SEO
Introducción
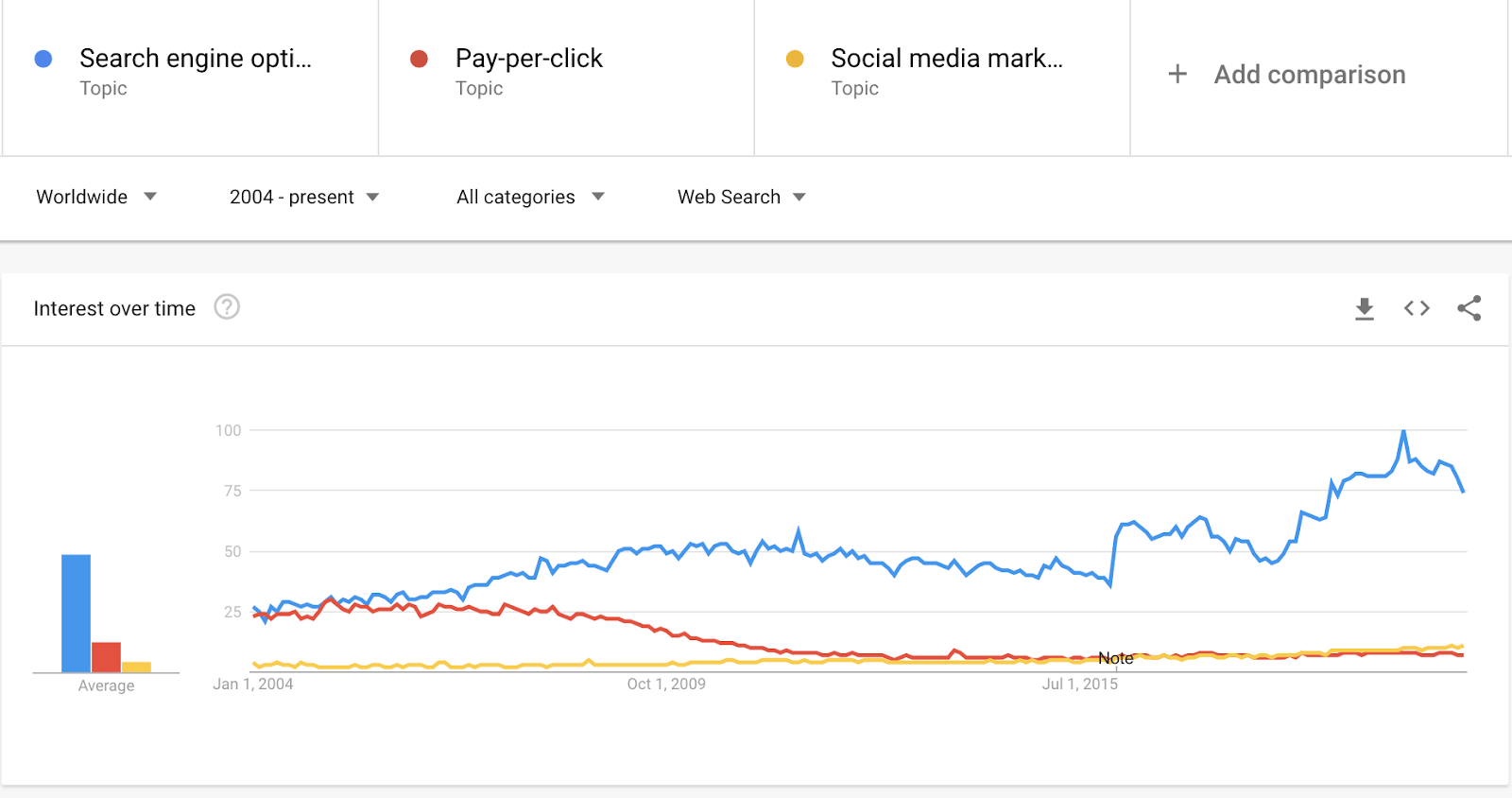
La optimización para motores de búsqueda (SEO por sus siglas en inglés) es la práctica de optimizar la configuración técnica, relevancia de contenido y popularidad de enlaces de los sitios web para hacer su información más fácil de encontrar y más relevante para satisfacer las necesidades de búsqueda de los usuarios. Como consecuencia, los sitios web mejoran su visibilidad en los resultados de los motores de búsqueda para búsquedas relevantes relacionadas a su contenido y negocio, aumentando su tráfico, conversiones y ganancias.
A pesar de su compleja naturaleza multidisciplinaria, en los últimos años, el SEO ha evolucionado a convertirse en una de las estrategias y canales de marketing digital más populares.
El objetivo del capítulo SEO del Web Almanac es identificar y evaluar los elementos y configuraciones principales que intervienen en la optimización para la búsqueda orgánica de un sitio web. Al identificar estos elementos, esperamos que los sitios web puedan aprovechar nuestros descubrimientos para mejorar su habilidad de ser rastreados, indexados y posicionados por los motores de búsqueda. En este capítulo, ofrecemos una visión general de su estado en 2020 y un resumen de lo que ha cambiado desde 2019.
Es importante aclarar que este capítulo se basa en un análisis de Lighthouse en sitios web móviles, el Reporte de Chrome UX en dispositivos móviles y de escritorio, así como elementos de HTML puro y renderizado del HTTP Archive en dispositivos móviles y de escritorio. En el caso del HTTP Archive y Lighthouse, está limitado a datos identificados de las páginas principales de los sitios web, y no rastreos completos del sitio web. Hemos considerado esto al momento de hacer las evaluaciones. Tener en cuenta esta distinción es importante al momento de sacar conclusiones de nuestros resultados. Puedes aprender más sobre esto en nuestra página de Metodología.
Repasemos los principales resultados de la optimización de búsqueda orgánica de este año.
Fundamentos
Esta sección presenta los hallazgos relacionados a la optimización, de las configuraciones web y elementos que constituyen la base para que los motores de búsqueda rastreen, indexen, y posicionen correctamente a los sitios web para ofrecer a los usuarios los mejores resultados para sus búsquedas.
Rastreabilidad e Indexabilidad
Los motores de búsqueda usan rastreadores web (también llamados arañas) para descubrir contenido nuevo o actualizado de sitios web, navegando la web siguendo los enlaces entre las páginas. El rastreo es el proceso de buscar contenido nuevo o actualizado (ya sean páginas web, imágenes, videos, etc.).
Los rastreadores de búsqueda descubren el contenido al seguir los enlaces entre URLs, así como el uso de recursos adicionales que los dueños de sitios web pueden proveer, como la generación de XML sitemaps, que son listas de URLs que el dueño de un sitio web quiere que sean indexadas por los motores de búsqueda, o a través de peticiones de rastreo directas desde herramientas de los buscadores como Google Search Console.
Una vez que los motores de búsqueda acceden al contenido que necesitan para renderizar—similar a lo que hacen los navegadores web—y lo indexan. Los motores de búsqueda después analizarán y clasificarán la información identificada, tratando de entenderla como lo hacen los usuarios, para finalmente guardarla en su índice, o base de datos.
Cuando los usuarios introducen una búsqueda, los motores de búsqueda buscan en su índice para encontrar y mostrar el mejor contenido en las páginas de resultados para responder a su búsqueda, usando una variedad de factores para determinar qué páginas se muestran antes que otras.
Para los sitios web que buscan optimizar su visibilidad en los resultados de búsqueda, es importante seguir ciertas buenas prácticas de rastreabilidad e indexabilidad: configurar correctamente el robots.txt, las meta etiquetas robots, los HTTP headers X-Robots-Tag, y etiquetas canonical, entre otros. Estas buenas practicas ayudan a los buscadores a acceder más fácilmente al contenido web e indexarlos más adecuadamente. En las siguentes secciones se ofrece un análisis exhaustivo de estas configuraciones.
robots.txt
Ubicado en la raíz de un sitio web, el archivo robots.txt es una herramienta efectiva para controlar con qué páginas puede interactuar un rastreador de búsqueda, qué tan rápido rastrearlas, y qué hacer con el contenido encontrado.
Google formalmente propuso hacer del robots.txt un estándar oficial de internet en 2019. El borrador de Junio 2020 incluye documentación clara sobre los requerimientos técnicos del archivo robots.txt. Esto ha resultado en más información detallada sobre cómo deben responder los rastreadores de búsqueda al contenido no estándar.
El archivo robots.txt debe ser de texto plano, codificado en UTF-8 y responder a las peticiones con un código de estado HTTP 200. Un mal archivo robots.txt, una respuesta 4XX (error del cliente), o más de cinco redirecciones, son interpretadas por los rastreadores de búsqueda como una autorización completa, lo que significa que todo el contenido puede ser rastreado. Una respuesta 5XX (error de servidor) se entiende como una restricción completa, lo que significa que no se rastreará nada de contenido. Si no se puede acceder al archivo robots.txt por más de 30 días, Google usará la última versión disponible en caché del archivo, tal como se describe en sus especificaciones.
En general, 80.46% de las páginas móviles tuvieron una respuesta 2XX en su archivo robots.txt. De estas, 25.09% no fueron reconocidos como válidos. Esto ha mejorado ligeramente a lo largo del 2019, cuando se encontró que 27.84% de los sitios web móviles tenían un robots.txt válido.
Lighthouse, la fuente de datos para comprobar la validez del robots.txt, introdujo una auditoría derobots.txt como parte de la actualización de la v6. Esta inclusión destaca que una petición exitosa no significa que dicho archivo sea capaz de proporcionar las directivas necesarias a los rastreadores web.
| Código de respuesta | Móvil | Escritorio |
|---|---|---|
| 2XX | 80.46% | 79.59% |
| 3XX | 0.01% | 0.01% |
| 4XX | 17.67% | 18.64% |
| 5XX | 0.15% | 0.12% |
| 6XX | 0.00% | 0.00% |
| 7XX | 0.15% | 0.12% |
robots.txt.
Además de un comportamiento similar en los códigos de estado, el uso de la declaración Disallow fue consistente entre las versiones móvil y escritorio de los archivos robots.txt.
La declaración de User-agent más frecuente fue la más genérica y popular, User-agent: *, apareciendo en 74.40% de las peticiones móviles, y en 73.16% de las peticiones de escritorio del archivo robots.txt. La segunda declaración más frecuente fue adsbot-google, apareciendo en 5.63% de las peticiones móviles, y en 5.68% de las peticiones de escritorio del robots.txt. El Google AdsBot no tiene en cuenta la declaración genérica y debe ser especificado por su nombre, pues el bot revisa la calidad de los anuncios de páginas web y aplicaciones en diferentes dispositivos.
Las directivas más usadas se centran en los motores de búsqueda y sus contrapartes de marketing de pago. Las herramientas SEO Ahrefs y Majestic estaban en el top cinco de declaraciones Disallow para ambos dispositivos.
% de robots.txt |
||
|---|---|---|
User-agent |
Móvil | Escritorio |
* |
74.40% | 73.16% |
| adsbot-google | 5.63% | 5.68% |
| mediapartners-google | 5.55% | 3.83% |
| mj12bot | 5.49% | 5.30% |
| ahrefsbot | 4.80% | 4.66% |
User-agent del robots.txt.
Al analizar el uso de la directiva Disallow en el archivo robots.txt usando datos provenientes de Lighthouse de más de 6 millones de sitios, se encontró que 97.84% de ellos eran totalmente rastreables, y solo un 1.05% usaban la directiva Disallow.
Un análisis sobre el uso conjunto de la directiva Disallow en el robots.txt y directivas de indexabilidad meta robots también fue realizado, se encontró que 1.02% de los sitios usan la directiva Disallow en páginas indexables con una etiqueta meta robots index, y únicamente 0.03% de sitios usan la directiva Disallow en el archivo robots.txt en páginas no indexables debido a la etiqueta meta robots noindex.
El mayor uso de la declaración Disallow en páginas indexables que en páginas no indexables es notable, la documentación de Google indica que dueños de sitios web no deberían utilizar el robots.txt como una medida para ocultar páginas web de la búsqueda de Google, ya que el enlazado interno con textos descriptivos puede resultar en que dichas páginas sean indexadas sin necesidad de que un rastreador visite la página. En su lugar, los dueños de sitios web deben usar otros métodos como la etiqueta meta robots con valor noindex.
Meta robots
La meta etiqueta robots y el X-Robots-Tag HTTP header son una extensión del propuesto Protocolo de Exclusión Robots (REP), que permite que las directivas sean configuradas a un nivel más granular. El soporte de las directivas varía según el motor de búsqueda ya que el REP todavía no es un estándar oficial de internet.
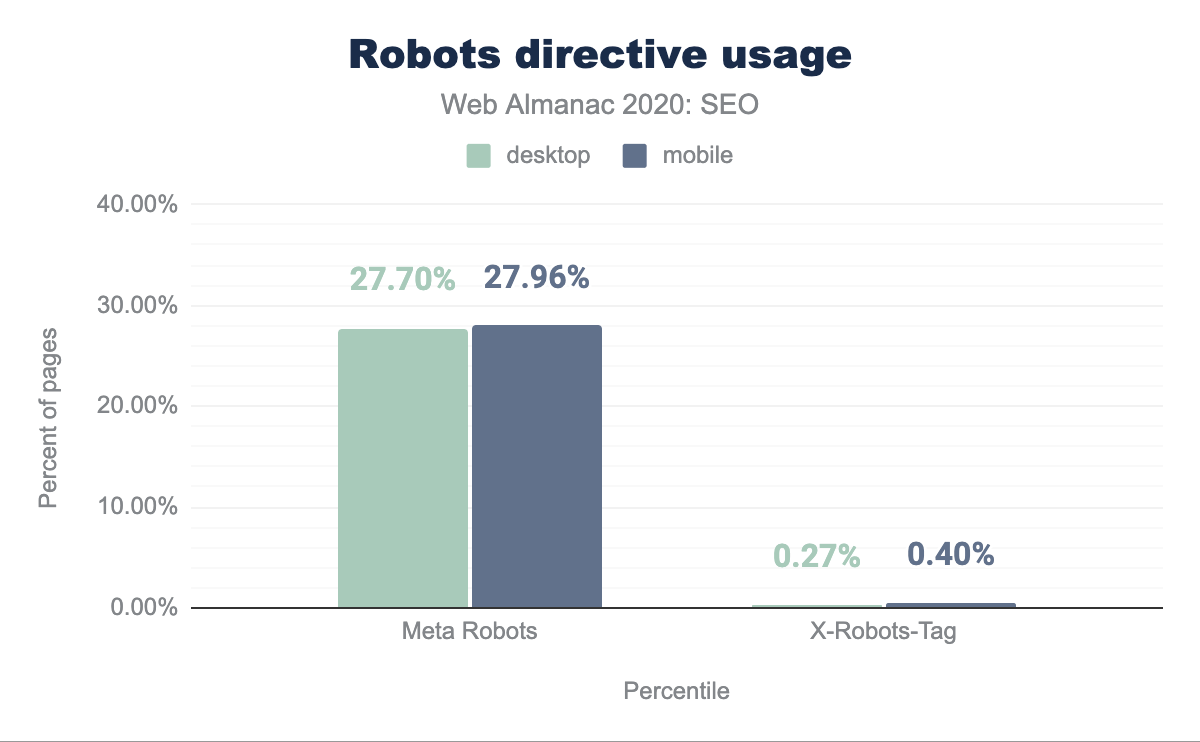
Las meta etiquetas fueron el método dominante de ejecución granular con un 27.70% de las páginas de escritorio y 27.96% de páginas móviles que usan las etiquetas. Las directivas X-Robots-Tag se encontraron en un 0.27% y 0.40% en páginas de escritorio y móviles respectivamente.
X-Robots-Tag.
Al analizar el uso de la etiqueta meta robots en pruebas de Lighthouse, se encontró que un 0.47% de las páginas rastreables eran no indexables. Un 0.44% de estas páginas usaba una etiqueta meta robots con valor noindex y no bloqueaban el rastreo de la página en el archivo robots.txt.
La combinación de la declaración Disallow en el archivo robots.txt y el valor noindex en la etiqueta meta robots fue encontrado solo en 0.03% de las páginas. Aunque este método ofrece una redundancia de cinturón y tirantes, una página no debe ser bloqueada por el archivo robots.txt para que la etiqueta meta robots noindex sea efectiva.
Curiosamente, el renderizado cambió la etiqueta meta robots de un 0.16% de las páginas. Aunque no hay ningún problema inherente con usar JavaScript para añadir una etiqueta meta robots a una página o cambiar su valor, los SEOs deben ser juiciosos en la ejecución. Si una página se carga con un valor noindex en la etiqueta meta robots antes del renderizado, los motores de búsqueda no ejecutarán el JavaScript que cambia el valor de la etiqueta, ni indexarán la página.
Canonicalización
Las etiquetas canonical, tal y como lo describe Google, son usadas para especificar a los motores de búsqueda cuál es la versión de la URL canónica preferida para indexar y posicionar para una página-aquella que es considerada más representativa- cuando hay muchas URLs mostrando contenido similar o el mismo contenido. Es importante tener en cuenta que:
- La configuración de la etiqueta canonical es usada junto con otras señales para elegir la URL canónica de una página; no es la única.
- Aunque algunas veces se usan etiquetas canonical auto-referenciadas, no son un requisito.
En el capítulo del año anterior, se identificó que 48.34% de las páginas móviles usaban una etiqueta canonical. Este año el número de páginas móviles que usan una etiqueta canonical ha crecido a 53.61%.
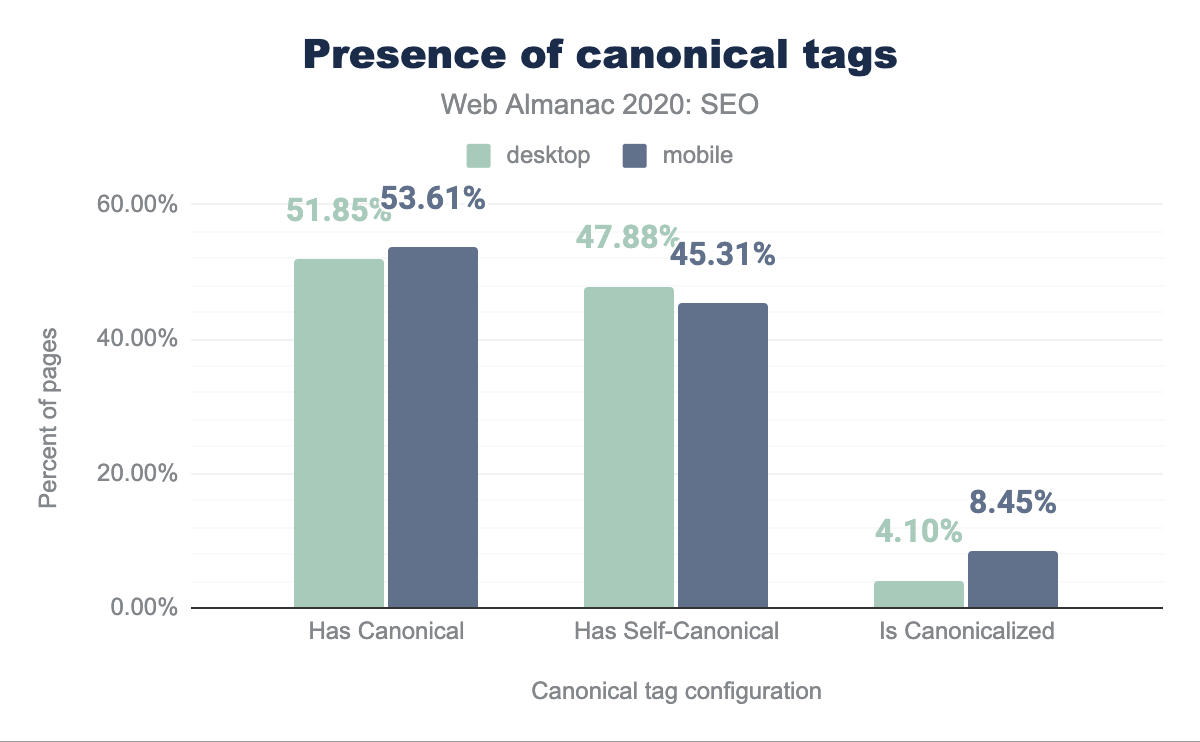
Al analizar la configuración de la etiqueta canonical en páginas móviles de este año, se encontró que 45.31% de ellas son auto-referenciadas y 8.45% apuntan a diferentes URLs como su versión canónica.
Por otro lado, se encontró que 51.85% de las páginas de escritorio usaban una etiqueta canónica este año, con un 47.88% siendo auto-referenciadas y 4.10% apuntando a una URL diferente.
No solo las páginas móviles incluyen más etiquetas canónicas que las de escritorio (53.61% frente a 51.85%), hay un número relativamente mayor de páginas de inicio móviles canonicalizando a otras URLs que sus contrapartes de escritorio (8.45% frente a 4.10%). Esto puede ser explicado por el uso de páginas móviles independientes (o separadas) de algunos sitios que deben canonicalizar a sus URLs alternas de escritorio.
Las URLs canónicas pueden ser especificadas a través de diferentes métodos: al usar el enlace canónica en los encabezados HTTP o en el head del HTML de la página, o al enviarlas en un XML sitemap. Al analizar cual es el método de implementación de etiquetas canónicas preferido, se encontró que solo 1.03% de las páginas de escritorio y 0.88% de las móviles dependían de los encabezados HTTP para su implementación, lo que demuestra que las etiquetas canónicas se implementan predominantemente por el head del HTML de una página.
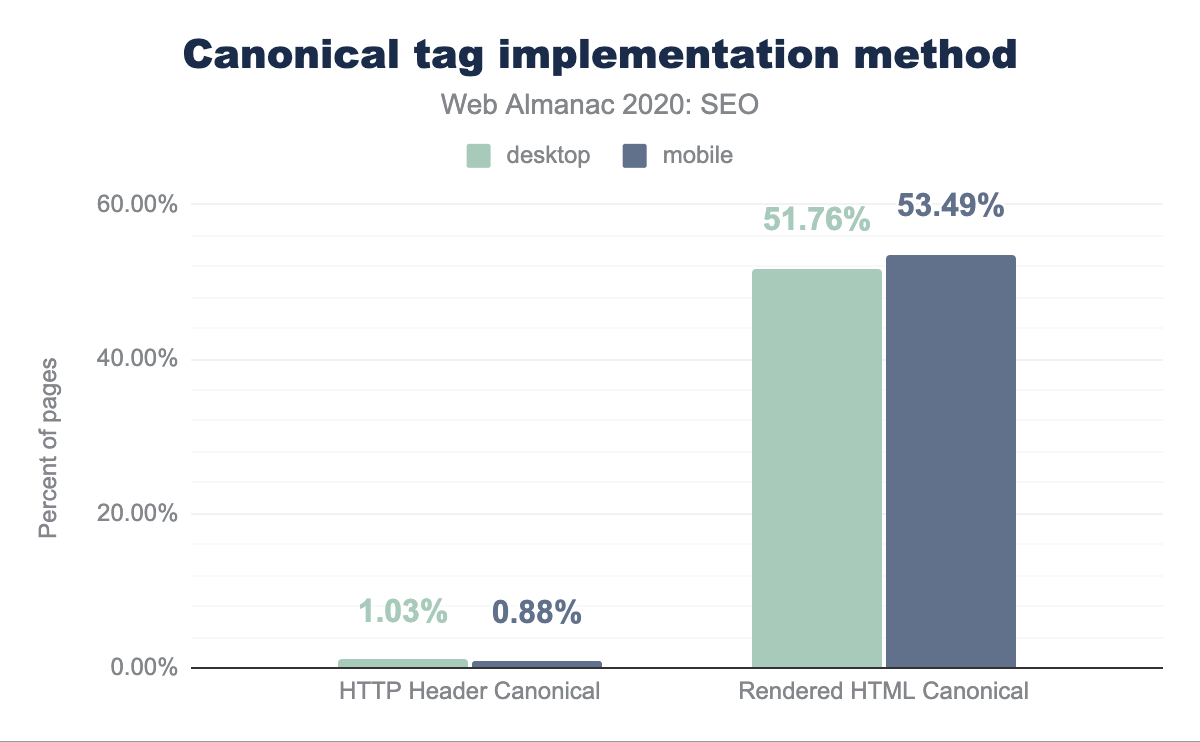
head del HTML.
Al analizar la implementación de las etiquetas canonical en el HTML puro y aquellas que dependen del renderizado de JavaScript del lado del cliente, identificamos que 0.68% de las páginas móviles y 0.54% de las páginas de escritorio incluían una etiqueta canonical en el HTML renderizado, pero no en el HTML puro. Esto significa que solamente hay un número pequeño de páginas que dependen de JavaScript para implementar las etiquetas canonical.
Por otro lado, en 0.93% de las páginas móviles y 0.76% de las páginas de escritorio, observamos etiquetas canonical implementadas tanto en el HTML puro como en el HTML renderizado con un conflicto existente entre las URLs especificadas en el HTML puro y renderizado. Esto puede generar problemas de indexabilidad ya que se envían señales mixtas a los motores de búsqueda sobre cuál es la URL canónica de una página.
Un conflicto similar se puede encontrar en diferentes métodos de implementación, con un 0.15% de las páginas móviles y 0.17% de las páginas de escritorio que mostraban conflictos entre las etiquetas canonical implementadas en los encabezados HTTP y en el head del HTML.
Contenido
El propósito principal de los buscadores y la optimización para motores de búsqueda es dar visibilidad al contenido que los usuarios necesitan. Los motores de búsqueda extraen características de las páginas para determinar de qué trata el contenido. En ese sentido, ambos son simbióticos. Las características extraídas se alinean con señales que indican la relevancia e informan su posicionamiento.
Para entender lo que los motores de búsqueda son capaces de extraer exitosamente, hemos desglosado los componentes del contenido y examinado la tasa de incidencia de dichas características entre un contexto móvil y de escritorio. También hemos revisado la disparidad entre el contenido móvil y de escritorio. La disparidad de contenido entre ambos es especialmente valiosa porque Google se ha migrado a un mobile-first indexing (MFI) para todos sus sitios, y para Marzo del 2021, será una migración a un mobile-only index donde el contenido que no aparece en un contexto móvil no será evaluado para su posicionamiento.
Contenido de texto renderizado vs. no renderizado
El uso de tecnologías JavaScript como Single Page Application (SPA) ha incrementado con el crecimiento de la web. Este patrón de diseño introduce ciertas dificultades para los rastreadores de búsqueda, pues tanto su ejecución de transformaciones de JavaScript durante el tiempo de ejecución y las interacciones de usuario con la página después de ser cargada, pueden ocasionar que contenido adicional sea visible o renderizado.
Los motores de búsqueda se encuentran con páginas durante su actividad de rastreo, pero pueden o no escoger una implementación de un segundo paso de renderización para la página. Como resultado, pueden existir disparidades entre el contenido que un usuario ve y el contenido que los motores de búsqueda indexan y consideran para el posicionamiento.
Evaluamos el conteo de palabras como una heurística de esa disparidad.
| Valores | Escritorio | Móvil | Diferencia |
|---|---|---|---|
| Raw | 360 | 312 | -13.33% |
| Rendered | 402 | 348 | -13.43% |
| Diferencia | 11.67% | 11.54% |
Este año, el promedio de las páginas de escritorio fue de 402 palabras y el promedio de las páginas móviles fue de 348 palabras. Mientras que el año pasado, el promedio en páginas de escritorio fue de 346 palabras, y el promedio en páginas móviles fue ligeramente menor con 306 palabras. Esto representa un crecimiento del 16.2% y 13.7% respectivamente.
Encontramos que, en promedio, los sitios de escritorio tienen 11.67% más palabras cuando son renderizadas que durante el rastreo inicial del HTML puro. También encontramos que, en promedio, los sitios móviles muestran 13.33% menos contenido de texto que sus contrapartes de escritorio. En promedio, los sitios móviles muestran 11.54% más palabras cuando son renderizadas que el HTML puro de su contraparte.
En nuestro conjunto de muestras, hay disparidades en la combinación de móvil/escritorio y renderizado/no renderizado. Esto sugiere que, aunque los motores de búsqueda están continuamente mejorando en esta área, la gran mayoría de los sitios en la web están perdiendo oportunidades de mejorar su visibilidad en la búsqueda orgánica a través de un mayor enfoque en asegurar que su contenido está disponible e indexable. Esto también es preocupante porque la mayor parte de herramientas SEO disponibles no rastrean en la combinación de contextos mencionada y automáticamente identifican esto como un problema.
Encabezados
Los elementos de encabezados (H1-H6) actúan como un mecanismo para indicar visualmente la estructura del contenido de una página. Aunque estos elementos HTML no son considerados en el posicionamiento, siguen siendo una forma valiosa de estructurar páginas y señalar otros elementos de las páginas de resultados (SERPs) como featured snippets u otros métodos de extracción que se alinean con el nuevo Google Pasages.
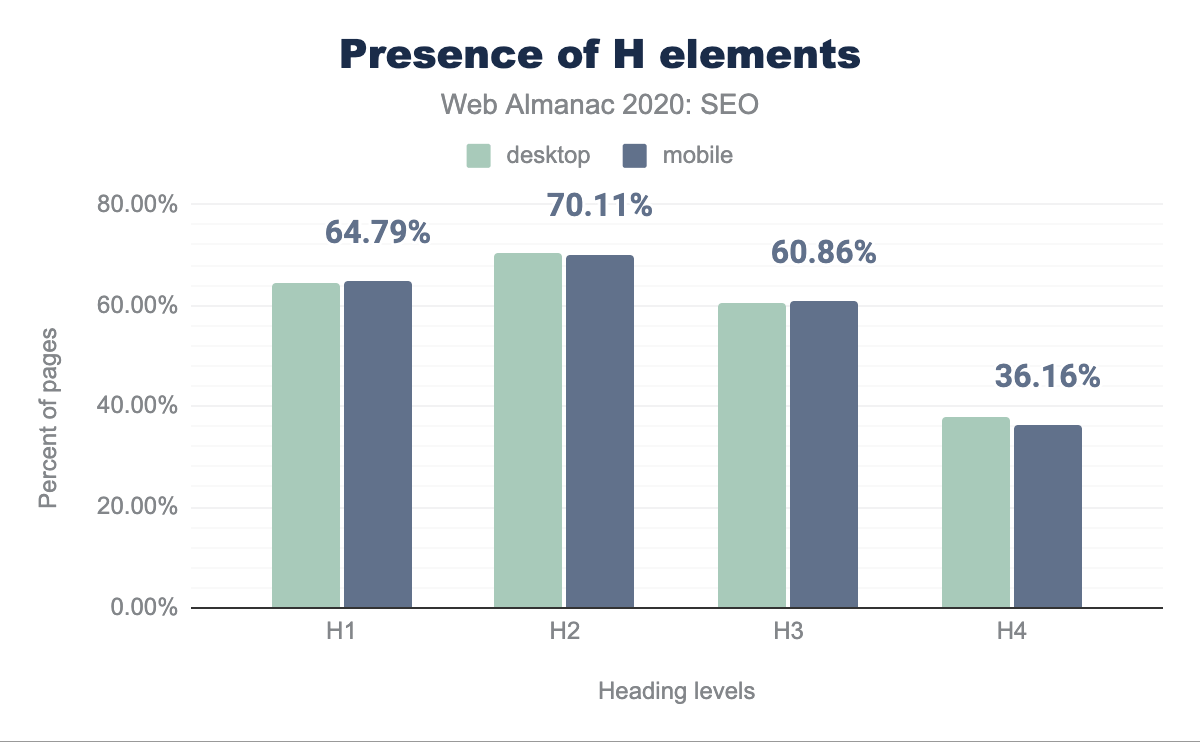
Más del 60% de las páginas cuentan con encabezados H1 (incluyendo los vacíos) tanto en un contexto móvil como de escritorio.
Estos números rondan alrededor de +60% desde el H2 y H3. La tasa de incidencia de los elementos H4 es menor que 4%, lo que sugiere que el nivel de especificidad no es requerido para la mayoría de las páginas web o los desarrolladores aplican estilos diferentes a otros elementos de encabezados para soportar visualmente la estructura del contenido.
La prevalencia de más elementos H2 que H1 sugiere que menos páginas están usando múltiples H1.
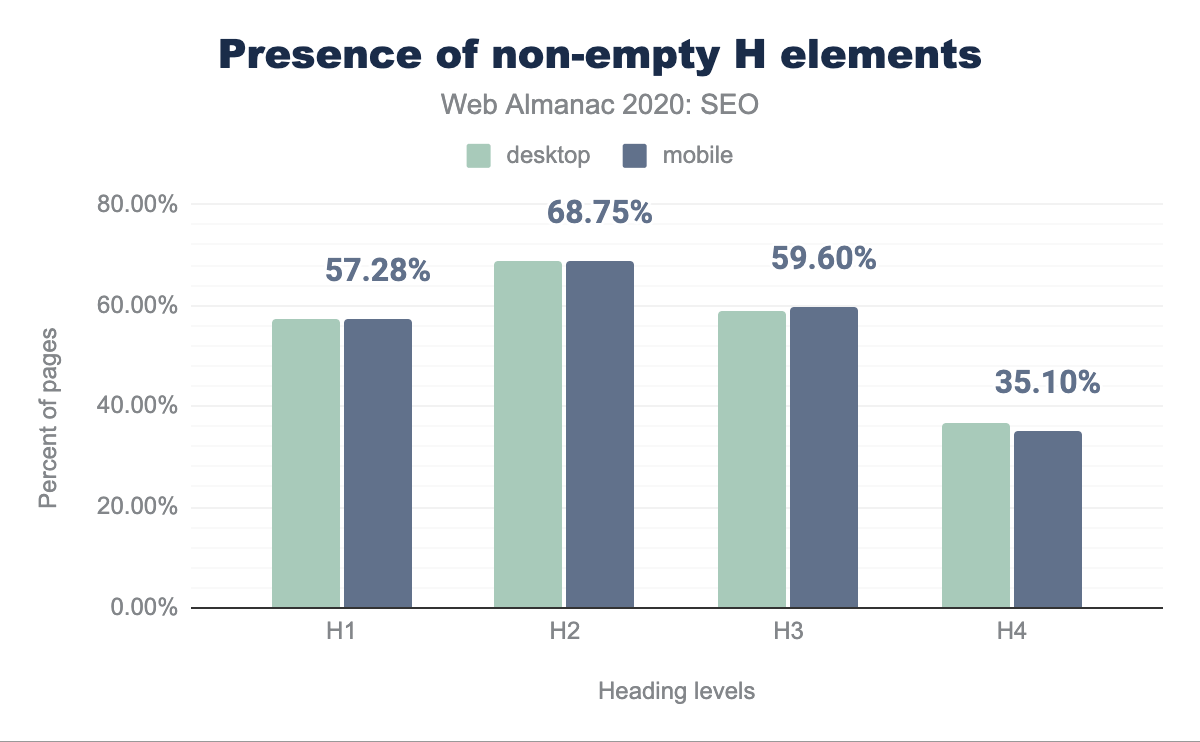
Al revisar la adopción de los elementos de encabezado no vacíos, encontramos que 7.55% de H1, 1.4% de H2, 1.5% de H3, y 1.1% de los elementos H4 no incluyen texto. Una posible explicación de estos bajos resultados es que esas porciones son usadas para dar estilos a la página, o son resultados de errores de codificación.
Puedes aprender más sobre el uso de encabezados en el capítulo de Marcado Web, incluyendo el mal uso de elementos no estándar H7 y H8.
Datos estructurados
A lo largo de la última década, los motores de búsqueda, particularmente Google, han seguido avanzando para convertirse en la capa de presentación de la web. Estos avances son parcialmente impulsados por su mejorada habilidad de extraer información de contenido no estructurado (e.g., passage indexing) y la adopción de marcado semántico en forma de datos estructurados. Los motores de búsqueda han alentado a creadores de contenido y desarrolladores a implementar datos estructurados para dar más visibilidad a su contenido dentro de los componentes de los resultados de búsqueda.
En un cambio de “texto a cosas”, los motores de búsqueda han concordado en un amplio vocabulario de objetos para marcar una variedad de personas, lugares, y cosas dentro del contenido web. Sin embargo, solo un subconjunto de ese vocabulario activa la inclusión en los componentes de los resultados de búsqueda. Google especifica aquellos que son soportados y cómo son mostrados en su galería de búsqueda, y provee una herramienta para validar su soporte e implementación.
A medida que los motores de búsqueda evolucionan para incluir más de estos elementos en los resultados de búsqueda, las tasas de incidencia de los diferentes vocabularios cambian en la web.
Como parte de nuestra examinación, miramos las tasas de incidencia de los diferentes tipos de marcado estructurado. Los vocabularios disponibles incluyen RDFa, y schema.org, que están disponibles tanto en micro formatos y JSON-LD. Google recientemente ha retirado el soporte para data-vocabulary, que era principalmente usado para implementar breadcrumbs o migas de pan.
JSON-LD es generalmente considerado como el más portátil y fácil de manejar en su implementación y eso lo ha convertido en el formato preferido. Como resultado, vemos que JSON-LD aparece en 29.78% de las páginas móviles y en 30.60% de las páginas de escritorio.
| Formato | Móvil | Escritorio |
|---|---|---|
| JSON-LD | 29.78% | 30.60% |
| Micro datos | 19.55% | 17.94% |
| RDFa | 1.42% | 1.63% |
| Micro formatos | 0.10% | 0.10% |
Encontramos que la disparidad entre móvil y escritorio continua con este tipo de datos. Los micro datos aparecieron en 19.55% de las páginas móviles y 17.94% de las páginas de escritorio. RDFa apareció en 1.42% de las páginas móviles y 1.63% de las páginas de escritorio.
Datos estructurados renderizados vs. no renderizados
Encontramos que 38.61% de las páginas de escritorio y 39.26% de las páginas móviles incluyen datos estructurados en JSON-LD o micro formatos en el HTML puro, mientras que 40.97% de las páginas móviles incluyen datos estructurados en el DOM renderizado.
Al revisar esto en más detalle, encontramos que 1.49% de las páginas de escritorio y 1.77% de las páginas móviles solo incluían esté tipo de datos estructurados en el DOM renderizado debido a transformaciones con JavaScript, dependiendo de la capacidad de ejecución de JavaScript de los motores de búsqueda.
Por último, encontramos que 4.46% de las páginas de escritorio y 4.62% de las páginas móviles incluyen datos estructurados que aparecen en el HTML puro y es posteriormente cambiado con transformaciones de JavaScript en el DOM renderizado. Dependiendo del tipo de cambios aplicados a la configuración de datos estructurados, esto puede generar señales mixtas para los motores de búsqueda cuando las renderizen.
Objetos de datos estructurados más frecuentes
Tal como el año pasado, los objetos de datos estructurados más frecuentes siguen siendo WebSite, SearchAction, WebPage, Organization, e ImageObject, y su uso sigue creciendo:
WebSiteha crecido 9.37% en escritorio y 10.5% en móvilSearchActionha crecido 7.64% tanto en escritorio como en móvilWebPageha crecido 6.83% en escritorio y 7.09% en móvilOrganizationha crecido 4.75% en escritorio y 4.98% en móvilImageObjectha crecido 6.39% en escritorio y 6.13% en móvil
Cabe señalar que WebSite, SearchAction y Organization son mayormente asociados a páginas de inicio, por lo que esto resalta el parcialismo del conjunto de datos y no refleja el conjunto de datos estructurados implementados en la web.
En contraste, a pesar de que las reseñas no suponen una asociación directa con las páginas de inicio, los datos indican que AggregateRating es usado en un 23.9% en móvil y 23.7% en escritorio.
También es interesante ver el crecimiento de VideoObject para videos. Si bien los videos de YouTube dominan los resultados de video en la búsqueda de Google, el uso de VideoObject creció 30.11% en escritorio y 27.7% en móvil.
El crecimiento en el uso de estos objetos es una señal general de un aumento en la adopción de datos estructurado. También hay un indicio de que lo que a Google le da visibilidad dentro de las características de búsqueda, aumenta las tasa de incidencia de objetos menos utilizados. Google anunció los objetos FAQPage, HowTo, y QAPage como oportunidades de visibilidad en 2019 y muestran un importante crecimiento anual:
- El uso del marcado
FAQPagecreció 3,261% en escritorio y 3,000% en móvil. - El uso del marcado
HowTocreció 605% en escritorio y 623% en móvil. - El uso del marcado
QAPagecreció 166.7% en escritorio y 192.1% en móvil.
La adopción de los datos estructurados es una ventaja para la web ya que la extracción de datos es valiosa para una gran cantidad de casos de uso. Esperamos que esto siga creciendo a medida que los buscadores expanden su uso y empiecen a impulsar aplicaciones más allá de la búsqueda web.
Metadatos
Los metadatos son una oportunidad de describir y explicar el valor del contenido del otro lado del clic. Mientras que los títulos de las páginas se cree que tienen un peso directo en el posicionamiento orgánico, las meta descripciones no lo son. Ambos elementos pueden fomentar o desanimar al usuario a hacer o no clic basado en su contenido.
Examinamos estas características para ver cómo las páginas se alinean cuantitativamente con las buenas prácticas para atraer tráfico de la búsqueda orgánica.
Titles
El título de una página es mostrado como el texto del enlace en los resultados de búsqueda y es generalmente considerado uno de los elementos de la página más valiosos que impactan la habilidad de posicionar de una página.
Al analizar el uso de la etiqueta title, encontramos que 99% de las páginas móviles y de escritorio tienen una. Esto representa una ligera mejora respecto al año pasado, donde 97% de las páginas móviles tenían una etiqueta title.
En promedio, el título de una página es de 6 palabras de largo. No hay una diferencia en la cantidad de palabras entre los contextos móviles y desktop en nuestro conjunto de datos. Esto sugiere que el título de la página es un elemento que no se modifica entre los diferentes tipos de plantillas de páginas.
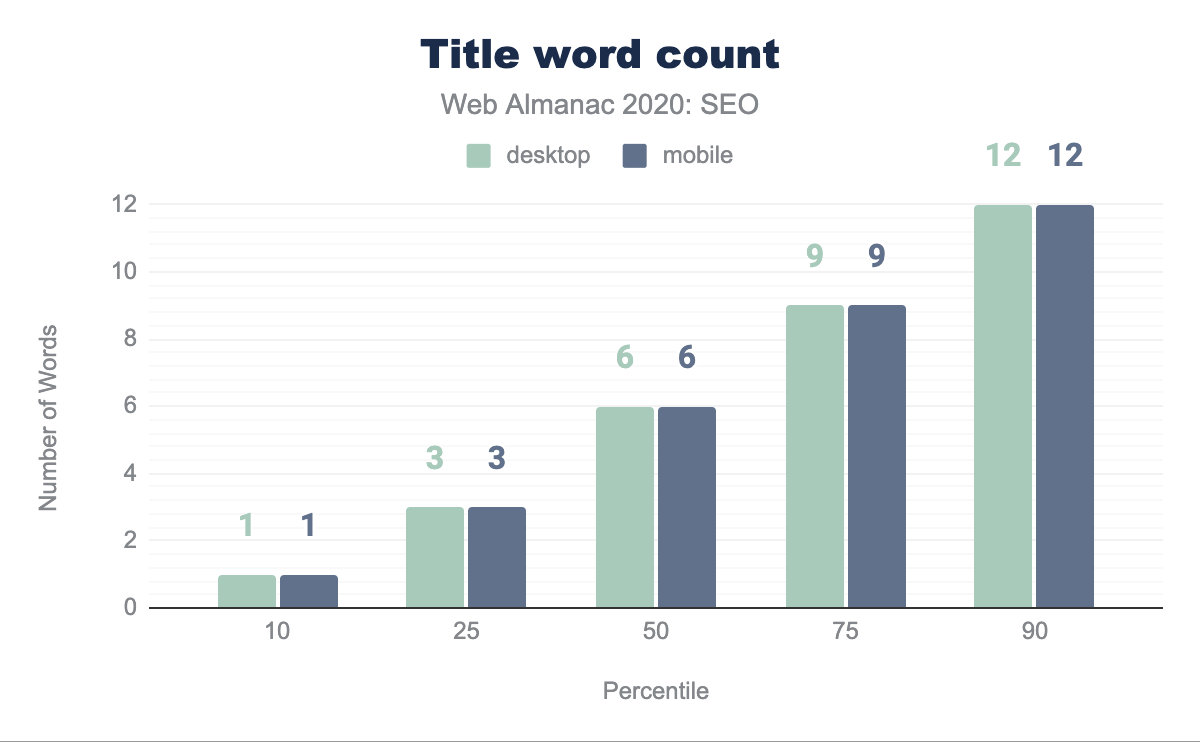
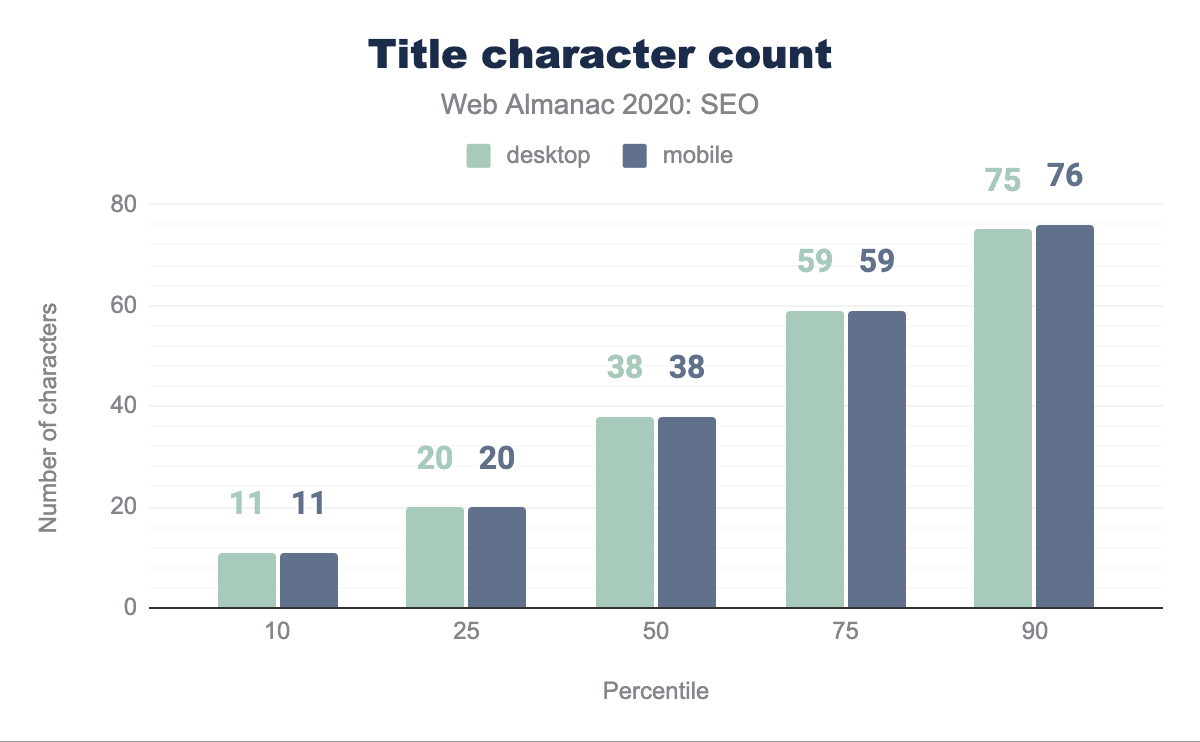
En promedio, el número de caracteres del título de página es de 38 tanto en móvil como en escritorio. Curiosamente, esto es un aumento de 20 caracteres en escritorio y 21 en móvil en comparación con el análisis del año anterior. La disparidad entre ambos contextos ha desaparecido año con año excepto con el percentil 90 donde hay un carácter de diferencia.
Meta descripciones
La meta descripción actúa como el slogan publicitario de una página web. Aunque un estudio reciente sugiere que está etiqueta es ignorada y rescrita por Google un 70% del tiempo, es un elemento que se prepara con el objetivo de incitar al usuario a hacer clic.
Al analizar el uso de las meta descripciones, encontramos que 68.62% de las páginas de escritorio y 68.22% de las páginas móviles tienen una. Aunque esto parezca sorpresivamente bajo, es una ligera mejora respecto al año pasado, donde solo un 64.02% de las páginas móviles tenían una meta descripción.
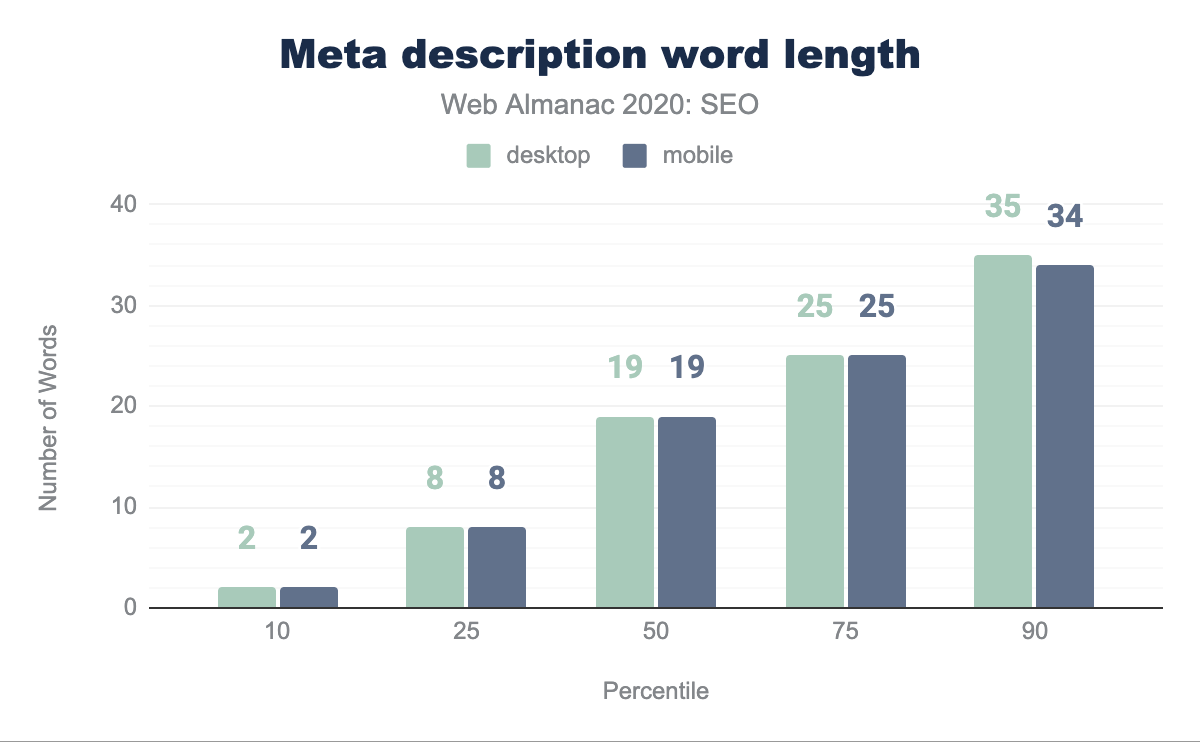
La longitud promedio de la meta descripción es de 19 palabras. La única disparidad en el número de palabras sucede en el percentil 90 donde el contenido en desktop tiene una palabra más que en móvil.
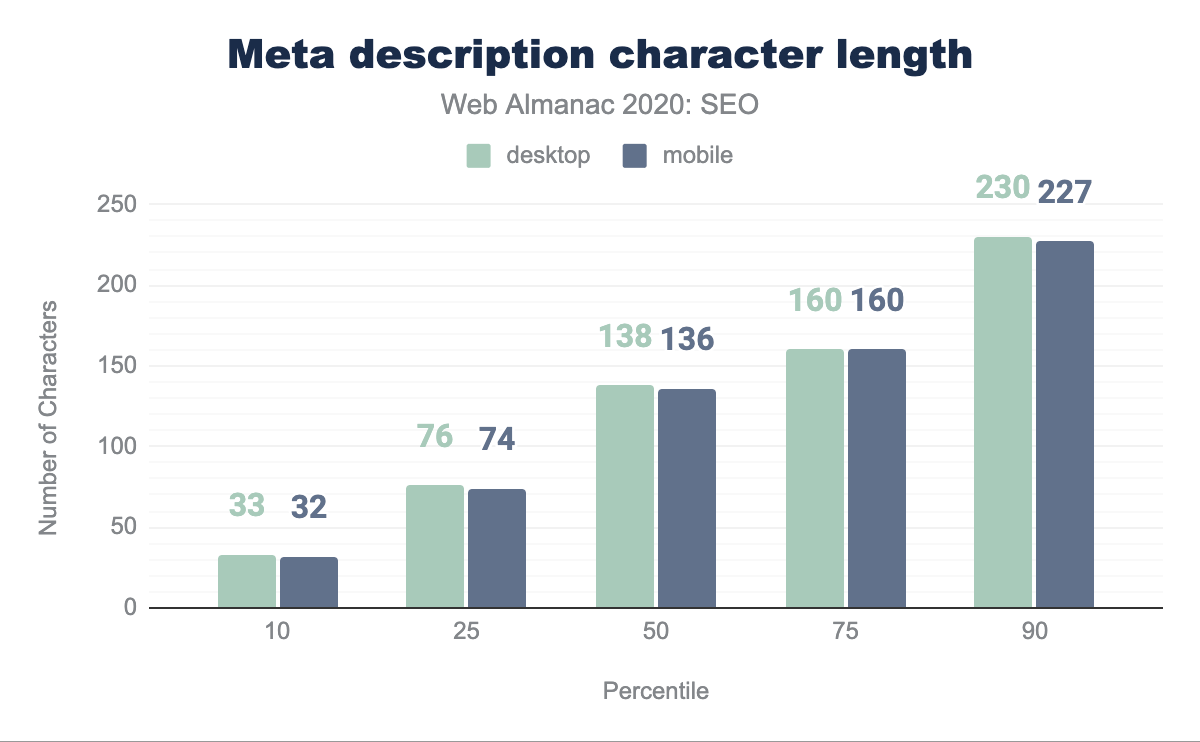
En promedio, el número de caracteres para la meta descripción es de 138 caracteres en páginas de escritorio y 136 caracteres en páginas móviles. Aparte del percentil 75, hay una pequeña disparidad entre la longitud de las meta descripciones en escritorio y en móvil distribuida en el conjunto de datos. Las buenas prácticas SEO sugieren limitar la meta descripción a 160 caracteres, pero Google, inconsistentemente, puede mostrar hasta 300 caracteres en sus fragmentos.
Las meta descripciones siguen impulsando otros fragmentos como los sociales y de noticias, y dado que Google continuamente las reescribe, y no las considera un factor de posicionamiento directo, es razonable esperar que las meta descripciones seguirán creciendo más allá del límite de 160 caracteres.
Imágenes
El uso de imágenes, particularmente usando etiquetas img dentro de una página, suele sugerir un enfoque en la presentación visual del contenido. Aunque las capacidades de los motores de búsqueda en términos de visión artificial han seguido mejorando, no tenemos indicación de que esta tecnología es usada en el posicionamiento de páginas. Los atributos alt siguen siendo la forma principal de explicar una imagen debido a la actual incapacidad de los motores de búsqueda de “verla”. Los atributos alt también soportan accesibilidad y clarifican los elementos en la página para usuarios con alguna discapacidad visual.
En promedio, las páginas de escritorio incluyen 21 etiquetas img y el promedio en páginas móviles es de 19 etiquetas img. La web sigue tendiendo a la carga de imágenes con el crecimiento del ancho de banda y omnipresencia de los smartphones. Sin embargo, esto tiene un costo de rendimiento.
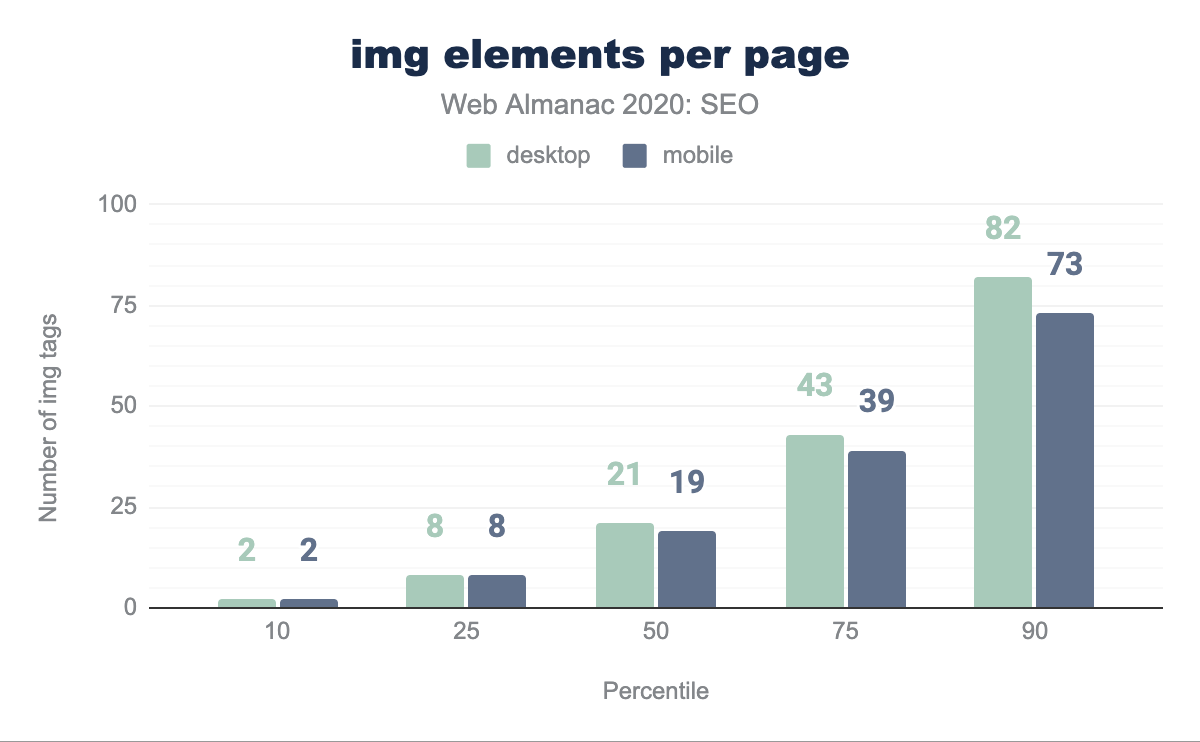
<img> por página por percentil (10, 25, 50, 75, y 90). En promedio, las páginas de escritorio incluyen 21 elementos <img> y las página móviles incluyen 19 etiquetas <img>.<img> por página.
La página web promedio no tiene 2.99% de los atributos alt en escritorio y 2.44% de los atributos alt en móvil. Para más información sobre la importancia de los atributos alt, revisa el capítulo de Accesibilidad.
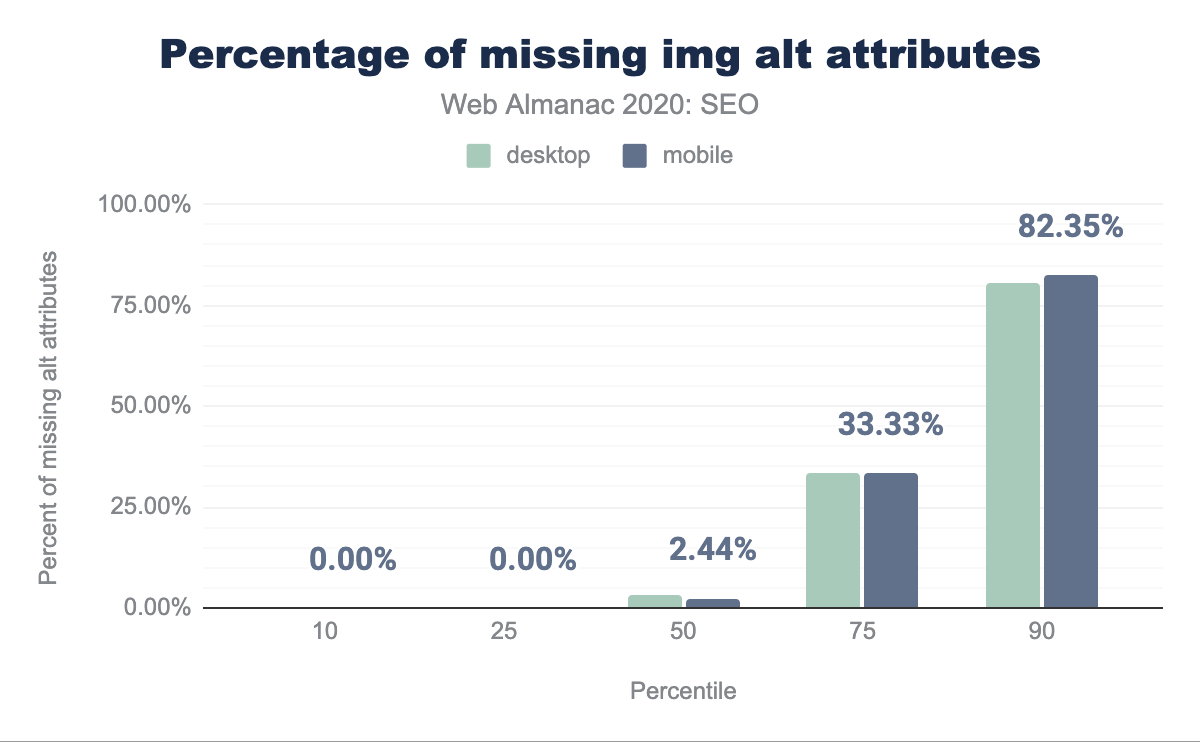
alt faltantes por percentil (10, 25, 50, 75, y 90). En promedio, 2.99% de las páginas de escritorio no tienen atributos alt faltantes y 2.44% de atributos alt faltantes en móvil.<img> con atributo alt faltante por página.
Encontramos que, en promedio, las páginas incluyen atributos alt en solo 51.22% de sus imágenes.
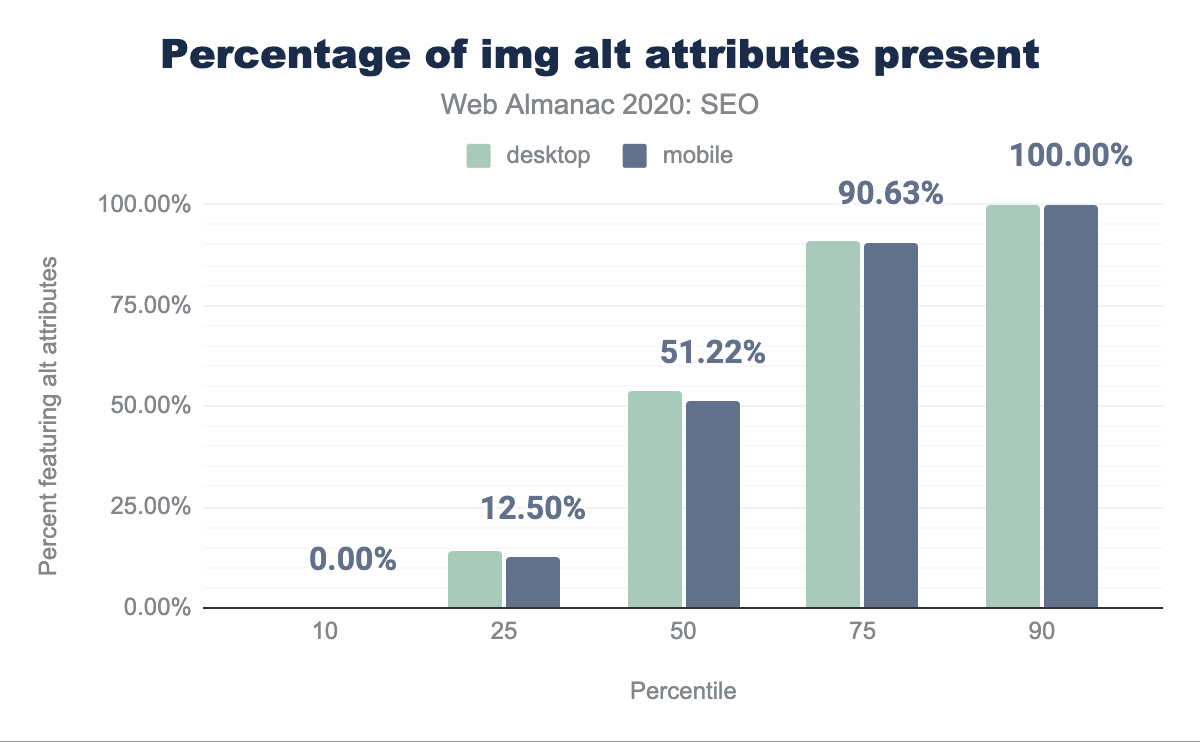
alt presentes por percentil (10, 25, 50, 75, y 90). Se encontró que solo 53.86% de las páginas de escritorio y 51.22% de las páginas móviles incluyen imágenes con atributos alt.alt por página.
En promedio, las páginas web tienen 10.00% de imágenes con un atributo alt vació en escritorio y 11.11% en móvil.
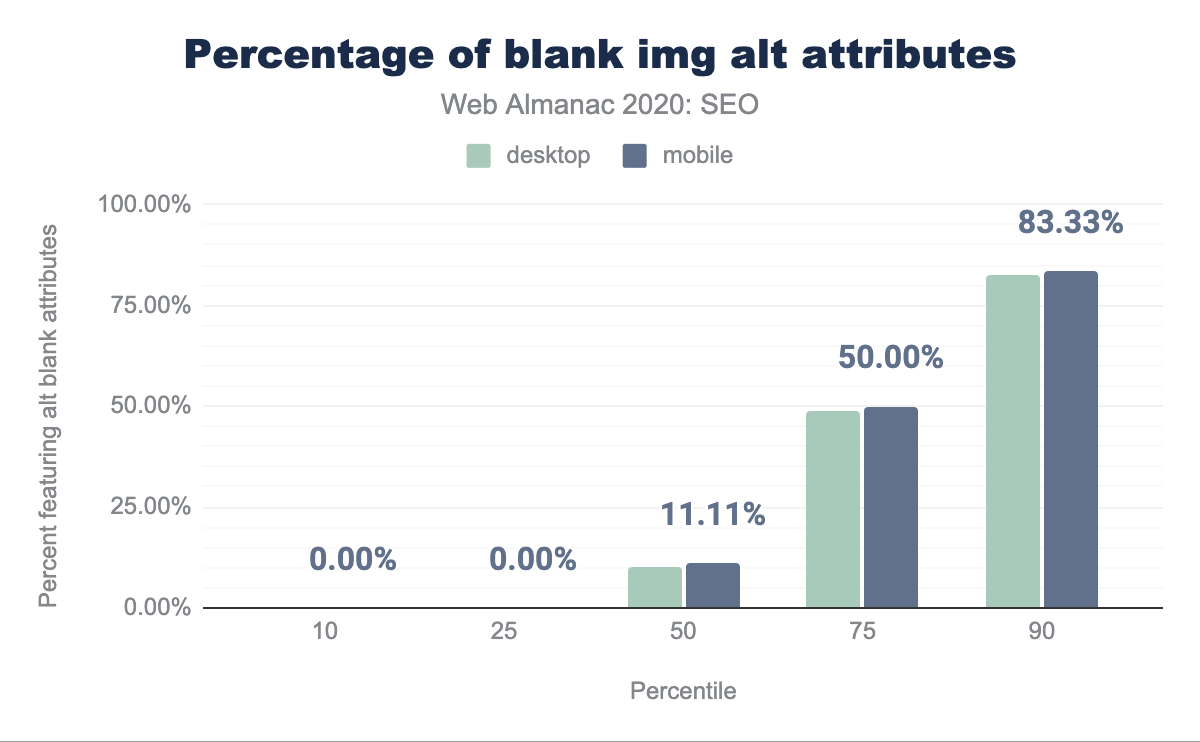
alt incluidos por percentil (10, 25, 50, 75, y 90). En promedio, las páginas de escritorio incluyen 10% de atributos alt vacíos y las páginas móviles incluyen 11.11% de atributos alt vacíos.alt vacíos por página.
Enlaces
Los motores de búsqueda modernos usan los hipervínculos entre páginas para el descubrimiento de nuevo contenido a indexar y como una indicación de autoridad para el posicionamiento. La gráfica de enlaces es algo que los motores de búsqueda usan tanto algorítmicamente y con revisiones manuales. Las páginas web transmiten equidad de enlaces en sus sitios y a sitios externos a través de estos hipervínculos, por lo tanto, es importante asegurar que haya una diversidad de enlaces en cualquier página, pero también como Google lo menciona en su Guía SEO para principiantes, utilizar los enlaces de forma adecuada.
Enlaces salientes
Como parte de este análisis pudimos evaluar los enlaces salientes de cada página, tanto a páginas internas del mismo dominio como a externas, sin embargo, no se analizaron los enlaces entrantes.
En promedio, las páginas de escritorio incluyen 78 enlaces mientras que el promedio en páginas móviles es de 67. Históricamente, la orientación de Google sugería que los enlaces se limitaran a 100 por página. Si bien esa recomendación está obsoleta en la web moderna y desde entonces Google ha mencionado que no hay límites, el promedio de nuestro conjunto de datos se adhiere a ello.
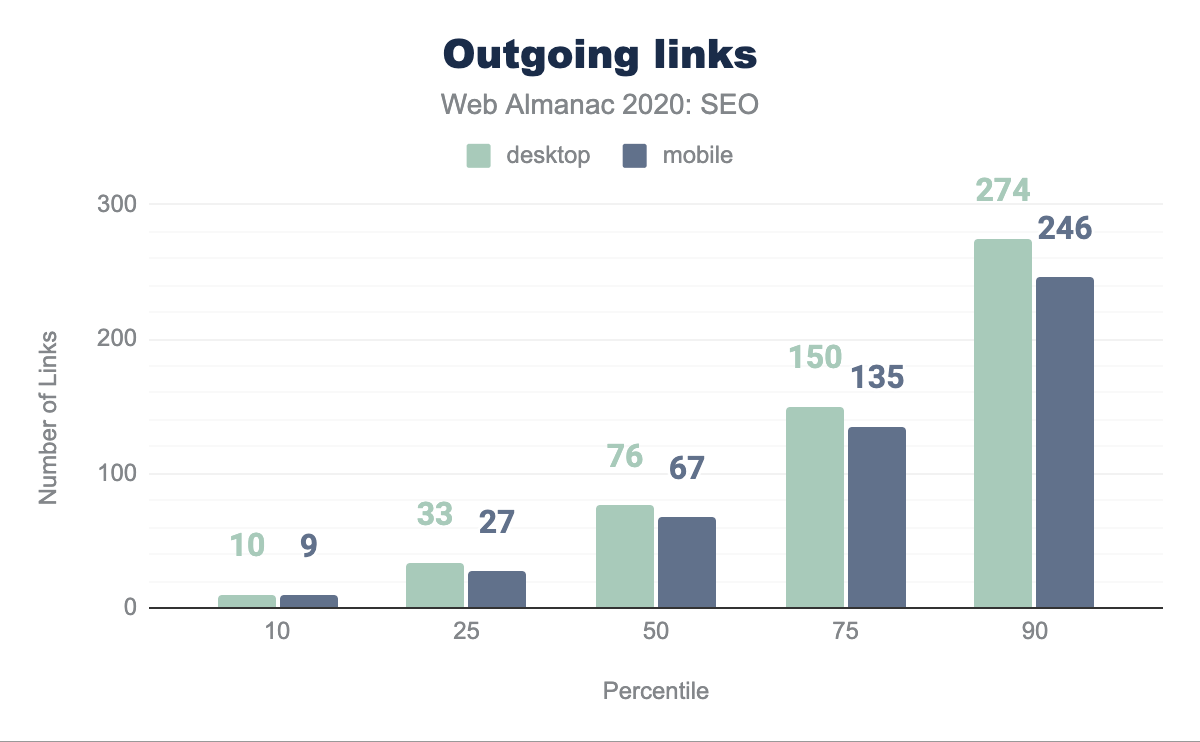
En promedio, la página de escritorio tiene 61 enlaces internos (dirigidos a páginas dentro del mismo sitio) y 54 en móvil. Esto es una reducción del 12.8% y 10% respectivamente en comparación con el análisis del año pasado. Esto sugiere que los sitios no están aprovechando la habilidad de mejorar el rastreo y el flujo de la equidad de enlaces en sus páginas de la forma que lo hacían el año pasado.
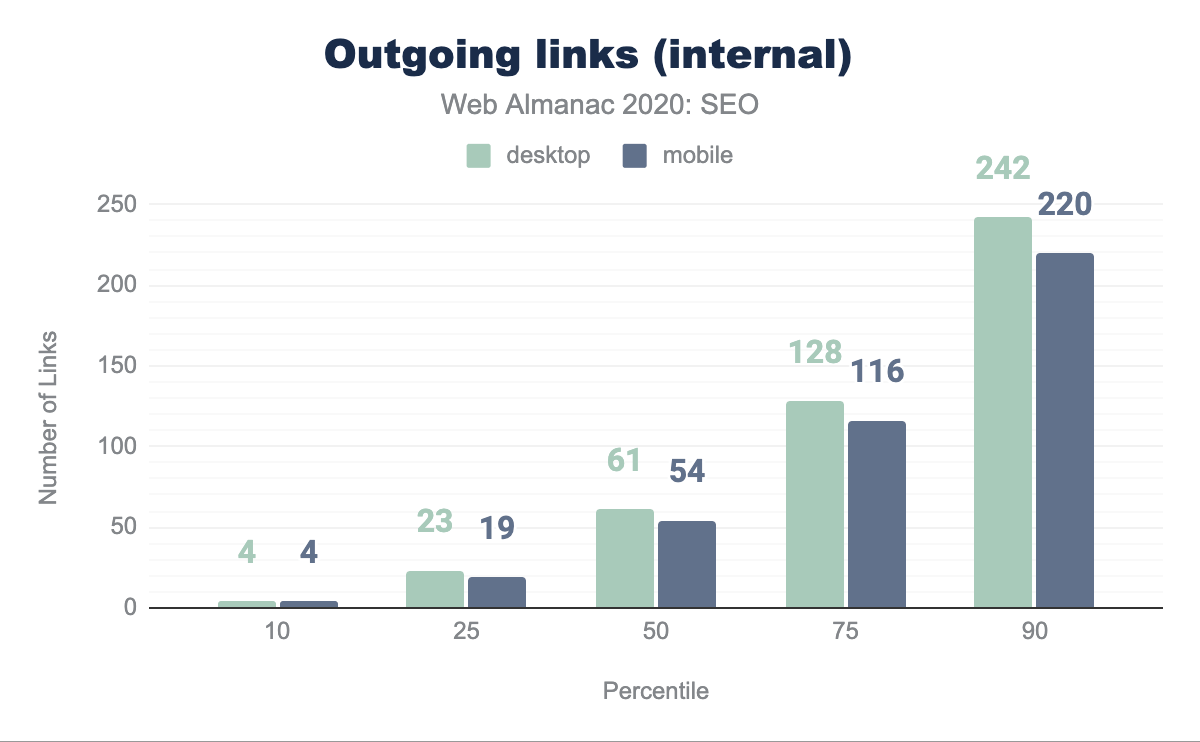
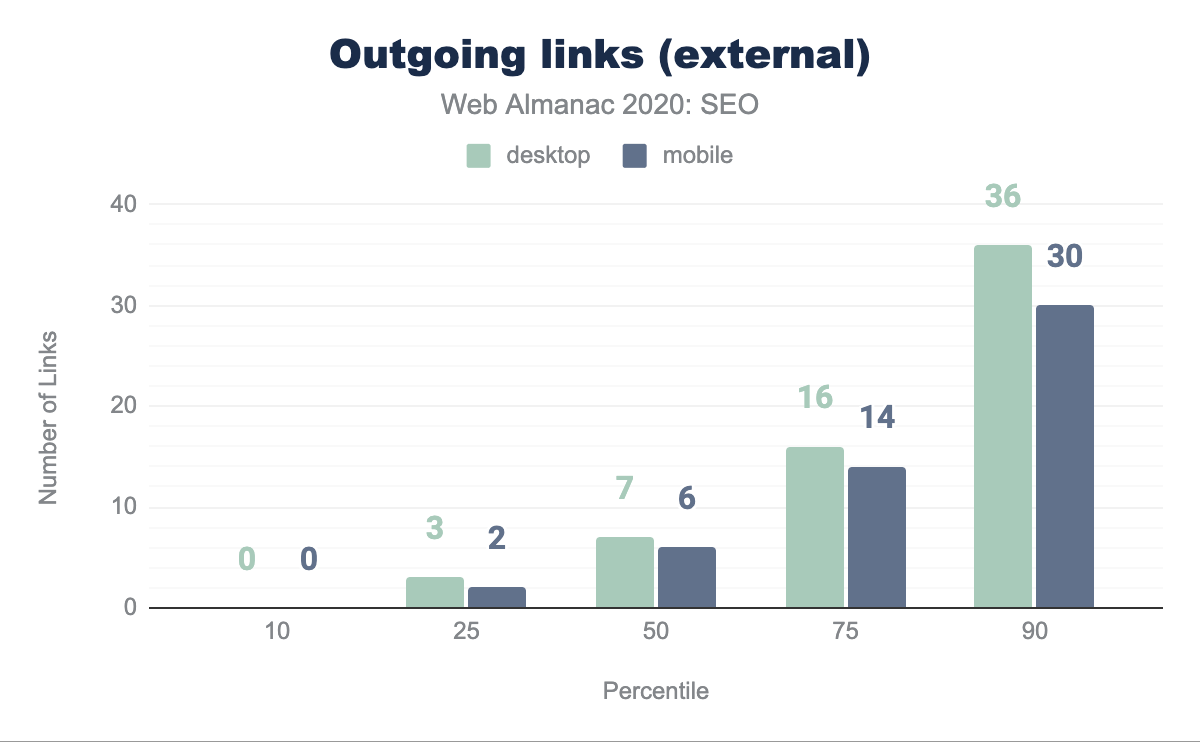
En promedio, las páginas están enlazando a sitios externos 7 veces en escritorio y 6 veces en móvil. Esto es una reducción respecto al año pasado, cuando se encontró que en promedio había 10 enlaces externos en escritorio y 8 en móvil. Esta disminución en enlaces externos puede sugerir que los sitios web ahora son más cuidadosos al enlazar a otros sitios, ya sea para transmitir equidad de enlaces o referir a los usuarios hacia ellos.
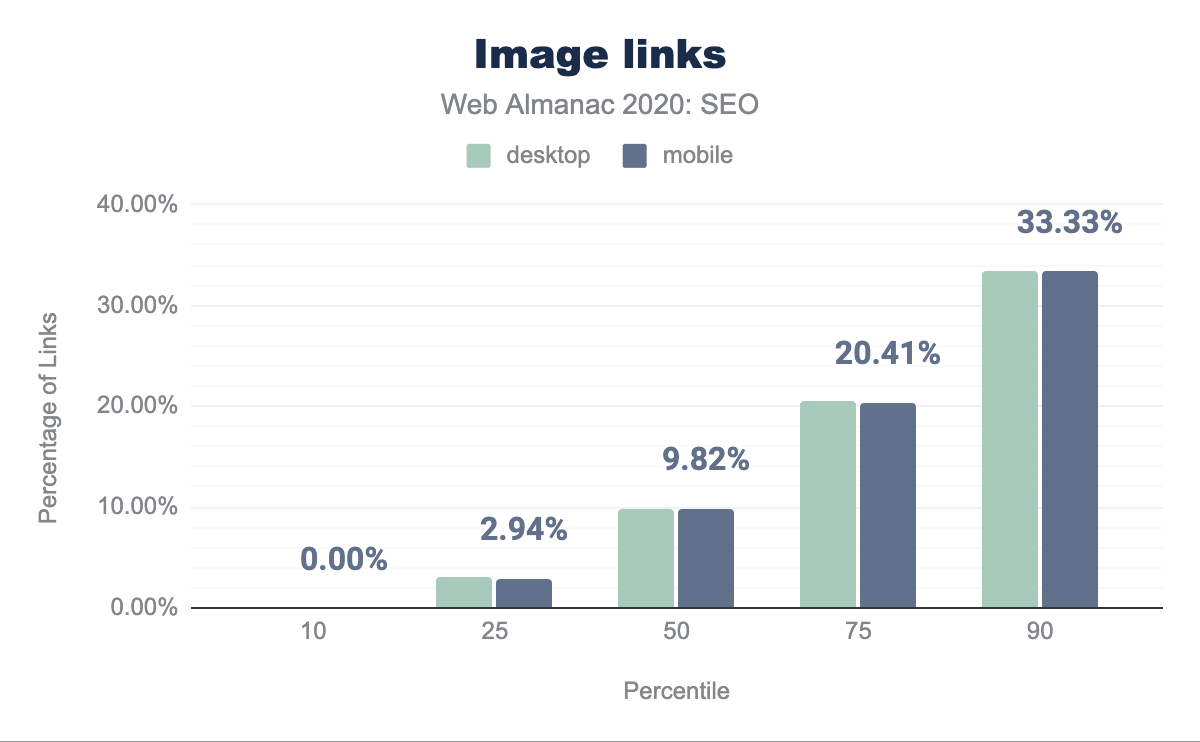
Enlaces de texto vs. de imagen
La página web promedio usa una imagen como texto de anclaje para enlazar en 9.80% de las páginas de escritorio y 9.82% de las páginas móviles. Estos enlaces representan oportunidades perdidas para implementar textos de anclaje relevantes para palabras clave.
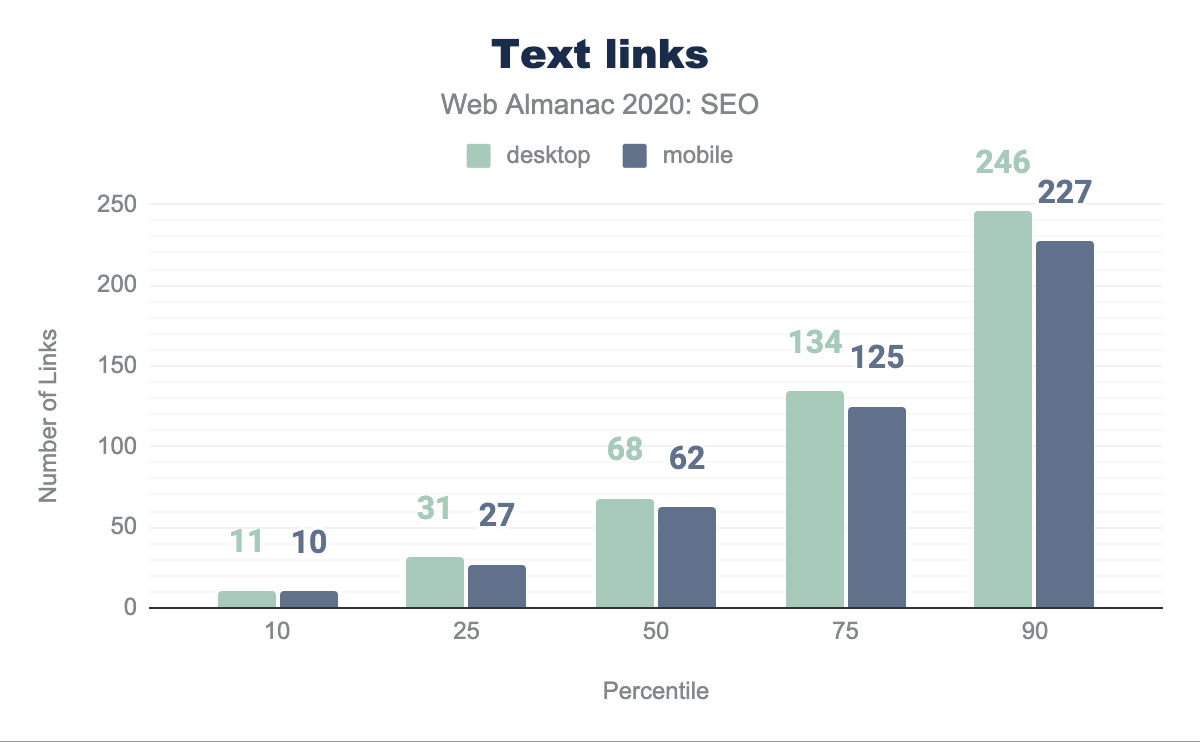
Enlaces móviles vs. de escritorio
Hay una disparidad en los enlaces entre móvil y escritorio que afectará negativamente a los sitios a medida que Google se vuelve más comprometido con el índice únicamente móvil (mobile-only) en lugar de solo móvil primero (mobile-first). Esto es ilustrado en los 62 enlaces móviles contra los 68 enlaces en escritorio en las páginas promedio.
Uso de los atributos rel=nofollow, ugc, y sponsored
En Septiembre de 2019, Google introdujo atributos que permitirían a los publicadores de contenido clasificar enlaces como patrocinados o generados por el usuario. Estos atributos se suman al rel=nofollow, que fue previamente introducido en 2005. Los nuevos atributos, rel=ugc y rel=sponsored, están pensados para aclarar o precisar la razón de por qué aparecen esos enlaces en una página web.
Nuestra revisión indica que 28.58% de las páginas incluyen el atributo rel=nofollow en escritorio y 30.74% en móvil. Sin embargo, la adopción de rel=ugc y rel=sponsored es bastante baja con menos del 0.3% (aproximadamente 20,000) teniendo uno de los dos. Ya que estos atributos no tienen valor adicional para el publicador de contenido que el rel=nofollow, es razonable esperar que el índice de adopción siga siendo bajo.
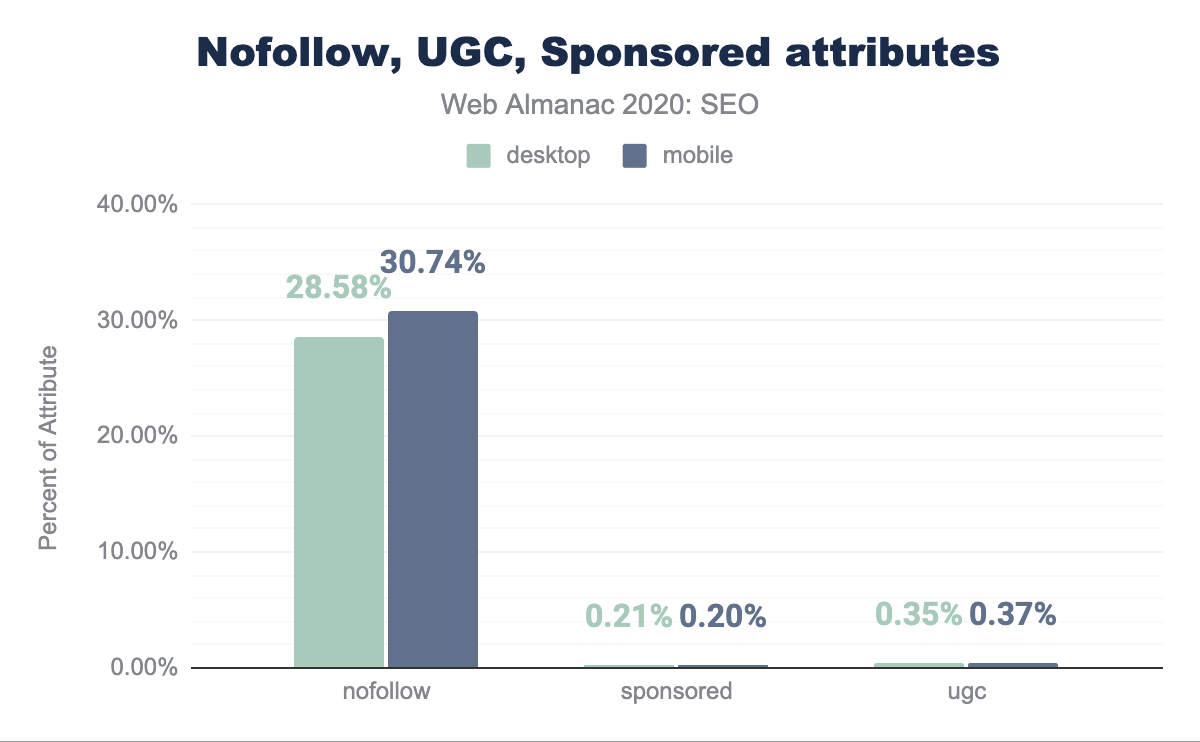
rel en escritorio y móvil. Nuestra revisión indica que 28.58% de las páginas usan el atributo nofollow en sus versiones de escritorio y 30.74% en móvil. Sin embargo, la adopción de ugc y sponsored es bastante baja con menos del 0.3% de las páginas usando cualquiera de ellos.rel=nofollow, rel=ugc, y rel=sponsored.
Avanzado
Esta sección explora las oportunidades de optimización relacionadas a configuraciones web y elementos que pueden no afectar directamente la rastreabilidad e indexabilidad de un sitio, pero que han sido confirmados por los motores de búsqueda como señales de posicionamiento o afectarán la capacidad de los sitios web para aprovecharlas funcionalidades de búsqueda.
Compatibilidad móvil
Con el aumento en la popularidad de los dispositivos móviles para navegar y buscar en la web, los motores de búsqueda han estado considerando la compatibilidad móvil como un factor de posicionamiento por varios años.
Además, como fue mencionado antes, desde 2016 Google se ha ido cambiando a un índice móvil primero (mobile-first), lo que significa que el contenido rastreado, indexado y posicionado es el accesible a los usuarios móvil y al Googlebot móvil.
Adicionalmente, desde Julio de 2019 Google ha estado usando el índice mobile-first para todos los nuevos sitios y recientemente en Marzo anunció que 70% de las páginas que se muestran en sus resultados ya han sido migrados. Ahora se espera que Google cambie totalmente a un índice mobile-first en Marzo de 2021.
La compatibilidad móvil debería ser fundamental para cualquier sitio web que busca brindar una buena experiencia de búsqueda, y como consecuencia, crecer en los resultados de búsqueda.
Un sitio web compatible con dispositivos móviles puede ser implementado a través de diferentes configuraciones: al usar diseño web responsivo (responsive design), con publicación dinámica, o usando una versión móvil independiente. Sin embargo, mantener un sitio web móvil independiente ya no es recomendado por Google, que ahora promueve el diseño web responsivo.
Meta etiqueta viewport
El viewport de un navegador es la parte visible del contenido, que cambia dependiendo del dispositivo usado. La etiqueta <meta name="viewport"> (o meta etiqueta viewport) permite especificar a los buscadores el ancho y la escala del viewport, para que sea ajustado correctamente en los diferentes dispositivos. Los sitios responsivos usan la meta etiqueta viewport, así como media queries en CSS para brindar una experiencia móvil más amigable.
42.98% de las páginas móviles y 43.2% de las de escritorio tienen una meta etiqueta viewport con el atributo content=initial-scale=1,width=device-width. Sin embargo, 10.84% de las páginas móviles y 16.18% de las de escritorio no incluyen dicha etiqueta, lo que sugiere que aún no son compatibles con dispositivos móviles.
| Viewport | Móvil | Escritorio |
|---|---|---|
initial-scale=1,width=device-width |
42.98% | 43.20% |
| not-set | 10.84% | 16.18% |
initial-scale=1,maximum-scale=1,width=device-width |
5.88% | 5.72% |
initial-scale=1,maximum-scale=1,user-scalable=no,width=device-width |
5.56% | 4.81% |
initial-scale=1,maximum-scale=1,user-scalable=0,width=device-width |
3.93% | 3.73% |
content de la meta etiqueta viewport.
Media queries de CSS
Los media queries son una funcionalidad de CSS3 que juegan un rol fundamental en el diseño web responsivo, ya que permiten especificar condiciones para aplicar estilos únicamente cuando el navegador y dispositivo cumplen ciertas reglas. Esto permite crear diferentes composiciones para el mismo HTML dependiendo del tamaño del viewport.
Encontramos que 80.29% de las páginas de escritorio y 82.92% de las móviles usan las propiedades CSS height, width, o aspect-ratio, es decir, un alto porcentaje de páginas tienen propiedades responsivas. Las propiedades más populares pueden ser visualizadas en la tabla a continuación.
| Propiedad | Mobile | Desktop |
|---|---|---|
max-width |
78.98% | 78.33% |
min-width |
75.04% | 73.75% |
-webkit-min-device-pixel-ratio |
44.63% | 38.78% |
orientation |
33.48% | 33.49% |
max-device-width |
26.23% | 28.15% |
Vary: User-Agent
Al implementar un sitio web compatible con dispositivos móviles con publicación dinámica-donde muestras diferentes HTMLs de la misma página según el dispositivo usado-es recomendable añadir un Vary: User-Agent HTTP header para ayudar a los motores de búsqueda a descubrir el contenido móvil al rastrear el sitio, ya que se informa que la respuesta varía del agente de usuario.
Se encontró que únicamente 13.48% de las páginas móviles y 12.6% de las de escritorio especifican un Vary: User-Agent header.
<link rel="alternate" media="only screen and (max-width: 640px)">Se recomienda que los sitios web de escritorio que tienen una versión móvil independiente enlacen a ella usando esta etiqueta en el head de su HTML. Solo 0.64% de las páginas de escritorio analizadas incluyen esta etiqueta con el valor especificado del atributo media
Rendimiento de la web
Tener un sitio web que cargue rápido es fundamental para proporcionar una gran experiencia de búsqueda al usuario. Debido a su importancia, los motores de búsqueda lo han considerado como un factor de posicionamiento desde hace años. Google inicialmente anunció que usaba la velocidad de carga como un factor de posicionamiento en 2010, y lo confirmo de nuevo en 2018 para las búsquedas móviles.
Como se anunció en Noviembre de 2020, 3 métricas de rendimiento conocidas como las Core Web Vitals están en camino a ser un factor de posicionamiento como parte de las señales de “experiencia de página” en Mayo de 2021. Las Core Web Vitals consisten en:
Largest Contentful Paint (LCP)
- Representa: experiencia de carga percibida por el usuario
- Medición: el punto en la línea del tiempo de carga cuando la imagen o bloque de texto más largo de la página es visible dentro del viewport
- Objetivo: <2.5 segundos
First Input Delay (FID)
- Representa: respuesta a entradas del usuario
- Medición: el tiempo desde que un usuario interactúa inicialmente con la página hasta el tiempo en que el navegador es capaz de empezar a procesar los manejadores de eventos en respuesta a esa interacción
- Objetivo: <300 milisegundos
Cumulative Layout Shift (CLS)
- Representa: estabilidad visual
- Medición: la suma del número de puntuaciones de los cambios de composición aproximando el porcentaje en que cambió el viewport
- Objetivo: <0.10
Experiencia de los Core Web Vitals por dispositivo
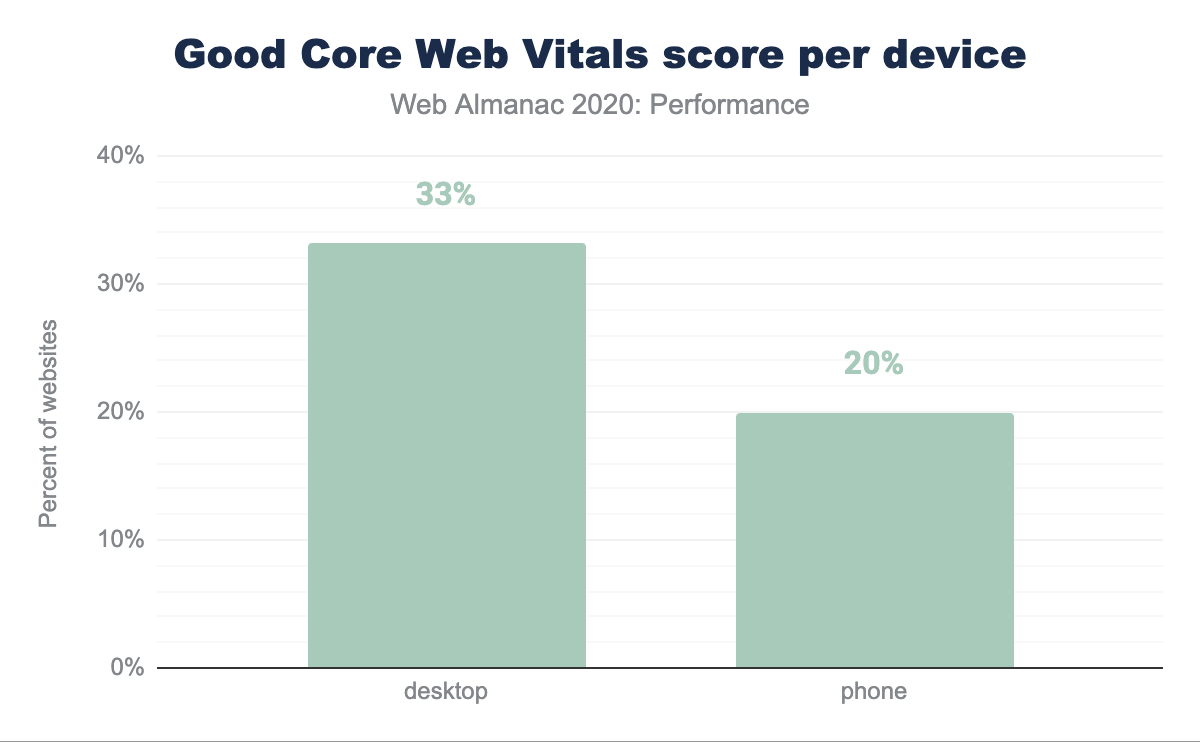
Escritorio sigue siendo la plataforma de mayor rendimiento para los usuarios a pesar de que hay más usuarios en dispositivos móviles. 33.13% de los sitios web obtuvieron una calificación Buena en los Core Web Vitals para escritorio mientras que solo 19.96% de sus equivalentes móviles pasaron la evaluación de los Core Web Vitals.
Experiencia de los Core Web Vitals por país
La ubicación física del usuario influye en la percepción del rendimiento, ya que la infraestructura de telecomunicaciones disponible a nivel local, la capacidad del ancho de banda de la red, y el costo de los datos crean condiciones de carga únicas.
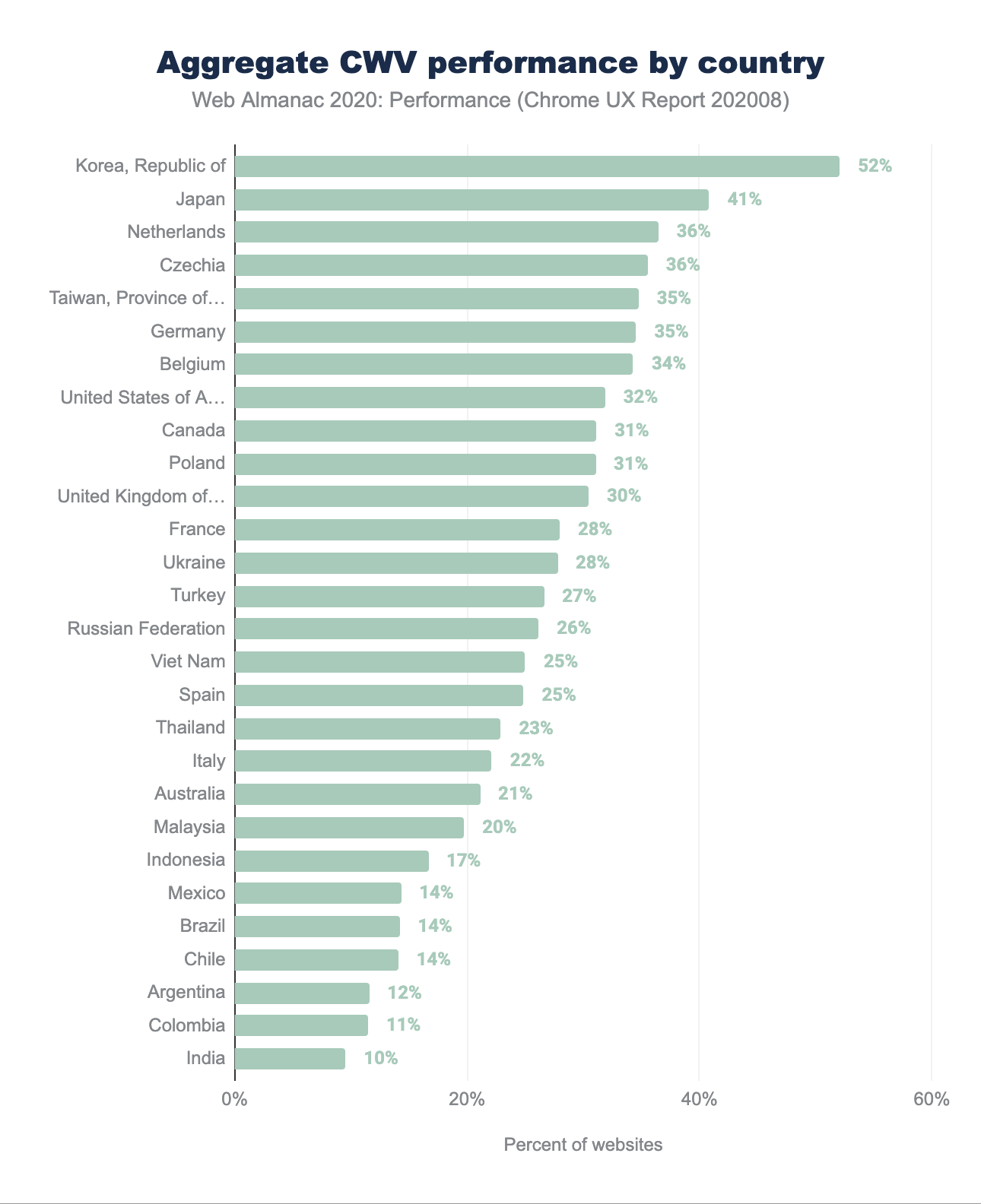
Los usuarios ubicados en los Estados Unidos registraron el mayor número absoluto de sitios web con Buena experiencia de los Core Web Vitals a pesar de que solo 32% de los sitios obtuvieron la calificación de aprobación. La República de Corea registró el mayor porcentaje de experiencia Buena de los Core Web Vitals con 52%. Cabe mencionar la proporción relativa total de los sitios web solicitados por país. Los usuarios en Estados Unidos generaron 8 veces más solicitudes de origen que los usuarios de La República de Corea.
Análisis adicionales del rendimiento de los Core Web Vitals por dimensiones según el tipo de conexión efectiva y métricas específicas están disponibles en el capítulo de Rendimiento.
Internacionalización
La internacionalización abarca las configuraciones que pueden utilizar los sitios web multi-idioma o multi-país para informar a los motores de búsqueda sobre sus diferentes versiones por idioma y/o país, especificando las páginas relevantes para mostrar a los usuarios en cada caso, y evitar problemas de localización.
Las dos configuraciones internacionales que analizamos son la meta etiqueta content-language y los atributos hreflang, que pueden ser usados para especificar el idioma y contenido de cada página. Adicionalmente, las anotaciones hreflang permiten especificar versiones de idioma o país alternas para cada página.
Los motores de búsqueda como Google y Yandex usan los atributos hreflang como una señal para determinar el idioma y país objetivo de una página, aunque Google no usa el HTML lang o la meta etiqueta content-language, esta última es usada por Bing.
hreflang
8.1% de las páginas de escritorio y 7.48% de las páginas móviles usan el atributo hreflang, que puede parecer bajo, pero es natural porque solo es utilizado por sitios multi-idioma o multi-país.
Encontramos que solo 0.09% de las páginas de escritorio y 0.07% de las páginas móviles implementan hreflang usando sus HTTP headers, y que la mayoría se basan en la implementación en el head del HTML.
También identificamos que hay algunas páginas que dependen de JavaScript para renderizar las anotaciones hreflang. 0.12% de las páginas de escritorio y móviles muestran hreflang en su HTML renderizado, pero no en el puro.
Desde un punto de vista de valores de idioma y país, al analizar la implementación usando el HTML head, encontramos que Inglés (en) es el valor más popular, con 4.11% de las páginas móviles y 4.64% de las páginas de escritorio usándolo. Después de Inglés, el segundo valor más popular es x-default (usado para definir una versión por defecto o de respaldo para usuarios de idiomas o países no seleccionados), con 2.07% de las páginas móviles y 2.2% de las páginas de escritorio usándolo.
El tercer, cuarto y quinto más popular son Alemán (de), Francés (fr) y Español (es), seguido de Italiano (it) e Inglés para los Estados Unidos (en-us), tal y como se puede visualizar en la tabla siguente con el resto de los valores implementados desde el head del HTML.
| Valor | Móvil | Escritorio |
|---|---|---|
en |
4.11% | 4.64% |
x-default |
2.07% | 2.20% |
de |
1.76% | 1.88% |
fr |
1.74% | 1.87% |
es |
1.74% | 1.84% |
it |
1.27% | 1.33% |
en-us |
1.15% | 1.31% |
ru |
1.12% | 1.13% |
en-gb |
0.87% | 0.98% |
pt |
0.87% | 0.87% |
nl |
0.83% | 0.94% |
ja |
0.73% | 0.81% |
pl |
0.72% | 0.75% |
de-de |
0.69% | 0.78% |
tr |
0.69% | 0.66% |
hreflang más populares en el HTML head.
Algo ligeramente diferente fue encontrado en los valores hreflang de idioma y país más populares implementados en los HTTP headers, con Inglés (en) siendo otra vez el más popular, aunque en este caso le siguen Francés (fr), Alemán (de), Español (es), y Neerlandés (nl) como los más populares.
| Valor | Móvil | Escritorio |
|---|---|---|
en |
0.05% | 0.06% |
fr |
0.02% | 0.02% |
de |
0.01% | 0.02% |
es |
0.01% | 0.01% |
nl |
0.01% | 0.01% |
hreflang más populares en los HTTP headers.
Content-Language
Al analizar el uso de content-language y sus valores, ya sea implementándolo como una meta etiqueta en el head del HTML o en los HTTP headers, encontramos que solo 8.5% de las páginas móviles y 9.05% de las páginas de escritorio lo especifican en los HTTP headers. Aún menos sitios web lo especifican con su idioma o país en la etiqueta content-language en el head del HTML, con solo 3-63% de las páginas móviles y 3.59% de las páginas de escritorio incluyéndolo en la meta etiqueta.
Desde un punto de vista de valores de idioma y país, encontramos que los valores más populares especificados en la meta etiqueta content-language y los HTTP headers son Inglés (en) e Inglés para Estados Unidos (en-us).
En el caso de Inglés (en), identificamos que 4.34% de las páginas de escritorio y 3.69% de las páginas móviles lo especifican en los HTTP headers y 0.55% de las páginas de escritorio y 0.48% de las páginas móviles lo hacían usando la meta etiqueta content-language en el head del HTML.
Para Inglés de Estados Unidos (en-us), el segundo valor más popular, se encontró que solo 1.77% de las páginas móviles y 1.7% de las páginas de escritorio lo especificaban en los HTTP headers, y 0.3% de las páginas móviles y 0.36% de las de escritorio lo hacían desde el HTML.
El resto de los valores de idioma y país más populares puede ser visualizado en la tabla siguente.
| Valor | Móvil | Escritorio |
|---|---|---|
en |
3.69% | 4.34% |
en-us |
1.77% | 1.70% |
de |
0.50% | 0.44% |
es |
0.34% | 0.33% |
fr |
0.31% | 0.34% |
ru |
0.18% | 0.16% |
pt-br |
0.15% | 0.16% |
nl |
0.13% | 0.15% |
it |
0.13% | 0.13% |
ja |
0.08% | 0.10% |
content-language en los HTTP headers.
| Valor | Móvil | Escritorio |
|---|---|---|
en |
0.48% | 0.55% |
en-us |
0.30% | 0.36% |
pt-br |
0.24% | 0.24% |
ja |
0.19% | 0.26% |
fr |
0.18% | 0.19% |
tr |
0.17% | 0.13% |
es |
0.16% | 0.15% |
de |
0.15% | 0.11% |
cs |
0.12% | 0.12% |
pl |
0.11% | 0.09% |
content-language en meta etiquetas HTML.
Seguridad
Google presta especial atención a la seguridad en todos los aspectos. El buscador mantiene una lista de sitios que han mostrado actividad sospechosa o han sido hackeados. Search Console perfila estos problemas y los usuarios de Chrome son presentados con advertencias antes de visitar sitios con estos problemas. Además, Google proporciona un impulso algorítmico a páginas que se ofrecen a través de HTTPS (Protocolo seguro de transferencia de hipertextos). Para un análisis más profundo en este tema, revisa el capítulo de Seguridad.
Uso de HTTPS
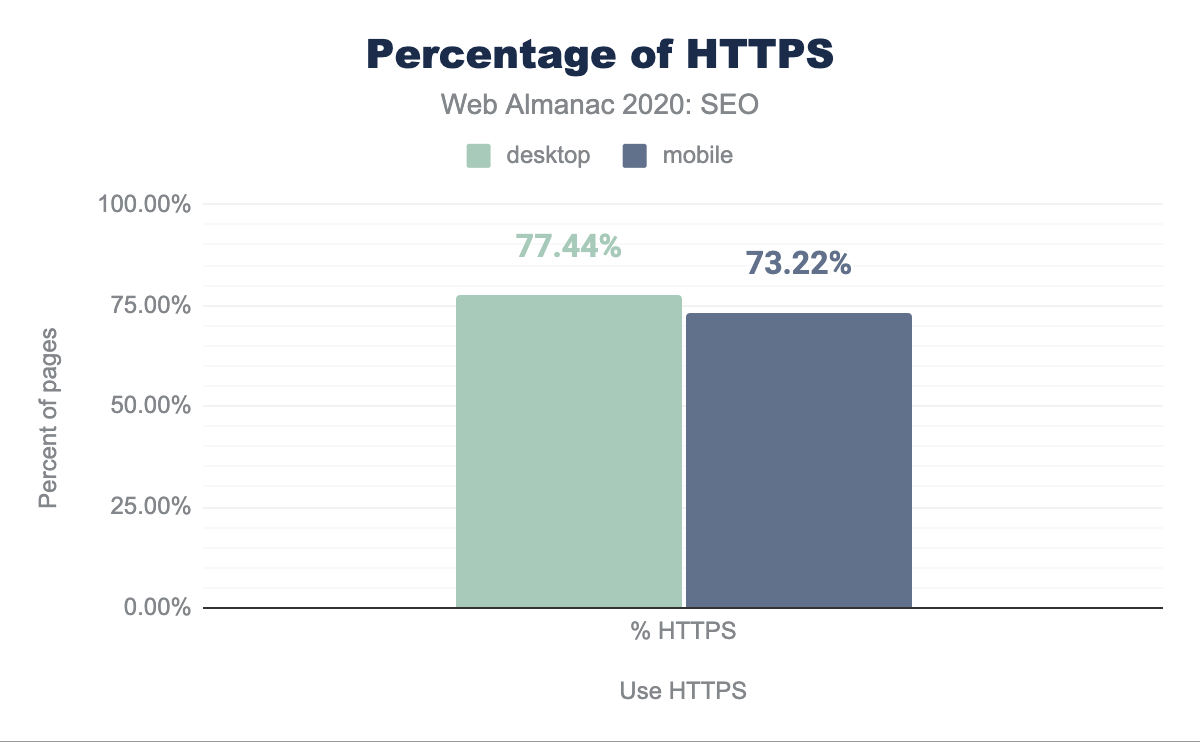
Encontramos que 77.44% de las páginas de escritorio y 73.22% de las páginas móviles han adoptado el uso de HTTPS. Esto es un aumento de 10.38% respecto al año pasado. Es importante mencionar que los buscadores se han vuelto más agresivos en promover HTTPS al señalar que las páginas son inseguras cuando las visitas sin HTTPS. Además, HTTPS es un requisito actual para capitalizar en otros protocolos de mayor rendimiento como HTTP/2 and HTTP/3 (también conocido como HTTP sobre QUIC). Puedes aprender más sobre el estado de estos protocolos en el capítulo de HTTP/2.
Todo esto ha probablemente contribuido a una mayor tasa de adopción año tras año.
AMP
AMP (previamente llamado Páginas Móviles Aceleradas o Accelerated Mobile Pages), es un framework de HTML open source que fue lanzado por Google en 2015 como una forma de ayudar a las páginas a cargar más rápido, especialmente en dispositivos móviles. AMP puede ser implementado como una versión alterna de páginas existentes o desarrollado desde cero usando el AMP framework.
Cuando hay una versión AMP disponible para una página, Google la mostrará en los resultados de búsqueda móviles junto con el logo de AMP.
También es importante tener en cuenta que, aunque el uso de AMP no es un factor de posicionamiento para Google (o cualquier otro buscador), la velocidad de carga sí es un factor de posicionamiento.
Adicionalmente, en el momento de escribir este artículo, AMP es un requisito para ser incluido en el carrusel de Top Stories de Google en los resultados de búsqueda móvil, que es una característica importante para publicaciones relacionadas con noticias. Sin embargo, esto cambiará en Mayo de 2021, cuando el contenido que no use AMP será elegible, siempre y cuando cumpla con las políticas de contenido de Google News y brinden una buena experiencia de página tal y como lo anunció Google en Noviembre de este año.
Al revisar el uso de AMP como una versión alterna de una página que no usa AMP, encontramos que 0.69% de las páginas móviles y 0.81% de las páginas de escritorio incluían una etiqueta amphtml apuntando a su versión AMP. Aunque la adopción es aún muy baja, hay una ligera mejora en comparación con los datos del año pasado, donde solo 0.62% de las páginas móviles contenían un enlace a una versión AMP.
Por otro lado, al evaluar el uso de AMP como un framework para desarrollar sitios web, encontramos que solo 0.18% de las páginas móviles y 0.07% de las páginas de escritorio especificaban los atributos <html amp> o <html ⚡>, que son usados para indicar páginas basadas en AMP.
Single-page applications
Las Single-page applications (SPAs) o aplicaciones de página única, permiten a los navegadores retener y actualizar la carga de una página aún cuando el contenido de la página se actualiza para ajustarse a la solicitud del usuario. Múltiples tecnologías como frameworks de JavaScript, AJAX, y WebSockets son usados para logar cargas subsecuentes ligeras de la página.
Estos frameworks requerían consideraciones SEO especiales, aunque Google ha trabajado para mitigar los problemas causados por el renderizado del lado del cliente con estrategias de memoria caché agresivas. En un video de la conferencia de Google Webmaster’s en 2019, el Ingeniero de Software Erik Hendriks compartió que Google ya no depende los headers de Cache-Control y en su lugar busca los ETag o Last-Modified headers para ver si el contenido del archivo ha cambiado.
SPAs deberían utilizar la Fetch API para un control granular de la memoria caché. Esta API permite la transmisión de objetos Request con ajustes específicos de la caché y puede ser usada para especificar, cuando sea necesario, los If-Modified y ETag headers.
Los recursos no descubiertos siguen siendo la principal preocupación de los motores de búsqueda y sus rastreadores. Los rastreadores de búsqueda buscan por los atributos href en las etiquetas <a> para encontrar páginas enlazadas. Sin ellos, la página se considera aislada sin enlaces internos. 5.59% de las páginas de escritorio estudiadas no contenían enlaces internos, así como 6.04% de las páginas móviles renderizada. Esto es un indicador de que la página es parte de un framework de JavaScript para SPA y que hacen falta etiquetas <a> con atributos href válidos para que su enlazado interno sea descubierto.
La capacidad de descubrimiento de los enlaces en frameworks de JavaScript populares usados para SPAs ha incrementado drásticamente en 2020 respecto al año pasado. En 2019, 13.08% de los enlaces móviles de navegación en sitios con React usaban hash URLs (URLs con #). Para 2020, solo 6.12% de los enlaces en React revisados usaban URLs con hash.
De la misma manera, Vue.js tuvo un decremento a 3.45% comparado con el 8.15% del año pasado. Angular fue el menos probable de utilizar enlaces de navegación móviles con hash en 2019 con solo 2.37% de las páginas móviles usándolo. Para 2020, ese número se redujo a 0.21%
Conclusión
En conformidad con lo que se encontró y concluyó el año pasado, la mayoría de los sitios tienen páginas de escritorio y móviles rastreables e indexables, y están haciendo uso de las configuraciones SEO fundamentales.
Es importante resaltar cómo el descubrimiento de enlaces para los frameworks de JavaScript más populares usados en SPAs ha aumentado drásticamente comparado con el 2019. Al probar los enlaces de navegación que usan URLs con hash, vimos un -53% de instancias de enlaces no rastreables en sitios que usan React, -58% menos en sitios creados con Vue.js, y una reducción de -91% para SPAs desarrolladas con Angular.
Asimismo, identificamos que hubo una ligera mejora respecto a los descubrimientos del año pasado en diferentes áreas analizadas:
-
robots.txt: El año pasado 72.16% de los sitios móviles tenían unrobots.txtválido comparado con 74.91% este año. - etiqueta canonical: El año pasado identificamos que 48.34% de las páginas móviles incluían una etiqueta canonical en comparación con 53.61% este año.
-
etiqueta
title: Este año encontramos que 98.75% de las páginas de escritorio incluyen esta etiqueta, mientras que 98.7% de las páginas móviles también la incluyen. El año pasado se encontró que 97.1% de las páginas móviles tenían una etiquetatitle. -
metadescripción: Este año, encontramos que 68.62% de las páginas de escritorio y 68.22% de las páginas móviles incluían unametadescripción, una mejora respecto al año pasado donde 64.02% de las páginas móviles tenían una. - datos estructurados: A pesar de que las reseñas no deben asociarse con páginas de inicio, los datos indican que hay un aumento en
AggregateRatingde 23.9% en móvil y 23.7% en escritorio. - uso de HTTPS: 77.44% de las páginas de escritorio y 73.22% de las páginas móviles han adoptado HTTPS. Esto es un aumento de 10.38% respecto al año pasado.
Sin embargo, no todo ha mejorado desde el año pasado. En promedio, las páginas de escritorio incluyen 61 enlaces internos, mientras que el promedio en páginas móviles es de 54. Esto es una reducción del 12.8% y 10% respectivamente comparado con el año pasado, lo que sugiere que los sitios no están aprovechando la habilidad de mejorar el rastreo y el flujo de la equidad de enlaces a través de sus páginas.
También es importante mencionar que aún hay una importante oportunidad de mejora en varias áreas y configuraciones SEO críticas. A pesar del incremento en el uso de dispositivos móviles y la migración de Google a un índice móvil primero:
- 10.84% de las páginas móviles y 16.18% de las páginas de escritorio no incluyen una etiqueta
viewport, lo que sugiere que aún no son compatibles con dispositivos móviles. - Se encontraron disparidades importantes entre las páginas de escritorio y móvil, como la disparidad entre enlaces móviles y de escritorio, representado en los 62 enlaces en móvil frente a 68 enlaces en escritorio para el promedio de las páginas web.
- 33.13% de los sitios web obtuvieron una Buena calificación de los Core Web Vitals para escritorio, mientras que solo 19.96% de sus contrapartes móviles aprobaron la validación de los Core Web Vitals, lo que sugiere que escritorio sigue siendo la plataforma con mayor rendimiento para los usuarios.
Estos hallazgos pueden impactar negativamente a los sitios conforme Google termina su migración hacia un índice móvil primero en Marzo de 2021.
También se encontraron disparidades entre el HTML renderizado y no renderizado. Por ejemplo, en promedio, la página web móvil incluye 11.5% más palabras cuando es renderizada que en su HTML puro, indicando una dependencia en JavaScript del lado del cliente para mostrar contenido.
Los rastreadores de búsqueda buscan etiquetas <a href> para encontrar páginas enlazadas. Sin ellas, la página se percibe como aislada sin enlaces internos. 5.59% de las páginas de escritorio no contenían enlaces internos asó como el 6.04% de las páginas móviles renderizadas.
Estos descubrimientos sugieren que los motores de búsqueda están continuamente evolucionando su capacidad de rastrear, indexar y posicionar sitios web más efectivamente, y algunas de las configuraciones SEO más importantes ahora se toman en cuenta de mejor manera.
Sin embargo, muchos sitios en la web aún están desaprovechando la importante visibilidad orgánica y oportunidades de crecimiento, que también muestra la persistente necesidad de evangelización SEO y la adopción de las buenas prácticas en las organizaciones.


