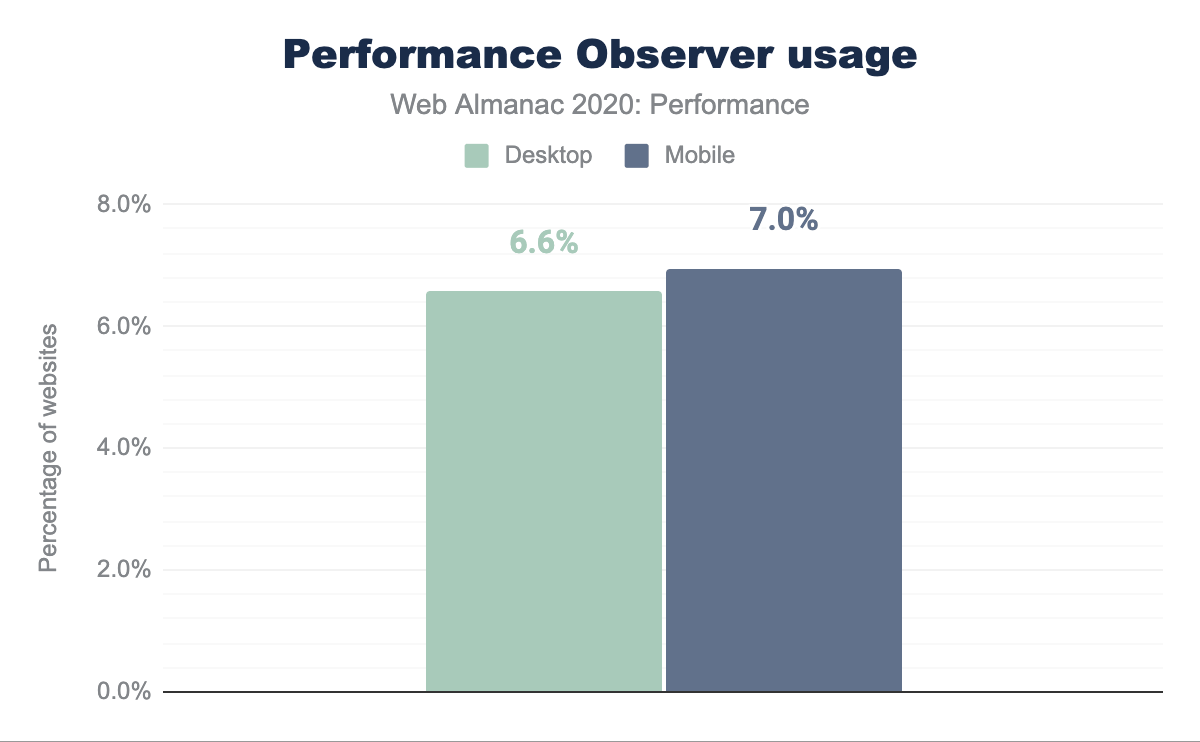
Le graphique ci-dessus montre que PerformanceObserver est utilisé par 6 à 7 % des sites suivis, selon le type d’appareil. Ces sites utiliseront les API de bas niveau pour créer des mesures personnalisées et l’API PerformanceObserver pour les rassembler, puis les utiliseront éventuellement avec d’autres outils de rapport de performance. De tels taux d’adoption pourraient indiquer la tendance à s’appuyer sur des mesures prédéfinies (par exemple, provenant de Lighthouse), mais sont également impressionnants pour une API relativement spécialisée.
Conclusion
L’UX n’est pas seulement un continuum, mais dépend également d’une grande variété de facteurs. Pour tenter de comprendre l’état de la performance sans exclure les expériences inférieures et défavorisées, nous devons l’aborder de manière intersectionnelle. Chaque visite de site web raconte une histoire. Notre statut socio-économique personnel et celui de notre pays dictent le type de matériel et de fournisseur d’accès Internet que nous pouvons nous permettre. Notre lieu de résidence a une incidence sur la latence (nous, Australiens, ressentons régulièrement cette douleur), et l’économie dicte la couverture disponible du réseau cellulaire. Quels sont les sites web que nous visitons ? Pourquoi les visitons-nous ? Le contexte est essentiel non seulement pour analyser les données, mais aussi pour développer l’empathie et l’attention nécessaires à l’élaboration d’expériences accessibles et rapides pour tous.
En surface, nous avons vu des signaux optimistes concernant les nouvelles mesures de performance que sont les Signaux Web Essentiels. Au moins la moitié des expériences sont bonnes sur les ordinateurs de bureau et les appareils mobiles, si nous ne nous focalisons pas à des expériences systématiquement mauvaises sur les réseaux plus lents pour le Largest Contentful Paint. Bien que les nouvelles mesures puissent suggérer que les problèmes de performance soient en train d’être résolus, l’absence d’améliorations significatives du First Contentful Paint et du Time to First Byte donne à réfléchir. Ce sont les mêmes types de réseaux qui sont les plus désavantagés que pour le Largest Contentful Paint, ainsi que les connexions rapides et les ordinateurs de bureau. Le score de performance montre également une baisse de la vitesse (ou peut-être une représentation plus précise que ce que nous avons mesuré dans le passé).
Ce que les données nous montrent, c’est que nous devons continuer à investir dans l’amélioration des performances dans certains cas (tels qu’une connectivité plus lente) que nous ne connaissons souvent pas en raison de multiples aspects de notre privilège (pays à revenu moyen ou élevé, salaires élevés et nouveaux appareils performants). Il souligne également qu’il reste encore beaucoup à faire dans les domaines de l’accélération des premiers rendus (LCP et FCP) et de la livraison des ressources (TTFB). Souvent, les performances sont considérées comme une question intrinsèquement front-end, alors que de nombreuses améliorations importantes peuvent être réalisées en aval et grâce à des choix d’infrastructures appropriés. Là encore, l’expérience d’utilisation est un continuum qui dépend de divers facteurs, et nous devons la traiter de manière globale.
Les nouvelles mesures apportent de nouvelles manières d’analyser l’expérience d’utilisation, mais nous ne devons pas oublier les signaux existants. Concentrons-nous sur les domaines qui ont le plus besoin d’être améliorés et qui entraîneront des changements positifs dans l’expérience des personnes les plus mal desservies. Un internet rapide et accessible est un droit humain.

{kind=link}