Balisage Web
Introduction
En 2005, Ian “Hixie” Hickson a publié une analyse sur les données de balisage web à partir de différents travaux précédents. Une grande partie de ce travail visait à examiner les noms de classes pour voir s’il existait une sémantique informelle commune adoptée par les développeurs et développeuses, sur laquelle il serait peut-être logique de standardiser. Certaines de ses recherches ont permis de proposer de nouveaux éléments en HTML5.
14 ans plus tard, il est temps de jeter un nouveau coup d’œil aux usages. Depuis cette époque, nous avons vu apparaître les éléments personnalisés et l’Extensible Web manifesto, ce qui nous a encouragé à trouver de meilleures méthodes pour accompagner les développements. Cela implique de permettre aux équipes de développement d’explorer l’espace des éléments de balisage elles-mêmes et aux organismes de normalisation d’agir comme des éditeurs de dictionnaires. À l’inverse des noms de classes CSS, qui peuvent être utilisés pour n’importe quoi, nous pouvons être certains que les auteurs qui ont utilisé un élément non standard l’ont fait volontairement.
À partir de juillet 2019, HTTP Archive a commencé à collecter tous les noms de éléments utilisés dans le DOM, environ 4,4 millions de pages d’accueil pour ordinateurs de bureau et environ 5,3 millions de pages d’accueil sur mobiles que nous pouvons maintenant commencer à analyser et à disséquer (en savoir plus sur notre méthodologie).
Lors de cette collecte, nous avons découvert plus de 5 000 noms d’éléments non standard distincts dans les pages. Nous avons donc limité le nombre total d’éléments distincts que nous comptons aux 5 048 “premiers” (explications ci-dessous).
Méthodologie
Les noms des éléments sur chaque page ont été collectés à partir du DOM lui-même, après l’exécution initiale de JavaScript.
Examiner un nombre de fréquences brut n’est pas particulièrement utile, même pour les éléments standards : environ 25 % des éléments rencontrés sont des <div>. Environ 17 % sont des <a>, environ 11 % sont des <span> – et ce sont les seuls éléments qui comptent pour plus de 10 % des occurrences. C’est un peu comme ça dans toutes les langues ; un petit nombre de termes est surreprésenté en termes de fréquence. D’autant plus que, si nous commençons à examiner l’adoption des éléments non standards, cela peut être très trompeur. Il suffirait qu’un site utilise un certain élément mille fois pour lui conférer artificiellement une grande popularité.
Au lieu de faire ça, nous allons examiner combien de sites incluent chaque élément au moins une fois dans leur page d’accueil, comme dans l’étude originale de Hixie.
Principaux éléments de balisage et généralités
En 2005, l’enquête de Hixie a listé les principaux éléments les plus fréquemment utilisés sur les pages. Les 3 premiers étaient html, head et body, ce qu’il a noté comme intéressant, car ils sont facultatifs et créés par l’analyseur s’ils sont omis. Étant donné que nous utilisons le DOM après interprétation, ils apparaissent universellement dans nos données. C’est pourquoi nous commencerons par le 4e élément le plus utilisé. Vous trouverez ci-dessous une comparaison des données collectées à son époque et aujourd’hui (j’ai inclus ici la comparaison en fréquence, pour le plaisir).
| 2005 (par site) | 2019 (par site) | 2019 (fréquence) |
|---|---|---|
| title | title | div |
| a | meta | a |
| img | a | span |
| meta | div | li |
| br | link | img |
| table | script | script |
| td | img | p |
| tr | span | option |
Éléments par page
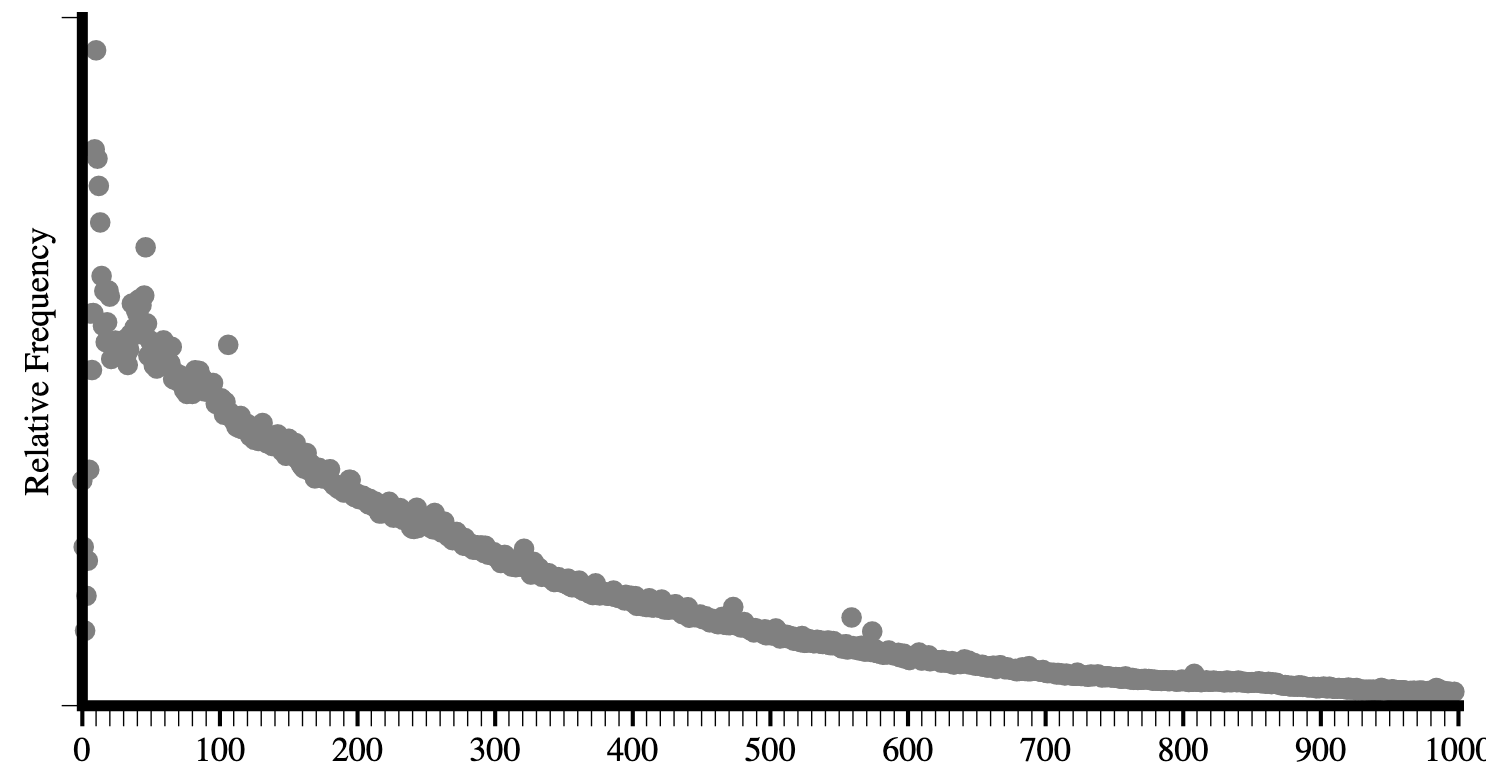
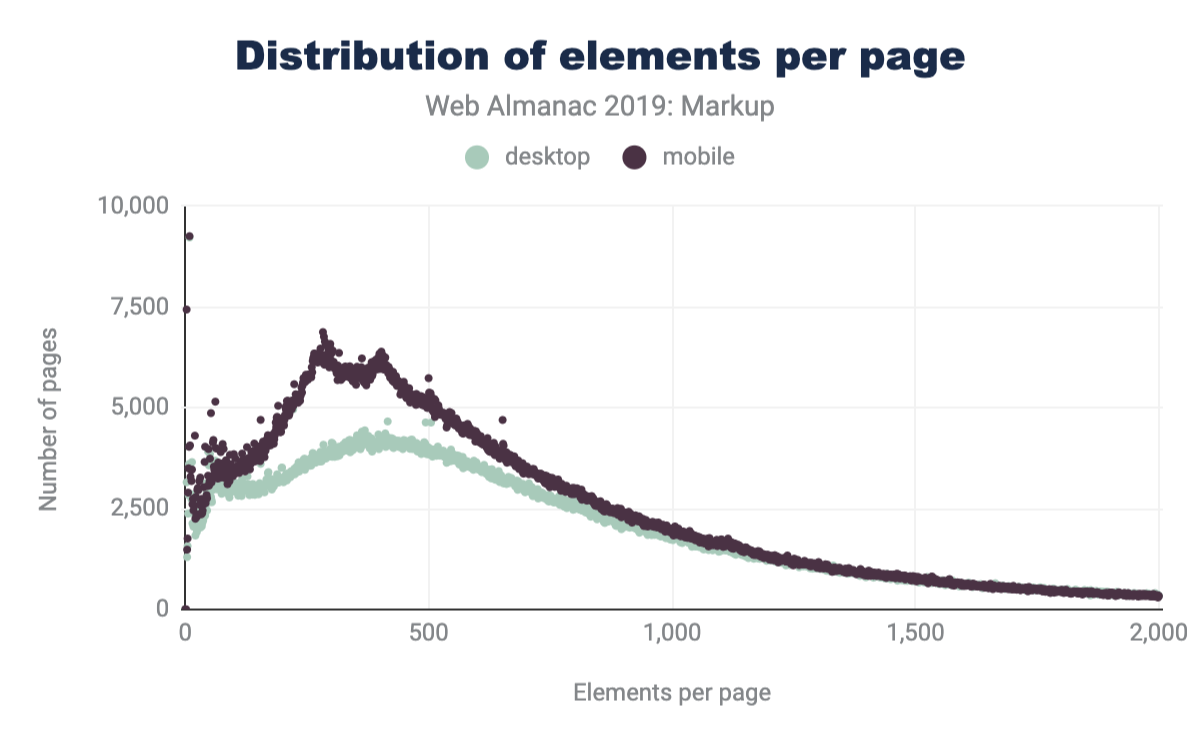
En comparant les dernières données de la figure 3.3 à celles du rapport d’Hixie de 2005 à la figure 3.2, nous pouvons constater que la taille moyenne des arbres DOM a augmenté.
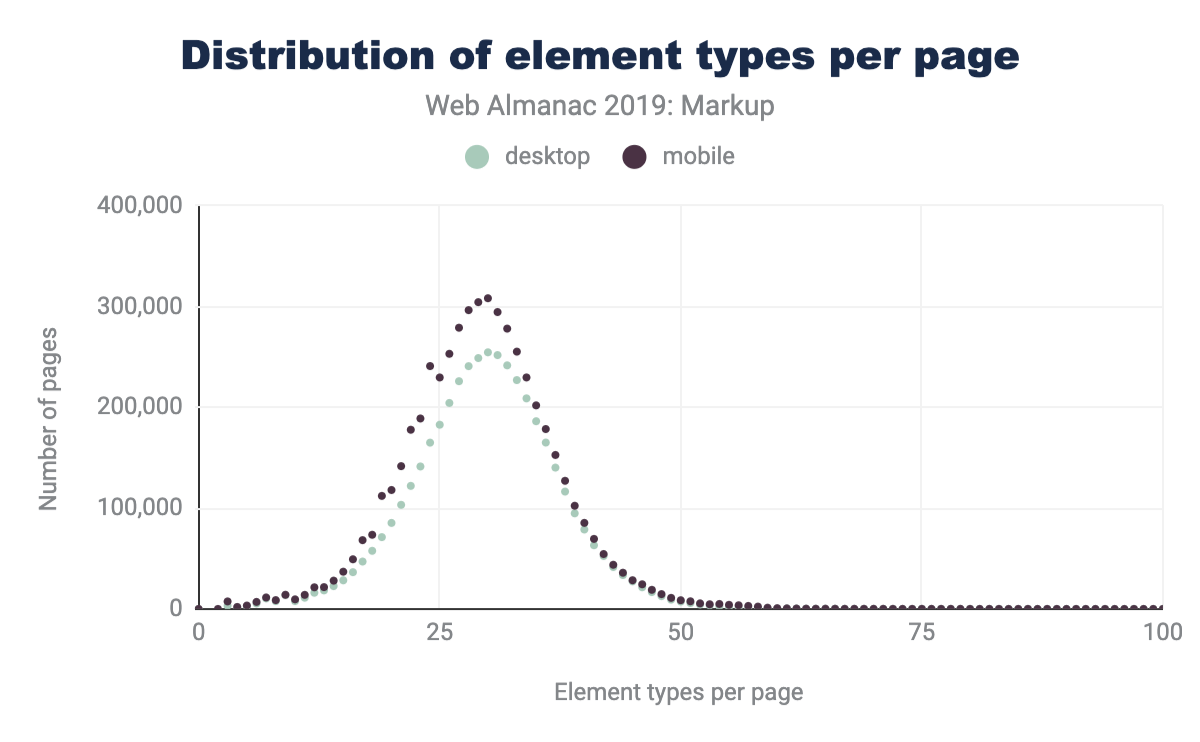
Nous pouvons voir sur les deux graphiques que le nombre moyen de types d’éléments par page a augmenté, ainsi que le nombre maximal d’éléments uniques rencontrés.
Éléments personnalisés
La plupart des éléments que nous avons enregistrés sont personnalisés (c’est-à-dire non standards), mais il peut être un peu difficile de déterminer quels éléments sont vraiment personnalisés ou non. Car il existe de nombreux élément en cours de spécification ou de proposition. Dans notre démarche, nous avons considéré 244 éléments comme standards (cependant, certains d’entre eux sont obsolètes ou non supporté) :
- 145 éléments HTML ;
- 68 éléments SVG ;
- 31 éléments MathML.
En pratique, nous n’avons rencontré que 214 d’entre eux:
- 137 Éléments de HTML ;
- 54 Éléments de SVG ;
- 23 Éléments de MathML.
Dans le jeu de données pour ordinateurs de bureau, nous avons collecté des données pour les premiers 4 834 éléments non standards rencontrés. Parmi ceux-ci:
- 155 (3 %) sont identifiables comme de très probables erreurs de balisage ou d’échappement (ils contiennent des caractères dans le nom de balise analysé qui laissent à penser que le balisage est cassé) ;
- 341 (7 %) utilisent un espace de nom de type XML à deux-points (bien que, comme HTML, ils n’utilisent pas de véritables espaces de noms XML) ;
- 3 207 (66 %) sont des noms d’élément personnalisé valides ;
-
1 211 (25 %) sont dans l’espace de noms global (ce qui n’est pas standard, puisqu’ils n’ont ni tiret ni deux-points) ;
- 216 parmi ceux-ci ont été marqués comme de possibles fautes de frappe, car ils sont plus longs que 2 caractères et ont une distance de Levenshtein de 1 par rapport à un nom d’élément standard comme
<cript>,<spsn>ou<artice>. Certains d’entre eux (comme<jdiv>), cependant, sont certainement volontaires.
- 216 parmi ceux-ci ont été marqués comme de possibles fautes de frappe, car ils sont plus longs que 2 caractères et ont une distance de Levenshtein de 1 par rapport à un nom d’élément standard comme
En outre, 15 % des pages pour ordinateurs de bureau et 16 % des pages mobiles contiennent des éléments obsolètes.
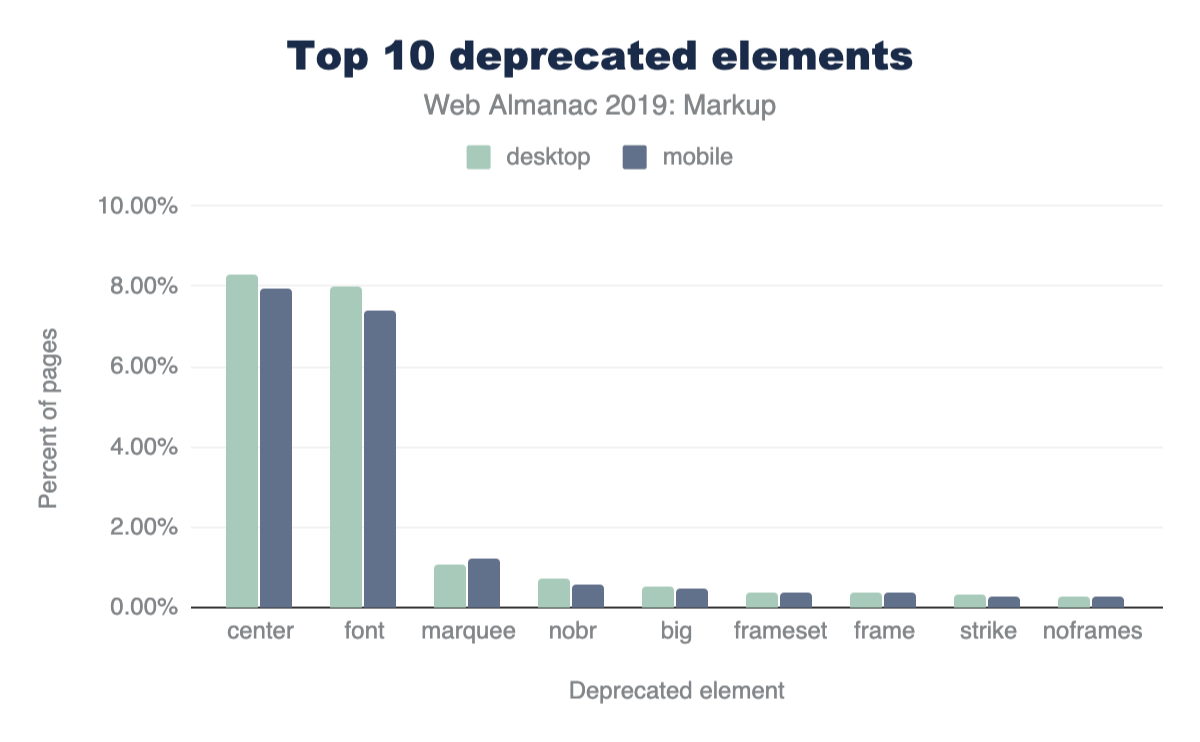
La figure 3.6 ci-dessus montre les 10 éléments les plus fréquemment utilisés. Dans la plupart des cas, les nombres peuvent sembler petits mais dans l’ensemble, ce n’est pas négligeable.
Mise en perspective des valeurs et des usages
Afin de discuter des chiffres sur l’utilisation d’éléments (standards, obsolètes ou personnalisés), nous devons d’abord prendre un peu de recul.
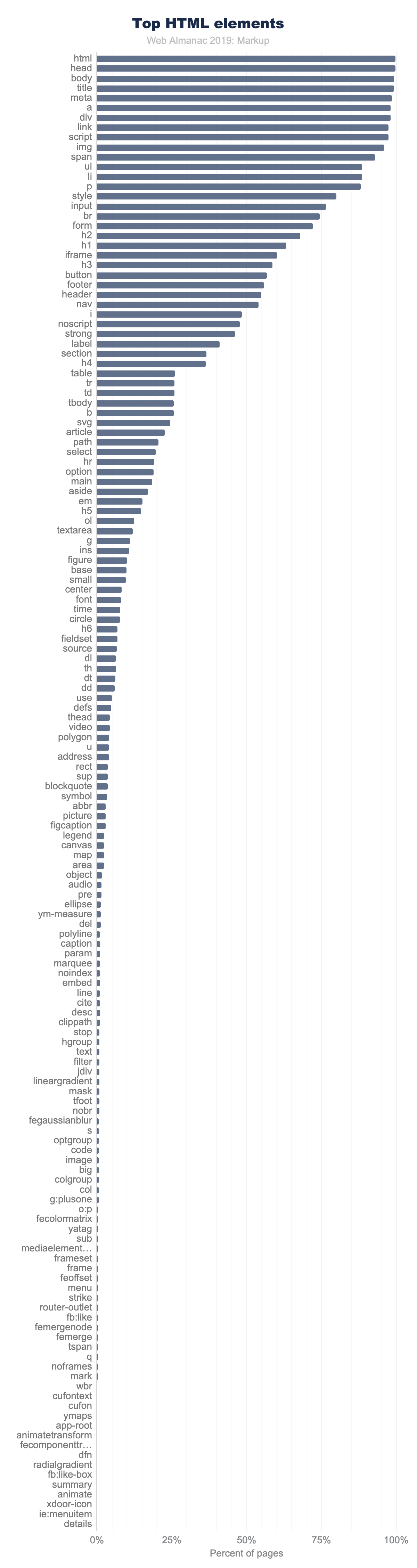
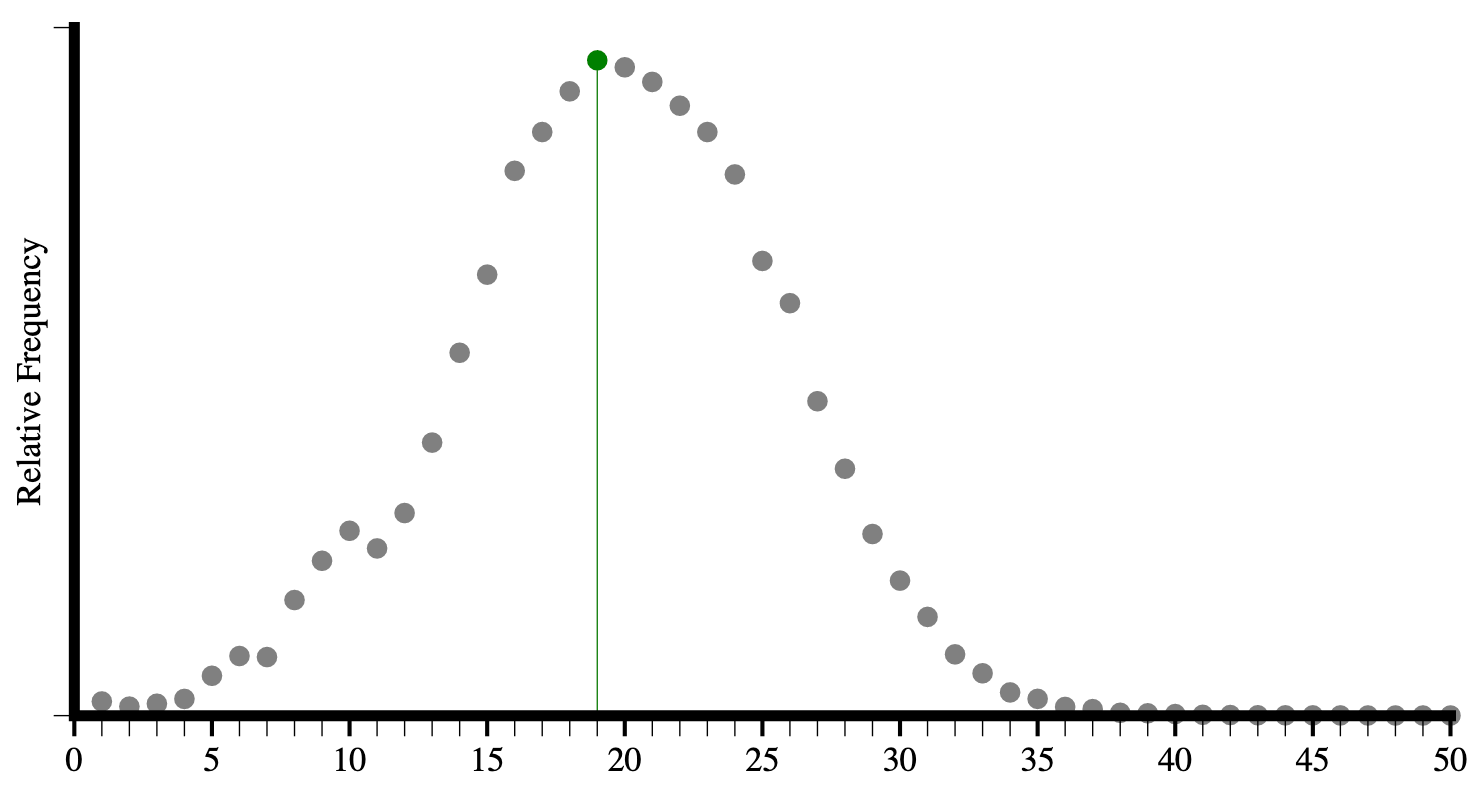
Dans la figure 3.7 ci-dessus, sont affichés les 150 premiers noms d’éléments, en comptant le nombre de pages où ils apparaissent. Notez la rapidité avec laquelle l’utilisation diminue.
Seuls 11 éléments sont utilisés sur plus de 90 % des pages:
<html><head><body><title><meta><a><div><link><script><img><span>
Il n’y a que 15 autres éléments qui apparaissent sur plus de 50 % des pages:
<ul><li><p><style><input><br><form><h2><h1><iframe><h3><button><footer><header><nav>
Et il n’y a que 40 autres éléments qui apparaissent sur plus de 5 % des pages.
Même <video>, par exemple, n’atteint pas ce score. Il apparaît sur seulement 4 % des pages pour ordinateurs de bureau du jeu de données (3 % sur mobile). Bien que ces chiffres semblent très faibles, 4 % correspond à une utilisation assez populaires, comparativement. En effet, seuls 98 éléments apparaissent sur plus de 1 % des pages.
Il est donc intéressant de voir à quoi ressemble la distribution de ces éléments et quels sont ceux qui sont utilisés à plus de 1 %.
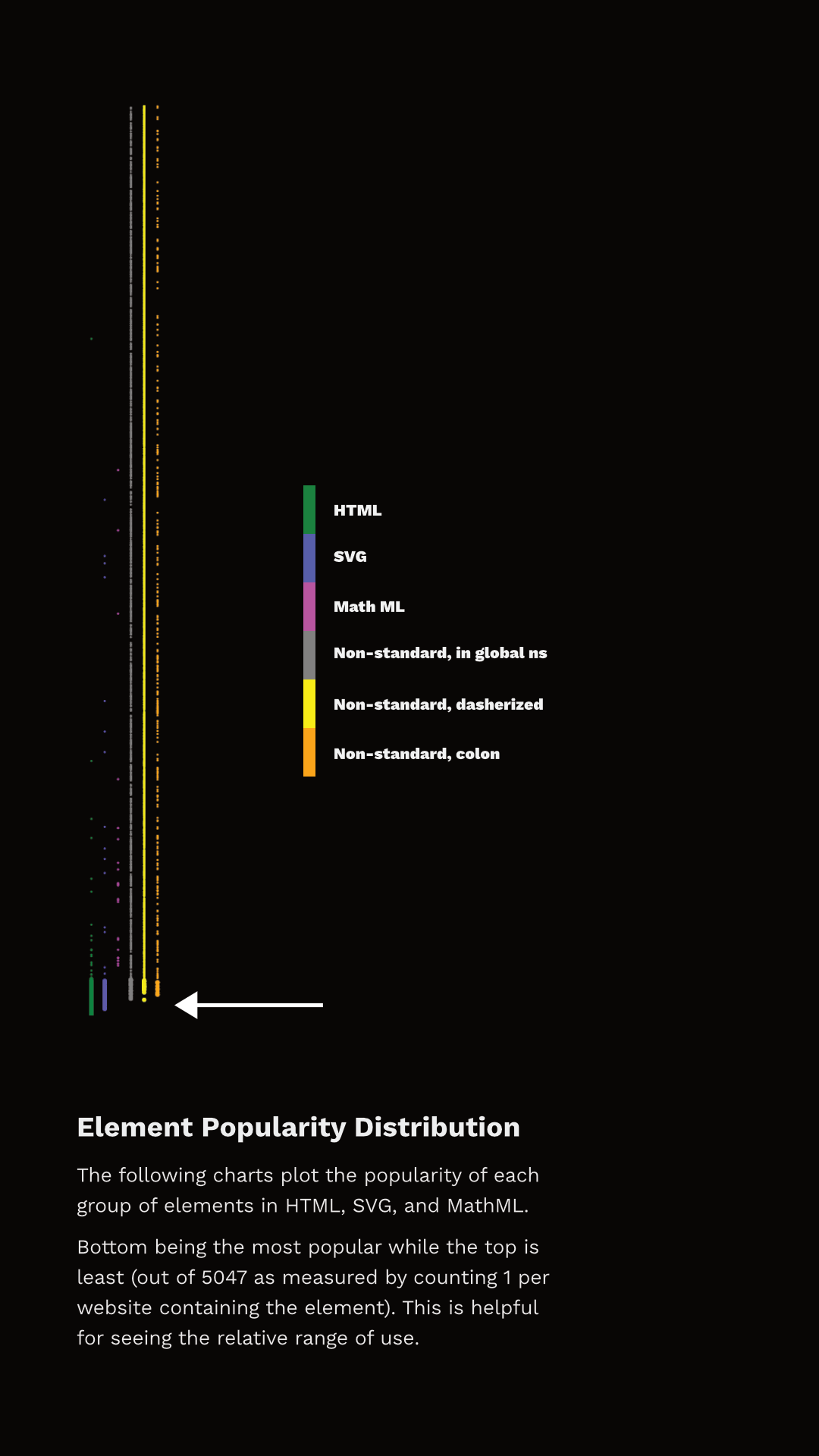
La figure 3.8 montre le classement de chaque élément et la norme dans laquelle il se situe. J’ai séparé les points de données en ensembles discrets simplement pour pouvoir les visualiser (sinon, il n’ya tout simplement pas assez de pixels pour capturer toutes ces données), mais ils représentent une unique “ligne” de popularité ; le plus bas étant le plus commun, le plus haut étant le plus rare. La flèche pointe vers la fin des éléments qui apparaissent dans plus de 1 % des pages.
Vous pouvez observer deux choses ici. Premièrement, l’ensemble des éléments utilisés à plus de 1 % n’est pas exclusivement HTML. En fait, 27 des 100 éléments les plus populaires ne sont même pas issus de HTML – ils sont en SVG ! Et il y a aussi des balises non standards au niveau ou très près de cette démarcation! Deuxièmement, notez que de nombreux éléments HTML sont utilisés par moins de 1 % des pages.
Alors, tous ces éléments utilisés par moins de 1 % des pages sont-ils “inutiles”? Définitivement, non. C’est pourquoi il est important de prendre du recul. Il y a environ deux milliards de sites sur le Web. Si quelque chose apparaît sur 0,1 % de tous les sites web de notre ensemble de données, nous pouvons extrapoler que cela représente peut-être deux millions de sites web sur l’ensemble du web. Même 0,01 % extrapolent à deux cent mille sites. C’est aussi pourquoi il est très rare qu’on supprime le support d’éléments, même les très anciens, dont nous considérons l’usage comme une mauvaise pratique. Briser des centaines de milliers ou des millions de sites n’est pas une chose que les éditeurs de navigateurs peuvent faire à la légère.
De nombreux éléments, même natifs, apparaissent sur moins de 1 % des pages et restent très importants et prospères. <code>, par exemple, est un élément que j’utilise et rencontre souvent. Il est très certainement utile et important, et pourtant, il n’est utilisé que sur 0,57 % des pages. Tout ça est en partie faussé par ce que nous mesurons : les pages d’accueil sont généralement moins susceptibles d’inclure certains types d’éléments (comme <code>, par exemple). Les pages d’accueil n’ont pas vocation à accueillir autre chose que des en-têtes, des paragraphes, des liens et des listes. Cependant, les données sont généralement utiles.
Nous avons également collecté des informations sur les pages contenant un .shadowRoot défini par l’auteur (non natif). Environ 0,22 % des pages pour ordinateurs de bureau et 0,15 % des pages mobiles avaient un shadow dom. Cela peut sembler peu, mais il s’agit d’environ 6,5k sites dans le jeu de données mobile et de 10k sites pour ordinateurs de bureau et représente plus que plusieurs éléments HTML. <summary> par exemple, est à peu près autant utilisé sur les ordinateurs et est le 146e élément le plus populaire. <datalist> apparaît sur 0,04 % des pages d’accueil et constitue le 201e élément le plus populaire.
En fait, plus de 15 % des éléments que nous comptons, tels que définis par HTLM, sont en dehors des 200 premiers de l’ensemble de données de bureau. <meter> est l’élément le moins populaire de “l’ère HTML5”, que nous pouvons définir comme 2004-2011, avant que HTML ne devienne un Living Standard. Il se situe autour du 1 000e élément le plus populaire. <slot>, l’élément le plus récemment introduit (avril 2016), est seulement autour du 1 400e élément le plus populaire.
Beaucoup de données : le vrai DOM du vrai web
En gardant à l’esprit cette perspective sur l’utilisation des fonctionnalités natives / standard dans le jeu de données, parlons des éléments non standards.
Vous pourriez vous attendre à ce que beaucoup des éléments que nous avons analysés ne soient utilisés que sur une seule page web. En fait, les 5 048 éléments apparaissent tous sur plus d’une page. Le nombre de pages sur lesquelles un élément de notre ensemble de données apparaît est de 15 au minimum. Environ un cinquième d’entre eux apparaissent sur plus de 100 pages. Environ 7 % d’entre eux apparaissent sur plus de 1 000 pages.
Pour aider à analyser les données, j’ai bidouillé un petit outil avec Glitch. Vous pouvez utiliser cet outil vous-même et envoyer un lien permanent à @HTTPArchive avec vos observations. (Tommy Hodgins a également construit un outil CLI similaire que vous pouvez utiliser pour explorer les données).
Jetons un coup d’oeil à quelques données.
Solutions (et bibliothèques) et leurs balises personnalisées
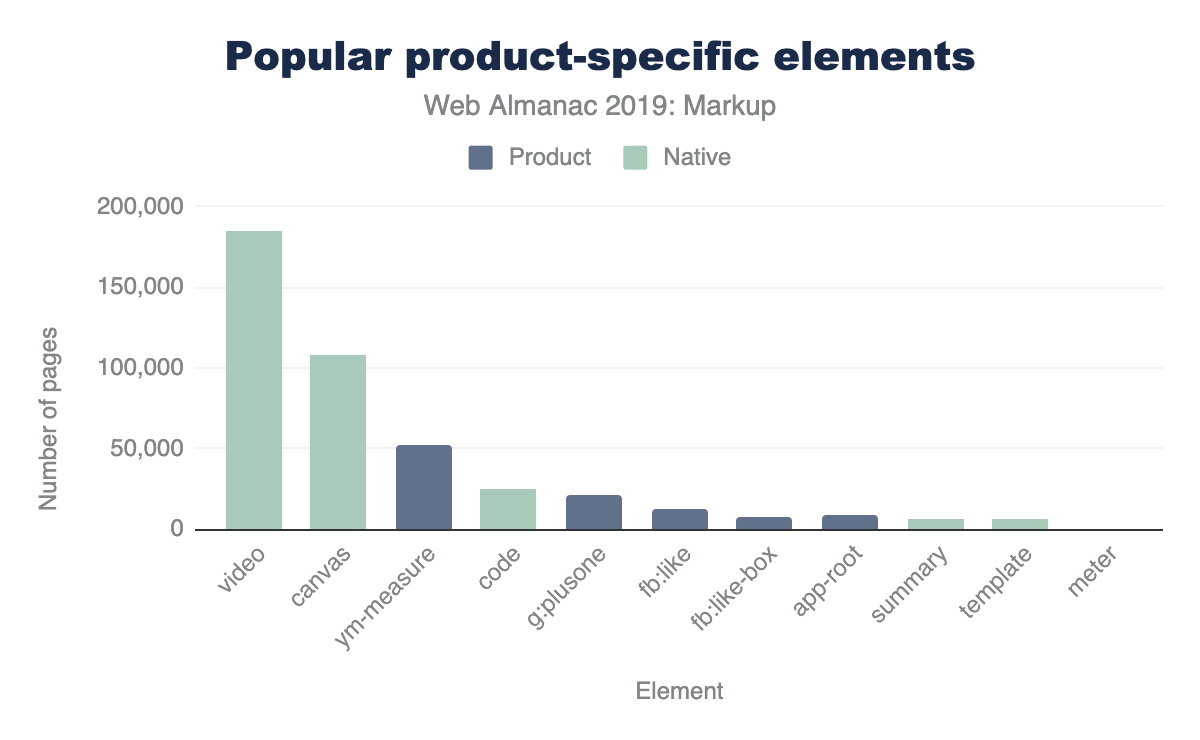
La prévalence de plusieurs éléments non standards est sûrement plus liée à leur inclusion dans des outils tiers populaires qu’à leur adoption par les équipes de développement. Par exemple, l’élément <fb:like> se trouve sur 0,3 % des pages ; non pas parce que les propriétaires du site l’écrivent explicitement, mais parce qu’ils incluent le widget Facebook. Beaucoup d’éléments mentionnés par Hixie il y a 14 ans apparaitre moins fréquemment, mais d’autres sont encore assez récurrents :
-
Des éléments populaires créés par la Page d’accueil Claris (dont la dernière version stable date d’il y a 21 ans) sont encore affichés sur plus de 100 pages.
<x-claris-window>, par exemple, apparaît sur 130 pages. -
Certains éléments
<actinic:*>du fournisseur britannique de commerce électronique Oxatis apparaissent sur plus de pages encore. Par exemple,<actinic:basehref>s’affiche toujours sur 154 pages dans les données issues des pages pour ordinateur de bureau. -
Les éléments de Macromedia semblent avoir, en grande partie, disparus. Un seul élément,
<mm:endlock>, apparaît sur notre liste et sur 22 pages seulement. -
L’élément
<csscriptdict>d’Adobe Go-Live apparaît toujours sur 640 pages pour ordinateur de bureau. - L’élément
<o:p>de Microsoft Office apparaît toujours sur 0,5 % des pages pour ordinateur de bureau, soit plus de 20 000 pages.
Mais beaucoup de nouveaux arrivants ne figuraient pas non plus dans le rapport initial d’Hixie, et avec des chiffres plus importants.
-
<ym-measure>est une balise injectée par le paquet de télémétrie Metrica de Yandex. Il est utilisé sur plus de 1 % des pages d’ordinateur et mobiles, consolidant ainsi sa place dans le top 100 des éléments les plus utilisés. C’est énorme ! -
<g:plusone>, qui provient du défunt Google Plus, apparaît sur plus de 21k pages. -
<fb:like>de Facebook apparaît sur 14k pages mobiles. -
De même,
<fb:like-box>apparaît sur 7,8k pages mobiles. -
<app-root>, qui est généralement inclus dans des systèmes comme Angular, apparaît sur 8,2k pages mobiles.
Comparons-les à quelques-uns des éléments HTML natifs inférieurs à la barre des 5 %, en perspective.
Vous pourriez découvrir des enseignements intéressants comme ceux-ci à longueur de journée.
Voici un qui est un peu différent : les élements les plus courants peuvent être causé par des erreurs flagrantes dans des solutions. Par exemple, <pclass ="ddc-font-size-large"> apparaissait sur plus de 1 000 sites. Cela était dû à un espace manquant dans une solution “as-a-Service” très connue. Heureusement, nous avons signalé cette erreur lors de notre recherche et elle a été rapidement corrigée.
Dans son article original, Hixie mentionne que:
Ce qui est bien, si l’on peut nous pardonner d’essayer de rester optimistes face à tout ce balisage non standard, c’est qu’au moins ces éléments utilisent bien des noms spécifiques aux fournisseurs. Cela réduit massivement la probabilité que les organismes de normalisation inventent des éléments et des attributs qui entrent en conflit avec l’un d’eux.
Cependant, comme mentionné ci-dessus, ce n’est pas universel. Plus de 25 % des éléments non standard que nous avons capturés n’utilisent aucune stratégie d’espace de nom afin d’éviter de polluer l’espace de noms global. Par exemple, voici une liste de 1 157 éléments issus du jeu de données mobile. Comme vous pouvez le constater, ces éléments ne poseront probablement aucun problème, car ils portent des noms obscurs, des fautes d’orthographe, etc. Mais au moins quelques-uns présentent probablement des défis. Vous remarquerez, par exemple, que <toast> (que les Googlers ont récemment essayé de proposer comme <std-toast>) apparaît dans cette liste.
Il y a certains éléments très répandus qui ne posent probablement pas de difficultés :
-
<ymaps>de Yahoo Maps apparaît sur ~12,5k pages mobiles. -
<cufon>et<cufontext>issus d’une bibliothèque de remplacement de polices datant de 2008, apparaissent environ sur ~10.5k pages sur mobiles. -
<jdiv>semble être injecté par la solution de discussion Jivo, et apparaît sur ~40,3k pages mobile.
Les placer dans le même graphique que ci-dessus donne la perspective suivante (encore une fois, elle varie légèrement en fonction de l’ensemble de données).
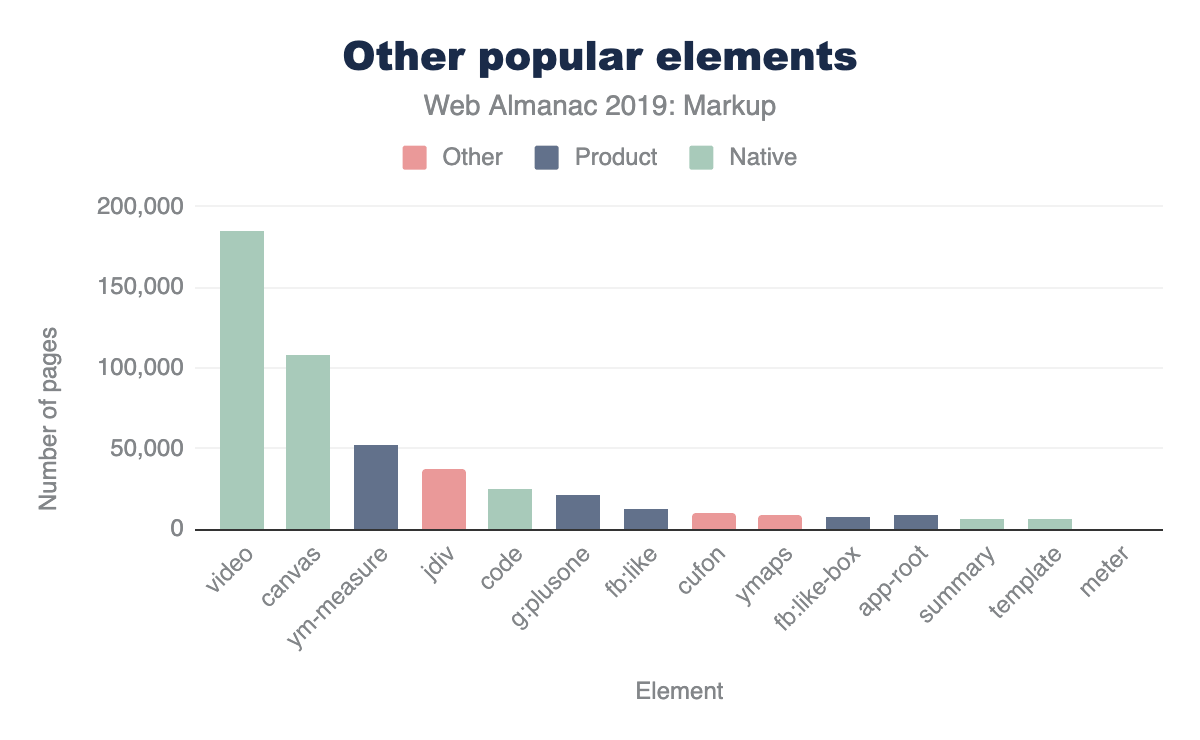
Ce qui est intéressant dans ces résultats, c’est qu’ils introduisent également quelques autres façons dont notre outil peut être très utile. Si nous voulons explorer l’espace des données, un nom de balise très spécifique n’est qu’une mesure possible. C’est certainement l’indicateur le plus fort en termes de “jargon” du développement. Cependant, que faire si ce n’est pas tout ce qui nous intéresse ?
Cas d’utilisation courants et solutions
Et si, par exemple, nous nous intéressions aux personnes qui solutionnent les cas d’utilisation courants ? Nous pourrions le faire parce que nous cherchons des solutions pour résoudre des cas existants, ou pour faire des recherches plus générales sur les situations d’utilisation courantes que les gens résolvent en vue de lancer un processus de normalisation. Prenons un exemple courant : les onglets. Au fil des ans, il y a eu beaucoup de demandes pour des choses de ce genre. Nous pouvons utiliser une recherche approximative ici et trouver qu’il y a de nombreuses variantes d’onglets. Il est un peu plus difficile de compter l’utilisation ici, car nous ne pouvons pas distinguer aussi facilement si deux éléments apparaissent sur la même page, donc le compte fourni ici de manière traditionnelle prend simplement celui avec le plus grand nombre. Dans la plupart des cas, le nombre réel de pages est probablement beaucoup plus grand.
Il y a aussi beaucoup d’accordéons, de modales de dialogues, au moins 65 variantes de carrousels, beaucoup de choses sur les popups, au moins 27 variantes d’ interrupteurs et de bascules, etc.
Nous pourrions peut-être rechercher pourquoi nous avons besoin de 92 variantes d’éléments liés à des boutons qui ne soient pas des boutons natifs, par exemple, et essayer de remplir le vide existant.
Si nous remarquons que des choses populaires apparaissent (comme <jdiv>, pour la discussion), nous pouvons prendre connaissance de choses que nous connaissons (comme, voici en quoi <jdiv> consiste, ou <olark>) et essayer de regarder les 43 éléments – au moins – que nous avons collecté et qui répondent à ce besoin et de suivre les liens entre ces éléments pour comprendre le marché.
Conclusion
Alors, il y a beaucoup de données ici, mais pour résumer :
- Les pages ont plus d’éléments qu’il y a 14 ans, en moyenne et au maximum.
- La durée de vie des éléments sur les pages d’accueil est très longue. Le fait de déprécier ou d’abandonner des éléments ne les fait pas disparaître, et cela pourrait ne jamais arriver.
- Il y a beaucoup de balises erronées dans la nature (balises mal orthographiées, espaces manquants, mauvaise échappement, méprises).
- Il est difficile de mesurer ce que signifie “utile”. Beaucoup d’éléments natifs ne passent pas la barre des 5%, ou même celle des 1%, mais beaucoup d’éléments personnalisés le font, et pour beaucoup de raisons. Passer le 1% devrait certainement attirer notre attention, mais peut-être aussi le 0.5% parce que c’est, selon les données, comparativement très populaire.
- Il y a déjà une tonne de balisage personnalisé sur le marché. Il y en a de toutes les formes, mais les éléments contenant un tiret semblent définitivement avoir décollé.
- Nous devons de plus en plus étudier ces données et faire de bonnes observations pour identifier les pratiques et standardiser.
C’est dans ce dernier cas que vous intervenez. Nous aimerions profiter de la créativité et de la curiosité de la communauté pour aider à explorer ces données en utilisant certains des outils (comme https://rainy-periwinkle.glitch.me/). Veuillez nous faire part de vos précieuses observations et nous aider à bâtir notre patrimoine commun de connaissances et de compréhension.
